HDFS概述
- HDFS的功能與應用場景
- 功能
- 程序
- 應用場景
- HDFS的分塊與副本機制
- 分塊機制
- 副本機制
- 主從架構
- Client功能
- NameNode功能
- DataNode功能
- 資料寫入流程
- 資料讀取流程
- 啟動方式
- 單行程訪問
- 分類啟動
- 全部啟動
- 檔案管理命令
- Client
- 格式
- 列舉
- 上傳
- 下載
- 洗掉
- 創建目錄
- 查看
- 其它
- 集群管理命令
- Client
- 集群狀態
- 安全模式
Hadoop概述
HDFS的功能與應用場景
功能
實作分布式檔案存盤,提供分布式檔案讀寫,
程序
分:將一個大的檔案拆分為多個小的部分(block塊,默認為128M),將塊儲存在不同的節點上,
合:讀取時將所有塊進行合并,回傳給用戶,
HDFS存盤的是塊,而用戶操作的是檔案,NameNode存盤了元資料(記錄檔案和塊的映射關系),
應用場景
不同的存盤需求應該用不同的框架來實作,
HDFS要將資料儲存到硬碟,速度不快,且塊128M,顯然:
HDFS適合:存盤大資料量檔案的場景;離線的場景、延遲性要求不高的場景;讀寫速度要求不高的場景;一次寫入,多次讀取的場景,
HDFS不適合:一條資料一條資料存盤的場景(更適合使用資料庫);讀寫速度要求較高的場景(更適合使用分布式硬碟、記憶體存盤);頻繁修改的場景(更適合使用記憶體存盤),
HDFS的分塊與副本機制
分塊機制
功能:用于實作分布式,將大檔案拆分成為多個小的塊,
塊的大小是按照檔案大小劃分的,由屬性決定,
在Hadoop官網:
查找組態檔,可以看到很多驚天大秘密,,,
HDFS默認配置有寫:
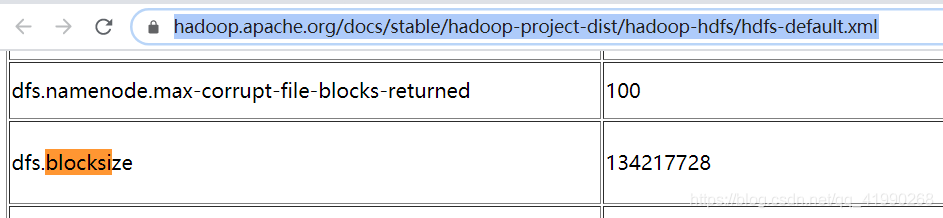
換算出來Block塊的大小就是128M,
或者去組態檔里也能找到類似的內容:
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
默認就是128M為一塊,如果不足128M就會按實際大小存盤,
副本機制
HDFS的副本機制很像NAS機常用的raid1(raid0是類似雙通道記憶體那樣提速用的,raid1是2塊硬碟記錄完全相同的內容以確保資料的安全性),
功能:為了保證資料塊的安全,HDFS會為每個塊構建副本,存盤多份相同的內容,
HDFS的演算法會自動將每個塊復制多份,盡量存盤在不同的機器上(也是由配置決定),
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
可以看出默認配置是每個塊存盤3份,(銀行的異地容災一般也是備份3份),
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/server/hadoop-2.7.5/hadoopDatas/datanodeDatas</value>
</property>
HDFS中資料會儲存在這個位置,由于筆者是3臺虛擬機搭的集群,默認又是保存3份,故每個節點的該位置都會保存一套完整的資料,
在這個位置可以看到存盤的檔案被切成了2塊128M和一塊不足128M的內容,
主從架構
用戶通過Client訪問分布式服務HDFS的NameNode行程,NameNode行程會將需要存盤的檔案切分為128M的Block并將任務下發給DataNode行程,而用于記錄分片映射關系(檔案被切成幾塊、每塊的位置)的元資料會由NameNode保存,
Client功能
Client是介于用戶和Server之間的,用戶操作客戶端向服務端提交請求需要經過客戶端,客戶端供用戶開發命令/代碼,并將命令提交給服務端執行,還能將服務端運行的結果回傳給用戶,
NameNode功能
管理節點,同一時間只能有1個處于作業狀態,
管理所有DataNode的狀態(死活):通過心跳機制(所有的DataNode定期向NameNode發送心跳信號,如果NameNode長時間沒有接收到心跳,就會判定為DataNode故障,網路狀態不良時可能判作不健康),
管理所有資料的安全(檢查資料是否有丟失):通過匯報塊機制(所有的DataNode會定期向NameNode匯報當前自己機器上所存盤的資料塊的情況,NameNode將每個DataNode匯報的資訊與元資料進行比較,判斷是否有資料丟失),
管理元資料:NameNode管理的元資料都在記憶體中,所有資料的更新都是在記憶體中進行操作,為了掉電不丟失,也會在硬碟中存盤快照(
由于在組態檔中寫過:
<property> <name>dfs.namenode.name.dir</name> <value>file:///export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas</value> </property>
在該目錄下的current里有個fsimage檔案,這貨就是存盤在硬碟中的快照,每次NameNode啟動會從fsimage檔案中加載所有元資料到記憶體中,所有元資料更新都只更新記憶體元資料,快照的更新是借助SecondaryNameNode),
接收客戶端的讀寫請求:所有的HDFS客戶端想要實作讀寫請求,必須指定NameNode的地址8020(組態檔中有寫:fs.defaultFS = hdfs://node1:8020)
DataNode功能
自身是存盤節點(存盤128M的Block資料塊),接收NameNode的管理(分發的任務),接收客戶端對塊的讀寫請求(Client事實上是直接和DataNode傳輸64KB的Socket包的),
資料寫入流程
客戶端會請求NameNode寫入HDFS,NameNode會驗證請求是否合法并回傳結果(NameNode驗證寫入的檔案是否存在、有沒有權限寫入等,如果不合法,直接拒絕請求)
NameNode回傳對應的結果,構建這個檔案的元資料,此時并沒有跟塊關聯,
客戶端提交第一個塊的寫入請求給NameNode,
NameNode根據每個DN的健康狀態以及負載情況回傳三臺DataNode的地址,根據機架感知的分配規則,客戶端所在的機架會存放一份,另外2份存盤在另外的機架(老版本為了速度,會將2份存盤在靠近客戶端的機架,新版本是降低了速度,提高了機架的容錯),
客戶端得到要寫入資料塊的三臺DataNode地址,客戶端會連接第一臺(由機架感知決定,node1最近),提交寫入,
三臺DataNode構建一個資料傳輸的管道,
客戶端將這個塊拆分成多個packet【64k】,挨個發送個最近的DataNode1,
逐級回傳寫入成功的ack確認碼,表示這個包寫入完成(從硬體集群的機架內、機架間對拷硬碟比重新從客戶端接收更高效,且客戶端只需要傳輸一次,體驗更好),
不斷發送下一個包,直到整個塊寫入完成,回傳給NameNode,關聯元資料,
重復提交下一個塊的寫入,
資料讀取流程
啟動方式
單行程訪問
每條命令只啟動一個行程,一般用于特殊場景,
啟動HDFS:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
啟動YARN:
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
分類啟動
最常用,一條命令可以啟動一類行程,
啟動HDFS(NameNode的機器):
start-dfs.sh
stop-dfs.sh
啟動YARN(ResourceManager的機器):
start-yarn.sh
stop-yarn.sh
全部啟動
start-all.sh
操作不可控,一般不用,
檔案管理命令
Client
所有能對HDFS進行讀寫的命令/程式,都可以作為HDFS的客戶端,HDFS中提供了自帶的命令客戶端,
bin/hdfs
hdfs
Usage: hdfs [--config confdir] [--loglevel loglevel] COMMAND
where COMMAND is one of:
dfs run a filesystem command on the file systems supported in Hadoop.
classpath prints the classpath
namenode -format format the DFS filesystem
secondarynamenode run the DFS secondary namenode
namenode run the DFS namenode
journalnode run the DFS journalnode
zkfc run the ZK Failover Controller daemon
datanode run a DFS datanode
dfsadmin run a DFS admin client
haadmin run a DFS HA admin client
fsck run a DFS filesystem checking utility
balancer run a cluster balancing utility
jmxget get JMX exported values from NameNode or DataNode.
mover run a utility to move block replicas across
storage types
oiv apply the offline fsimage viewer to an fsimage
oiv_legacy apply the offline fsimage viewer to an legacy fsimage
oev apply the offline edits viewer to an edits file
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
snapshotDiff diff two snapshots of a directory or diff the
current directory contents with a snapshot
lsSnapshottableDir list all snapshottable dirs owned by the current user
Use -help to see options
portmap run a portmap service
nfs3 run an NFS version 3 gateway
cacheadmin configure the HDFS cache
crypto configure HDFS encryption zones
storagepolicies list/get/set block storage policies
version print the version
Most commands print help when invoked w/o parameters.
可以看到有很多命令,
格式
hdfs dfs 命令 引數
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
太多了,,,
列舉
hdfs dfs -ls /
路徑必須為/開頭的絕對路徑,
當然也有相對路徑(不常用),以/user/root/開頭,
上傳
hdfs dfs -put Linux檔案地址 HDFS路徑地址
hdfs dfs -put /export/data/wordcount.txt /wordcount/input/
這是之前上傳檔案到HDFS的命令,
下載
hdfs dfs -get HDFS路徑地址 Linux檔案地址
洗掉
hdfs dfs -rm [-r|-R] [-skipTrash]
其中-r或者-R是用于遞回洗掉目錄(也就是多層的檔案夾),-skipTrash用于跳過回收站直接洗掉,不然還需要手動進入/user/root/.Trash/Current/目錄洗掉回收站,HDFS還是比較吃硬碟空間的(∵默認要保存3份),
創建目錄
hdfs dfs -mkdir [-p] 目錄路徑
其中-p是用來創建層級目錄的,
查看
hdfs dfs -cat /wordcount/input/wordcount.txt
其它
-cp
-mv
大多數命令和Linux的命令列差不多,
集群管理命令
Client
bin/hadoop command
命令也很多:
Usage: hdfs dfsadmin
Note: Administrative commands can only be run as the HDFS superuser.
[-report [-live] [-dead] [-decommissioning]]
[-safemode <enter | leave | get | wait>]
[-saveNamespace]
[-rollEdits]
[-restoreFailedStorage true|false|check]
[-refreshNodes]
[-setQuota <quota> <dirname>...<dirname>]
[-clrQuota <dirname>...<dirname>]
[-setSpaceQuota <quota> [-storageType <storagetype>] <dirname>...<dirname>]
[-clrSpaceQuota [-storageType <storagetype>] <dirname>...<dirname>]
[-finalizeUpgrade]
[-rollingUpgrade [<query|prepare|finalize>]]
[-refreshServiceAcl]
[-refreshUserToGroupsMappings]
[-refreshSuperUserGroupsConfiguration]
[-refreshCallQueue]
[-refresh <host:ipc_port> <key> [arg1..argn]
[-reconfig <datanode|...> <host:ipc_port> <start|status>]
[-printTopology]
[-refreshNamenodes datanode_host:ipc_port]
[-deleteBlockPool datanode_host:ipc_port blockpoolId [force]]
[-setBalancerBandwidth <bandwidth in bytes per second>]
[-fetchImage <local directory>]
[-allowSnapshot <snapshotDir>]
[-disallowSnapshot <snapshotDir>]
[-shutdownDatanode <datanode_host:ipc_port> [upgrade]]
[-getDatanodeInfo <datanode_host:ipc_port>]
[-metasave filename]
[-triggerBlockReport [-incremental] <datanode_host:ipc_port>]
[-help [cmd]]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
集群狀態
hdfs dfsadmin -report
安全模式
hdfs dfsadmin [-safemode <enter | leave | get | wait>]
當NameNode發現塊的丟失比例超過0.001%,就會自動進入安全模式,用于恢復對應的資料,安全模式下,HDFS集群不對外提供讀寫,如果HDFS長久的停留在安全模式,將不能正常使用,虛擬機之間關電經常出現這種問題,可以手動強制退出安全模式:
hdfs dfsadmin -safemode leave
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/280341.html
標籤:其他