前言
這個系列主要是講解關于分布式訊息中間件的一些心得
關于分布式系統、中間件是什么、訊息中間件能做什么、分布式訊息中間件長什么樣諸如此類基礎概念在上一篇文章——
分布式訊息中間件(1):Rabbitmq入門到高可用實戰!都已經講過,這里就不贅述了,感興趣的朋友可以自己去看一下,
這是本系列的第二篇,準備寫kafka,
Kakfa 廣泛應用于國內外大廠,例如 BAT、位元組跳動、美團、Netflix、Airbnb、Twitter 等等,其重要性不言而喻,
kafka與其他三個主流中間件相比,優勢有兩個:
- 性能高,每秒百萬級別;
- 分布式,高可用,水平擴展,
今天我們通過這篇文章深入了解一下 Kafka的作業原理,由于篇幅所限,肯定不會完全寫到,只能挑比較重要的幾個點來跟大家分析一下,面試題的話也不會在這篇文章里決議了,單獨整理了一份kafka學習筆記PDF以及定經典高頻面試題決議,需要的朋友可以自行領取
-
完整版kafka學習筆記
-
kafka高頻面試題
好了,話不多說,坐穩扶好,發車嘍!
一、Kafka集群搭建與使用
kafka官網圖
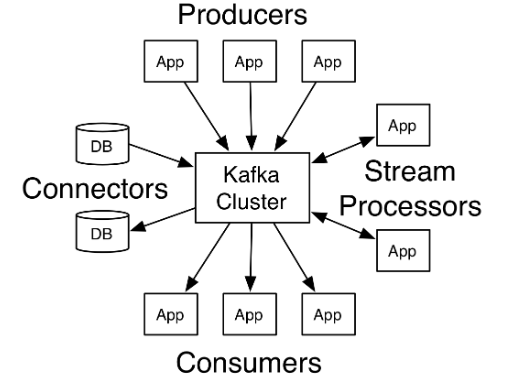
有中文官網,可以詳細看看,
地址:http://kafka.apachecn.org/intro.html

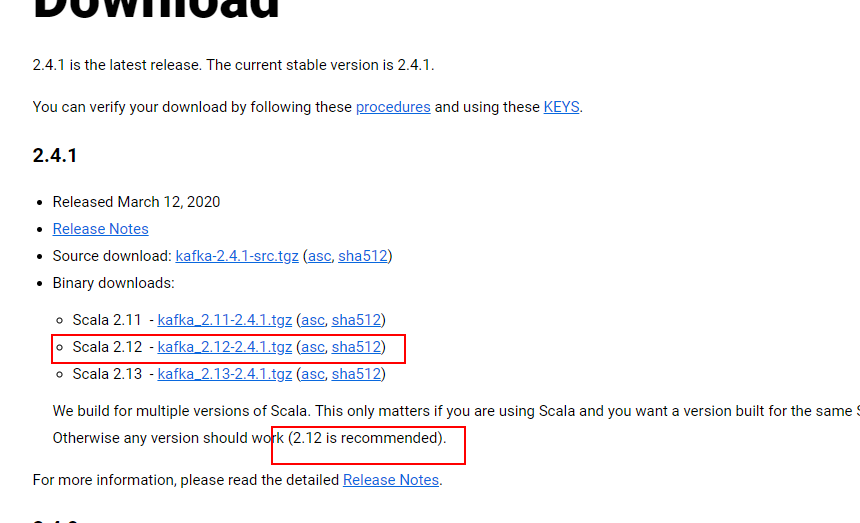
1、軟體下載
1.1 kakfa下載
地址:http://kafka.apache.org/downloads
1.2 zookeeper下載
(1)因為kafka要依賴于zookeeper做調度,kafka中實際自帶的有kafka,但是一般建議使用獨立的zookeeper,方便后續升級及公用,
(2)下載地址:
http://zookeeper.apache.org/

1.3 下載說明
檔案都不大,zk是9m多,kafka是50多兆

2、 kafka單機部署及集群部署
**說明:**北游在本地弄了三臺虛擬機,ip分別為:
192.168.85.158
192.168.85.168
192.168.85.178
2.1 單機部署
(1)上傳jar包,就不再新建用戶了,直接在root賬戶下執行,將kafka和zookeeper的tar包上傳到/root/tools目錄下,
(2)解壓
[root@ruanjianlaowang158 tools]# tar -zxvf kafka_2.12-2.4.1.tgz
[root@ruanjianlaowang158 tools]# tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
(3)配置zookeeper及啟動
[root@ruanjianlaowang158 apache-zookeeper-3.5.7-bin]# cd /root/tools/apache-zookeeper-3.5.7-bin
#北游,首先創建個空檔案夾,在接下來的組態檔中配置
[root@ruanjianlaowang158 apache-zookeeper-3.5.7-bin]# mkdir data
[root@ruanjianlaowang158 conf]# cd /root/tools/apache-zookeeper-3.5.7-bin/conf
[root@ruanjianlaowang158 conf]# cp zoo_sample.cfg zoo.cfg
[root@ruanjianlaowang158 conf]# vi zoo.cfg
#單機只改一個值,保存退出,
#dataDir=/tmp/zookeeper
dataDir=/root/tools/apache-zookeeper-3.5.7-bin/data
#啟動zookeeper
[root@ruanjianlaowang158 bin]# cd /root/tools/apache-zookeeper-3.5.7-bin/bin
[root@ruanjianlaowang158 bin]# ./zkServer.sh start
(4)配置kafka及啟動
[root@ruanjianlaowang158 kafka_2.12-2.4.1]# cd /root/tools/kafka_2.12-2.4.1
#北游,新建個空檔案夾
[root@ruanjianlaowang158 kafka_2.12-2.4.1]# mkdir data
#北游,更改組態檔
[root@ruanjianlaowang158 config]# cd /root/tools/kafka_2.12-2.4.1/config
[root@ruanjianlaowang158 config]# vi server.properties
#需要改3個值
#log.dirs=/tmp/kafka-logs
log.dirs=/root/tools/kafka_2.12-2.4.1/data
#listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://192.168.85.158:9092
#zookeeper.connect=localhost:2181
zookeeper.connect=192.168.85.158:2181
#啟動kafka
[root@ruanjianlaowang158 bin]# cd /root/tools/kafka_2.12-2.4.1/bin
[root@ruanjianlaowang158 bin]# ./zookeeper-server-start.sh ../config/server.properties &
啟動完畢,單機驗證就不驗證了,直接在集群中進行驗證,
2.2 集群部署
(1)集群方式,首先把上面的單機模式,再在192.168.85.168和192.168.85.178服務器上先解壓配置一遍,
(2)zookeeper是還是更改zoo.cfg
158,168,178三臺服務器一樣:
[root@ruanjianlaowang158 conf]# cd /root/tools/apache-zookeeper-3.5.7-bin/conf
[root@ruanjianlaowang158 conf]# vi zoo.cfg
#其他不變,最后面新加,三行,三臺服務器配置一樣,北游
server.1=192.168.85.158:2888:3888
server.2=192.168.85.168:2888:3888
server.3=192.168.85.178:2888:3888
158服務器執行:
echo "1" > /root/tools/apache-zookeeper-3.5.7-bin/data/myid
168服務器執行:
echo "2" > /root/tools/apache-zookeeper-3.5.7-bin/data/myid
178服務器執行:
echo "3" > /root/tools/apache-zookeeper-3.5.7-bin/data/myid
(3)kafka集群配置
[root@ruanjianlaowang158 config]# cd /root/tools/kafka_2.12-2.4.1/config
[root@ruanjianlaowang158 config]# vi server.properties
#broker.id 三臺服務器不一樣,158服務器設定為1,168服務器設定為2,178服務器設定為3
broker.id=1
#三個服務器配置一樣
zookeeper.connect=192.168.85.158:2181,192.168.85.168:2181,192.168.85.178:2181
Kafka常用Broker配置說明:
| 配置項 | 默認值/示例值 | 說明 |
|---|---|---|
| broker.id | 0 | Broker唯一標識 |
| listeners | PLAINTEXT://192.168.85.158:9092 | 監聽資訊,PLAINTEXT表示明文傳輸 |
| log.dirs | /root/tools/apache-zookeeper-3.5.7-bin/data | kafka資料存放地址,可以填寫多個,用","間隔 |
| message.max.bytes | message.max.bytes | 單個訊息長度限制,單位是位元組 |
| num.partitions | 1 | 默認磁區數 |
| log.flush.interval.messages | Long.MaxValue | 在資料被寫入到硬碟和消費者可用前最大累積的訊息的數量 |
| log.flush.interval.ms | Long.MaxValue | 在資料被寫入到硬碟前的最大時間 |
| log.flush.scheduler.interval.ms | Long.MaxValue | 檢查資料是否要寫入到硬碟的時間間隔, |
| log.retention.hours | 24 | 控制一個log保留時間,單位:小時 |
| zookeeper.connect | 192.168.85.158:2181, |
192.168.85.168:2181,
192.168.85.178:2181 | ZooKeeper服務器地址,多臺用","間隔 |
(4)集群啟動
啟動方式跟單機一樣:
#啟動zookeeper
[root@ruanjianlaowang158 bin]# cd /root/tools/apache-zookeeper-3.5.7-bin/bin
[root@ruanjianlaowang158 bin]# ./zkServer.sh start
#啟動kafka
[root@ruanjianlaowang158 bin]# cd /root/tools/kafka_2.12-2.4.1/bin
[root@ruanjianlaowang158 bin]# ./zookeeper-server-start.sh ../config/server.properties &
(5)注意點
集群啟動的時候,單機那臺服務器(158)可能會報:Kafka:Configured broker.id 2 doesn't match stored broker.id 0 in meta.properties.
方案:在158服務器data中有個檔案:meta.properties,檔案中的broker.id也需要修改成與server.properties中的broker.id一樣,所以造成了這個問題,
(6)創建個topic,后面springboot專案測驗使用,
[root@ruanjianlaowang158 bin]# cd /root/tools/kafka_2.12-2.4.1/bin
[root@ruanjianlaowang158 bin]# ./kafka-topics.sh --create --zookeeper 192.168.85.158:2181,192.168.85.168:2181,192.168.85.178:2181 --replication-factor 3 --partitions 5 --topic aaaa
3、結合springboot專案
3.1 pom檔案
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.0.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.itany</groupId>
<artifactId>kafka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>kafka</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
說明:
主要就兩個gav,一個是spring-boot-starter-web,啟動web服務使用;一個是spring-kafka,這個是springboot集成額kafka核心包,
3.2 application.yml
spring:
kafka:
# 北游,kafka集群服務器地址
bootstrap-servers: 192.168.85.158:9092,192.168.85.168:9092,192.168.85.178:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: test
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
3.3 producer(訊息生產者)
@RestController
public class KafkaProducer {
@Autowired
private KafkaTemplate template;
//北游,topic使用上測驗創建的aaaa
@RequestMapping("/sendMsg")
public String sendMsg(String topic, String message){
template.send(topic,message);
return "success";
}
}
3.4 consumer(消費者)
@Component
public class KafkaConsumer {
//北游,這里是監控aaaa這個topic,直接列印到idea中,北游
@KafkaListener(topics = {"aaaa"})
public void listen(ConsumerRecord record){
System.out.println(record.topic()+":"+record.value());
}
}
3.5 驗證結果
(1)瀏覽器上輸入
http://localhost:8080/sendMsg?topic=aaaa&message=bbbb
(2)北游的idea控制臺列印資訊
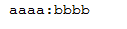
- 完整版kafka學習筆記領取
二、Kafka副本機制
1、什么是副本機制:
通常是指分布式系統在多臺網路互聯的機器上保存有相同的資料拷貝
2、副本機制的好處:
2.1 提供資料冗余
系統部分組件失效,系統依然能夠繼續運轉,因而增加了整體可用性以及資料持久性
2.2 提供高伸縮性
支持橫向擴展,能夠通過增加機器的方式來提升讀性能,進而提高讀操作吞吐量
2.3 改善資料區域性
允許將資料放入與用戶地理位置相近的地方,從而降低系統延時,
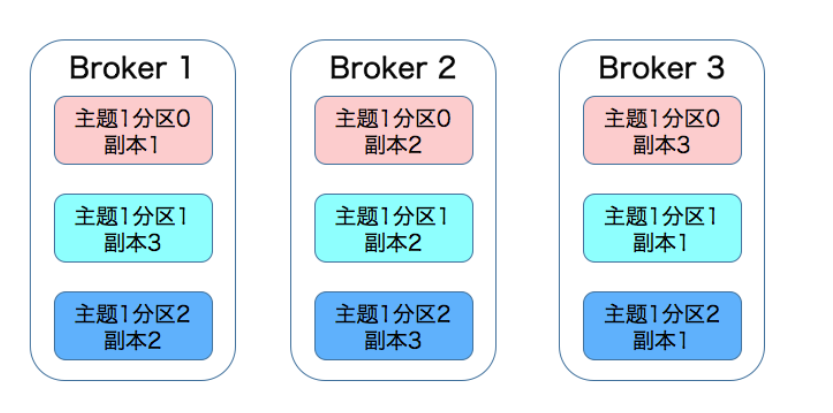
3、kafka的副本
(1)、 本質就是一個只能追加寫訊息的日志檔案
(2)、同一個磁區下的所有副本保存有相同的訊息序列
(3)、副本分散保存在不同的 Broker 上,從而能夠對抗部分 Broker 宕機帶來的資料不可用(Kafka 是有若干主題概,每個主題可進一步劃分成若干個磁區,每個磁區配置有若干個副本)
如下:有 3 臺 Broker 的 Kafka 集群上的副本分布情況
4、kafka如何保證同一個磁區下的所有副本保存有相同的訊息序列:
基于領導者(Leader-based)的副本機制
作業原理如圖:
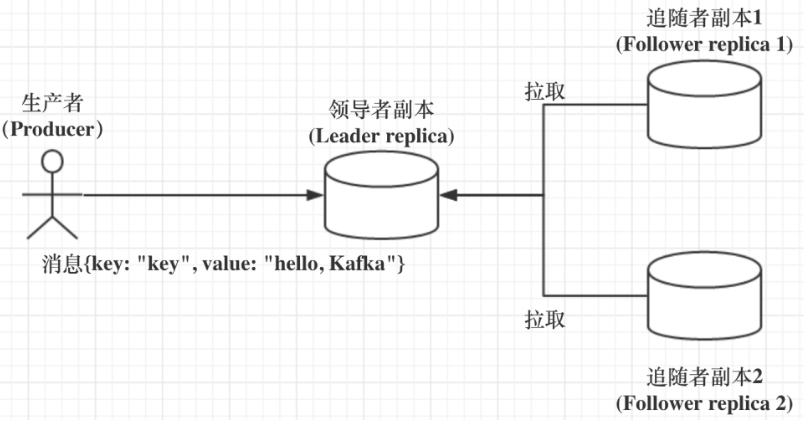
(1)、Kafka 中分成兩類副本:領導者副本(Leader Replica)和追隨者副本(Follower Replica),每個磁區在創建時都要選舉一個副本,稱為領導者副本,其余的副本自動稱為追隨者副本,
(2)、Kafka 中,追隨者副本是不對外提供服務的,追隨者副本不處理客戶端請求,它唯一的任務就是從領導者副本,所有的讀寫請求都必須發往領導者副本所在的 Broker,由該 Broker 負責處理,(因此目前kafka只能享受到副本機制帶來的第 1 個好處,也就是提供資料冗余實作高可用性和高持久性)
(3)、領導者副本所在的 Broker 宕機時,Kafka 依托于 ZooKeeper 提供的監控功能能夠實時感知到,并立即開啟新一輪的領導者選舉,從追隨者副本中選一個作為新的領導者,老 Leader 副本重啟回來后,只能作為追隨者副本加入到集群中,
5、kafka追隨者副本到底在什么條件下才算與 Leader 同步
Kafka 引入了 In-sync Replicas,也就是所謂的 ISR 副本集合,ISR 中的副本都是與 Leader 同步的副本,相反,不在 ISR 中的追隨者副本就被認為是與 Leader 不同步的
6、kafka In-sync Replicas(ISR)
(1)、ISR不只是追隨者副本集合,它必然包括 Leader 副本,甚至在某些情況下,ISR 只有 Leader 這一個副本
(2)、通過Broker 端replica.lag.time.max.ms 引數(Follower 副本能夠落后 Leader 副本的最長時間間隔)值來控制哪個追隨者副本與 Leader 同步?只要一個 Follower 副本落后 Leader 副本的時間不連續超過 10 秒,那么 Kafka 就認為該 Follower 副本與 Leader 是同步的,即使此時 Follower 副本中保存的訊息明顯少于 Leader 副本中的訊息,
(3)、ISR 是一個動態調整的集合,而非靜態不變的,
某個追隨者副本從領導者副本中拉取資料的程序持續慢于 Leader 副本的訊息寫入速度,那么在 replica.lag.time.max.ms 時間后,此 Follower 副本就會被認為是與 Leader 副本不同步的,因此不能再放入 ISR 中,此時,Kafka 會自動收縮 ISR 集合,將該副本“踢出”ISR,
倘若該副本后面慢慢地追上了 Leader 的進度,那么它是能夠重新被加回 ISR 的,
(4)、ISR集合為空則leader副本也掛了,這個磁區就不可用了,producer也無法向這個磁區發送任何訊息了,(反之leader副本掛了可以從ISR集合中選舉leader副本)
7、kafka leader副本所在broker掛了,leader副本如何選舉
(1)、ISR不為空,從ISR中選舉
(2)、ISR為空,Kafka也可以從不在 ISR 中的存活副本中選舉,這個程序稱為Unclean 領導者選舉,通過Broker 端引數unclean.leader.election.enable控制是否允許 Unclean 領導者選舉,
開啟 Unclean 領導者選舉可能會造成資料丟失,但好處是,它使得磁區 Leader 副本一直存在,不至于停止對外提供服務,因此提升了高可用性,反之,禁止 Unclean 領導者選舉的好處在于維護了資料的一致性,避免了訊息丟失,但犧牲了高可用性,
一個分布式系統通常只能同時滿足一致性(Consistency)、可用性(Availability)、磁區容錯性(Partition tolerance)中的兩個,顯然,在這個問題上,Kafka 賦予你選擇 C 或 A 的權利,
強烈建議不要開啟unclean leader election,畢竟我們還可以通過其他的方式來提升高可用性,如果為了這點兒高可用性的改善,犧牲了資料一致性,那就非常不值當了,
ps1:leader副本的選舉也可以理解為磁區leader的選舉
ps2:broker的leader選舉與磁區leader的選舉不同,
Kafka的Leader選舉是通過在zookeeper上創建/controller臨時節點來實作leader選舉,并在該節點中寫入當前broker的資訊
{“version”:1,”brokerid”:1,”timestamp”:”1512018424988”}
利用Zookeeper的強一致性特性,一個節點只能被一個客戶端創建成功,創建成功的broker即為leader,即先到先得原則,leader也就是集群中的controller,負責集群中所有大小事務,
當leader和zookeeper失去連接時,臨時節點會洗掉,而其他broker會監聽該節點的變化,當節點洗掉時,其他broker會收到事件通知,重新發起leader選舉
再給你們留個小問題:如果允許 Follower 副本對外提供讀服務,你覺得應該如何避免或緩解因 Follower 副本與 Leader 副本不同步而導致的資料不一致的情形?
三、實時日志統計流程
1、專案流程
在整合這套方案的時候,專案組也是經過一番討論,在討論中,觀點很多,有人認為直接使用Storm進行實時處理,去掉Kafka環節;也有認為直接使用Kafka的API去消費,去掉Storm的消費環節等等,但是最終組內還是一致決定使用這套方案,原因有如下幾點:
- 業務模塊化
- 功能組件化
我們認為,Kafka在整個環節中充當的職責應該單一,這專案的整個環節她就是一個中間件,下面用一個圖來說明這個原因,如下圖所示:
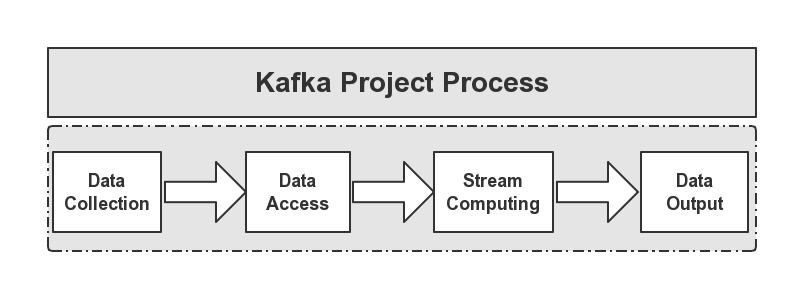
整個專案流程如上圖所示,這樣劃分使得各個業務模塊化,功能更加的清晰明了,
- Data Collection
負責從各個節點上實時收集用戶上報的日志資料,我們選用的是Apache的Flume NG來實作,
- Data Access
由于收集的資料的速度和資料處理的速度不一定是一致的,因此,這里添加了一個中間件來做處理,所使用的是Apache的Kafka,關于Kafka集群部署,另外,有一部分資料是流向HDFS分布式檔案系統了的,方便于為離線統計業務提供資料源,
- Stream Computing
在收集到資料后,我們需要對這些資料做實時處理,所選用的是Apache的Storm,關于Storm的集群搭建部署博客后面補上,較為簡單,
- Data Output
在使用Storm對資料做處理后,我們需要將處理后的結果做持久化,由于對回應速度要求較高,這里采用Redis+MySQL來做持久化,整個專案的流程架構圖,如下圖所示:
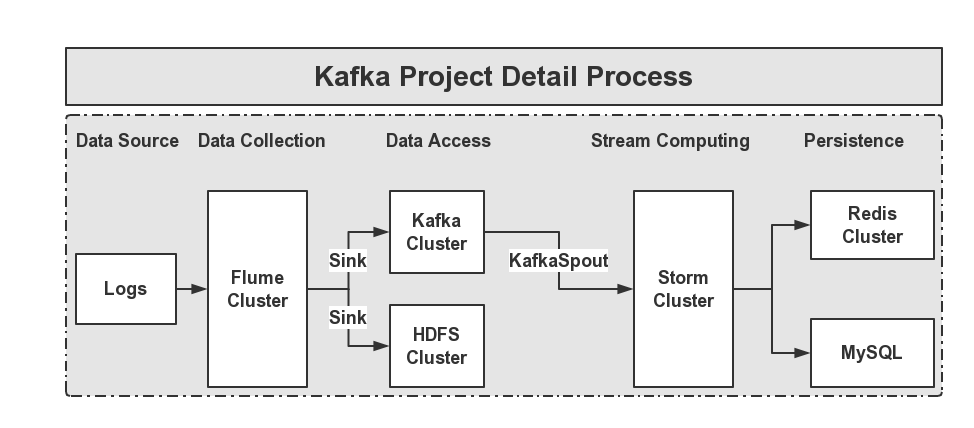
2、Flume
Flume是一個分布式的、高可用的海量日志收集、聚合和傳輸日志收集系統,支持在日志系統中定制各類資料發送方(如:Kafka,HDFS等),便于收集資料,Flume提供了豐富的日志源收集型別,有:Console、RPC、Text、Tail、Syslog、Exec等資料源的收集,在我們的日志系統中目前我們所使用的是spooldir方式進行日志檔案采集,配置內容資訊如下所示:
producer.sources.s.type = spooldir
producer.sources.s.spoolDir = /home/hadoop/dir/logdfs
當然,Flume的資料發送方型別也是多種型別的,有:Console、Text、HDFS、RPC等,這里我們系統所使用的是Kafka中間件來接收,配置內容如下所示:
producer.sinks.r.type = org.apache.flume.plugins.KafkaSink
producer.sinks.r.metadata.broker.list=dn1:9092,dn2:9092,dn3:9092
producer.sinks.r.partition.key=0
producer.sinks.r.partitioner.class=org.apache.flume.plugins.SinglePartition
producer.sinks.r.serializer.class=kafka.serializer.StringEncoder
producer.sinks.r.request.required.acks=0
producer.sinks.r.max.message.size=1000000
producer.sinks.r.producer.type=sync
producer.sinks.r.custom.encoding=UTF-8
producer.sinks.r.custom.topic.name=test
3、Kafka
Kafka是一種提供高吞吐量的分布式發布訂閱訊息系統,她的特性如下所示:
- 通過磁盤資料結構提供訊息的持久化,這種結構對于即使資料達到TB+級別的訊息,存盤也能夠保持長時間的穩定,
- 搞吞吐特性使得Kafka即使使用普通的機器硬體,也可以支持每秒數10W的訊息,
- 能夠通過Kafka Cluster和Consumer Cluster來Partition訊息,
Kafka的目的是提供一個發布訂閱解決方案,他可以處理Consumer網站中的所有流動資料,在網頁瀏覽,搜索以及用戶的一些行為,這些動作是較為關鍵的因素,這些資料通常是由于吞吐量的要求而通過處理日志和日志聚合來解決,對于Hadoop這樣的日志資料和離線計算系統,這樣的方案是一個解決實時處理較好的一種方案,
關于Kafka集群的搭建部署和使用,上面已經寫了,不會的朋友翻上去再看一下,這里就不贅述了,
4、Storm
Twitter將Storm開源了,這是一個分布式的、容錯的實時計算系統,已被貢獻到Apache基金會,下載地址如下所示:
http://storm.apache.org/downloads.html
Storm的主要特點如下:
- 簡單的編程模型,類似于MapReduce降低了并行批處理復雜性,Storm降低了進行實時處理的復雜性,
- 可以使用各種編程語言,你可以在Storm之上使用各種編程語言,默認支持Clojure、Java、Ruby和Python,要增加對其他語言的支持,只需實作一個簡單的Storm通信協議即可,
- 容錯性,Storm會管理作業行程和節點的故障,
- 水平擴展,計算是在多個執行緒、行程和服務器之間并行進行的,
- 可靠的訊息處理,Storm保證每個訊息至少能得到一次完整處理,任務失敗時,它會負責從訊息源重試訊息,
- 快速,系統的設計保證了訊息能得到快速的處理,使用?MQ作為其底層訊息佇列,
- 本地模式,Storm有一個本地模式,可以在處理程序中完全模擬Storm集群,這讓你可以快速進行開發和單元測驗,
Storm集群由一個主節點和多個作業節點組成,主節點運行了一個名為“Nimbus”的守護行程,用于分配代碼、布置任務及故障檢測,每個作業節 點都運行了一個名為“Supervisor”的守護行程,用于監聽作業,開始并終止作業行程,
Nimbus和Supervisor都能快速失敗,而且是無 狀態的,這樣一來它們就變得十分健壯,兩者的協調作業是由Apache的ZooKeeper來完成的,
Storm的術語包括Stream、Spout、Bolt、Task、Worker、Stream Grouping和Topology,
- Stream是被處理的資料,
- Spout是資料源,
- Bolt處理資料,
- Task是運行于Spout或Bolt中的 執行緒,
- Worker是運行這些執行緒的行程,
- Stream Grouping規定了Bolt接收什么東西作為輸入資料,資料可以隨機分配(術語為Shuffle),或者根據欄位值分配(術語為Fields),或者廣播(術語為All),或者總是發給一個Task(術語為Global),也可以不關心該資料(術語為None),或者由自定義邏輯來決定(術語為 Direct),
- Topology是由Stream Grouping連接起來的Spout和Bolt節點網路,在Storm Concepts頁面里對這些術語有更詳細的描述,
關于Storm集群的搭建部署,博客在下一篇中更新,到時候會將更新地址附在這里,這里就先不對Storm集群的搭建部署做過多的贅述了,
5、總結
Kafka 日志訊息保存時間總結
Kafka 作為一個高吞吐的訊息中間件和傳統的訊息中間件一個很大的不同點就在于它的日志實際上是以日志的方式默認保存在/kafka-logs檔案夾中的,雖然默認有7天清楚的機制,但是在資料量大,而磁盤容量不足的情況下,經常出現無法寫入的情況,如何調整Kafka的一些默認引數就顯得比較關鍵了,這里筆者整理了一些常見的配置引數供大家參考:
分段策略屬性
| 屬性名 | 含義 | 默認值 |
|---|---|---|
| log.roll.{hours,ms} | 日志滾動的周期時間,到達指定周期時間時,強制生成一個新的segment | 168(7day) |
| log.segment.bytes | 每個segment的最大容量,到達指定容量時,將強制生成一個新的segment | 1G(-1為不限制) |
| log.retention.check.interval.ms | 日志片段檔案檢查的周期時間 | 60000 |
日志重繪策略
Kafka的日志實際上是開始是在快取中的,然后根據策略定期一批一批寫入到日志檔案中去,以提高吞吐率,
| 屬性名 | 含義 | 默認值 |
|---|---|---|
| log.flush.interval.messages | 訊息達到多少條時將資料寫入到日志檔案 | 10000 |
| log.flush.interval.ms | 當達到該時間時,強制執行一次flush | null |
| log.flush.scheduler.interval.ms | 周期性檢查,是否需要將資訊flush | 很大的值 |
日志保存清理策略
| 屬性名 | 含義 | 默認值 |
|---|---|---|
| log.cleanup.polict | 日志清理保存的策略只有delete和compact兩種 | delete |
| log.retention.hours | 日志保存的時間,可以選擇hours,minutes和ms | 168(7day) |
| log.retention.bytes | 洗掉前日志檔案允許保存的最大值 | -1 |
| log.segment.delete.delay.ms | 日志檔案被真正洗掉前的保留時間 | 60000 |
| log.cleanup.interval.mins | 每隔一段時間多久呼叫一次清理的步驟 | 10 |
| log.retention.check.interval.ms | 周期性檢查是否有日志符合洗掉的條件(新版本使用 | ) 300000 |
這里特別說明一下,日志的真正清楚時間,當洗掉的條件滿足以后,日志將被“洗掉”,但是這里的洗掉其實只是將該日志進行了“delete”標注,檔案只是無法被索引到了而已,
但是檔案本身,仍然是存在的,只有當過了log.segment.delete.delay.ms 這個時間以后,檔案才會被真正的從檔案系統中洗掉,
文章寫到這里差不多了,比我預計要寫得短一些,因為還有一些東西要寫出來難免長篇大論,篇幅不允許,想更透徹的掌握kafka的同學可以領取我整理的完整版kafka學習筆記,最近要準備面試的同學可以看看我這份kafka高頻面試題整理,
后面我會把另外兩個中間件也分別寫文章分析,可以給我點個關注第一時間接到通知
然后,可以點個贊嗎兄弟們!
end
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/280669.html
標籤:其他