如何高效簡潔的完成OushuDB與Greenplum之間資料對接
- GP集群間對接
- 方案優點
- 方案缺點
- OushuDB架構
- 如何實作
- OushuDB與GP對接
最近有專案需要做偶數云原生資料庫(后簡稱:OushuDB)與Greenplum(后簡稱:GP)之間資料對接,主要背景是客戶使用GP已經有一定歷史,很多生態都是按照GP的方式完成,OushuDB需要接入就要兼容原有的介面,這樣不僅可以快速上線,還能最小化開發成本,其中有一個需求就是打通OushuDB與GP之間的資料通道,OushuDB的結果資料可以高效簡便的匯入GP,并且要實作原有的介面,
GP集群間對接
因為本人之前做GP運維多年,所以看到需求后發現GP原有方式,是之前某GP大神的作品,作用在GP集群間做高效復制資料,在某一范圍內傳播寬泛,我們先來看看這個流程以及他的優缺點,
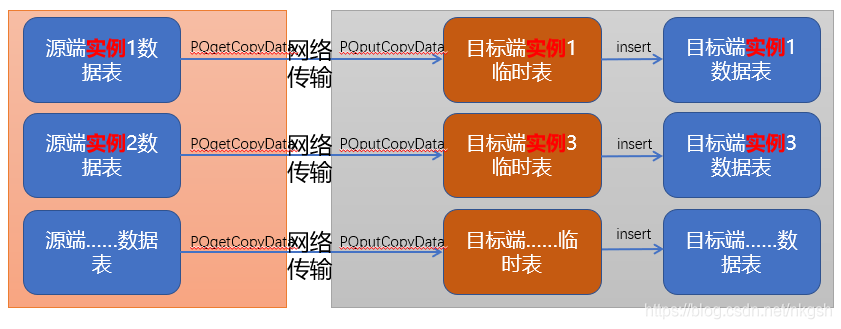
可以看到GP是通過libpq的Copy介面完成資料對導,這個方案巧妙的利用了GP實體的特性,通過UDF(資料庫自定義函式)完成分布式拷貝,當然集群間實體數的差異,只要有一個Mapping規則就行,
方案優點
1、 高效,通過分布式對接完成實體到實體的分布式操作,效率非常高效,
2、 資料不落地,完成了記憶體對拷,
3、 操作簡單,用戶通過撰寫好的UDF在資料庫內執行函式就能完成操作(存盤程序),
方案缺點
當然也有缺點:
1、 很明顯拷貝是先進入臨時表后才匯入正式表,這是因為通過這種方式對拷資料分布完全是拷貝時Mapping的分布規則,違背了表設計的分布策略,如果是Hash分布資料分布會混亂,這時候需要有一個臨時中間表(隨機策略)做一個中轉,那么這個拷貝其實還不能算真正完成,后面還要進行一步匯入,
2、 由于UDF為外部程式完成,這部分記憶體,資料庫不可能全部監管,高并發時有可能與資料庫有資源競爭
3、當然該方案的好處足以掩蓋他的劣勢,因為其他方式一樣可能帶來上述的問題并且可能更多,
OushuDB架構
好的,讓我們來看看OushuDB的架構:

OushuDB的架構主要是通過虛擬Segment計算,這樣給OushuDB帶來了巨大的優勢
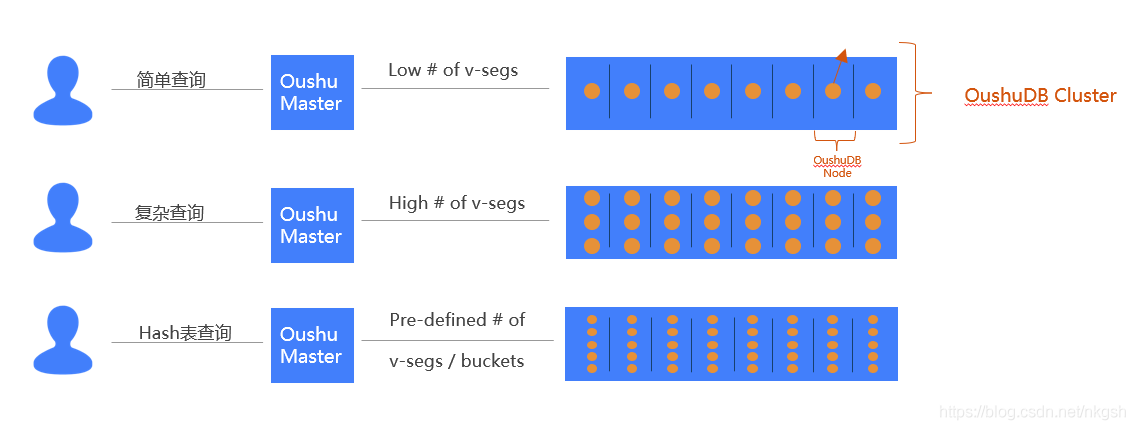
OushuDB可以動態的在系統、表、Session級別指定一個SQL的虛擬Segment數,從而更加靈活合理的開啟并行,與資源分配,這在并發情況下,有天生的架構優勢,
但是,問題來了,這樣OushuDB就很難與GP的Copy對接,因為OushuDB是動態虛擬Segment,沒辦法通過Copy取數,
如何實作
那么怎么才能完成與GP的對接呢?分析下
1、 OushuDB架構為計算與存盤分離,存盤有HDFS、MAGMA(自研)、S3等等,默認的OushuDB一定會有HDFS存盤,如果能把HDFS檔案作為第一個物件(一般OushuDB存盤會有多個HDFS檔案),一個檔案作為一個單元(相當于一個GP實體目錄),
2、 檔案確定了,那么是不是最好能使用虛擬Segment分布式操作這些檔案,并且與GP的Segment對接呢,
OushuDB與GP對接
通過上面的分析,經過大量的實驗,以及研發同事的指點,最終完成一個比較靠譜的方案,上圖:

流程說明:
1、 OushuDB將想要的結果匯入一張HDFS外表(雖然多了一步,但是由于每次匯入或許會有條件,這樣做比較安全,另外性能也不會有多少損失),
2、 匯入的HDFS外表會在HDFS上生成多個檔案,
3、 OushuDB通過WEB EXTERNAL TABLE可以指定N個虛擬Segment,通過libhdfs3分布式操作HDFS檔案,
4、 GP段保持不變,接收OushuDB的虛擬Segment的資料就行
5、 這樣就會有HDFS檔案與虛擬Segment與GP
Segment三個物體的Mapping,比GP多一個Mapping關系,也多了一步匯入到HDFS外表的操作,
最后,通過改造完全可以與GP原有介面對接,并且保證高效簡潔,當然實際可用,還需要測驗與優化,
也希望通過這個案例,能夠提供從一個角度了解OushuDB與GP架構的資料,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/280665.html
標籤:其他