文章目錄
- 前言
- 字串長度函式[`strlen`](http://www.cplusplus.com/reference/cstring/strlen/)
- 1.`strlen`的使用(接收地址)
- 2.使用`strlen`的小坑
- `strlen`的模擬(計數法 遞回 指標相減)
- 01 計數法
- 02 遞回法
- 03 指標相減法
- 長度不受限制的字串函式
- `strcpy`
- 模擬實作`strcpy`
- `strcat`
- 提醒: 追加原理是首先找到destination的\0,然后在\0上追加source
- 提醒:如果自己給自己追加會崩潰.因為\0被覆寫了
- `strcat`的模擬實作
- `strcmp`
- `strcmp`模擬實作
- 長度受限制的函式
- `strncpy`
- 模擬實作`strncpy`
- `strncat`
- 模擬實作`strncat`
- `strncmp`
- `strncmp`的模擬實作
- 字串的查找
- `strstr`功能是查找一個字串是否是另一個字串的子串.
- 模擬實作`strstr`
- `strtok`
- 示例1:
- 巧妙用法示例2:
- 錯誤資訊報告
- `strerror`
- 示例1:
- 示例2:
- 字符分類函式(需要引入`
前言
C語言中對字符和字串的處理很是頻繁,但是C語言本身是沒有字串型別的,字串通常放在 常量字串 中
或者 字符陣列 中, 字串常量 適用于那些對它不做修改的字串函式.
因此此篇文章便是介紹字符和字串函式的使用與注意事項.
字串長度函式strlen
1.strlen的使用(接收地址)
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = "abcdefg";
char arr2[] = {'a','b','c','d','e','f','g'};
printf("%d",strlen(arr1));
printf("%d",strlen(arr2));
return 0;
}
上面的結果是:
7
隨機值 (因為
strlen接收首元素地址然后向后查找到\0停止,但是arr2并沒有\0結尾,隨意是隨機值)
2.使用strlen的小坑
下面一段代碼,你覺得答案是多少??
#include <stdio.h> #include <string.h> int main() { const char*str1 = "abcdef"; const char*str2 = "bbb"; if(strlen(str2)-strlen(str1)>0) { printf("str2>str1\n"); } else { printf("srt1>str2\n"); } return 0; }結果是什么呢???
答案是:
str2>str1因為
strlen的回傳值是無符號整型,所以無符號減去無符號一定是大于等于0的
strlen的模擬(計數法 遞回 指標相減)
01 計數法
size_t my_strlen(char* str)
{
unsigned int count = 0;
while(*str)
{
count++;
str++;
}
return count;
}
02 遞回法
size_t my_strlen(char* str)
{
if (*str != 0)
{
return 1 + my_strlen(++str);
}
return 0;
}
03 指標相減法
size_t my_strlen(char* str)
{
char* ret = str;
while(*str) str++;
return str-ret;
}
長度不受限制的字串函式
strcpy
官方寫法
char* strcpy(char* strDestination, const char* strSource);即第一個引數是目的地地址,第二個引數源地址,
例子:
#include <stdio.h> #include <string.h> int main() { char arr1[] = "abcdef"; char arr2[] = "FF"; strcpy(arr1,arr2); printf("%s",arr1); return 0; }結果:
FF注意點: 這里的復制其實并不是真正的復制,準確的說是覆寫,即把arr2的所有內容(包括
\0)都覆寫到arr1對應位置,也就是說雖然列印出來
arr1是FF,但是實質上arr1等于FF\0def不信看下面的圖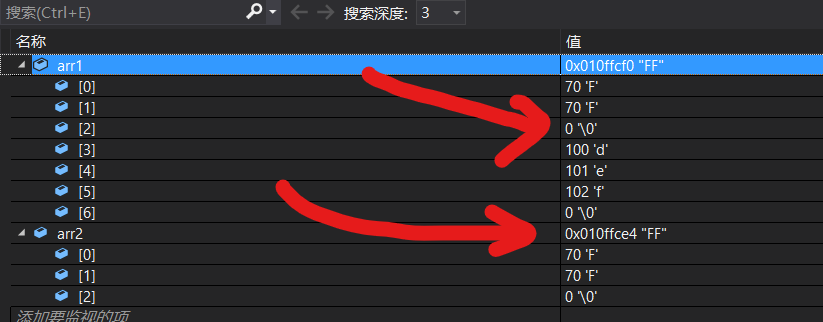
注意事項:
源字串必須以 ‘\0’ 結束,,如果原字串沒有\0,就會一直拷貝原字串地址后面的所有內容,直到找到值為0
會將源字串中的也 ‘\0’ 拷貝到目標空間,
**目標空間必須足夠大,以確保能存放源字串,**如果目標空間不夠大,則會導致源字串拷貝不進去;
目標空間必須可變,即目標空間沒有
const修飾
模擬實作strcpy
char* my_strcpy(const char* destination,const char* source)
{
assert(destination && source);
while(*(char*)destination++ = *(char*)source++) ;
return destination;
}
strcat
官方寫法
char* strcat( char* strDestination, const char *strSource);即第一個引數是目的空間 第二個引數是原始碼空間
使用例子:
#include <stdio.h> #include <string.h> int main() { char arr1[10] = "abcd"; char arr3[] = "ABCD"; my_strcpy(arr1, arr3); printf("%s", arr1); return 0; }答案:
abcdABCD但是如果這樣呢
#include <stdio.h> #include <string.h> int main() { char arr1[] = "abcd"; char arr3[] = "ABCD"; my_strcpy(arr1, arr3); printf("%s", arr1); return 0; }答案:
報錯!!! 因為目標空間
arr1大小不夠裝下再追加,所以我么在使用strcat時候一定要注意目標空間的大小,同時源字串一定要\0結尾提醒: 追加原理是首先找到destination的\0,然后在\0上追加source
比如下面
#include <stdio.h> #include <string.h> int main() { char arr1[11] = "ab\0dxxxxxx"; char arr3[] = "ABCD"; strcat(arr1,arr3); printf("%s", arr1); return 0; }
我們可以看到
arr1從ab\0dxxxxxx變成了abABCD\0xxx因為他是找到第一個\0,然后在\0上追加.
提醒:如果自己給自己追加會崩潰.因為\0被覆寫了
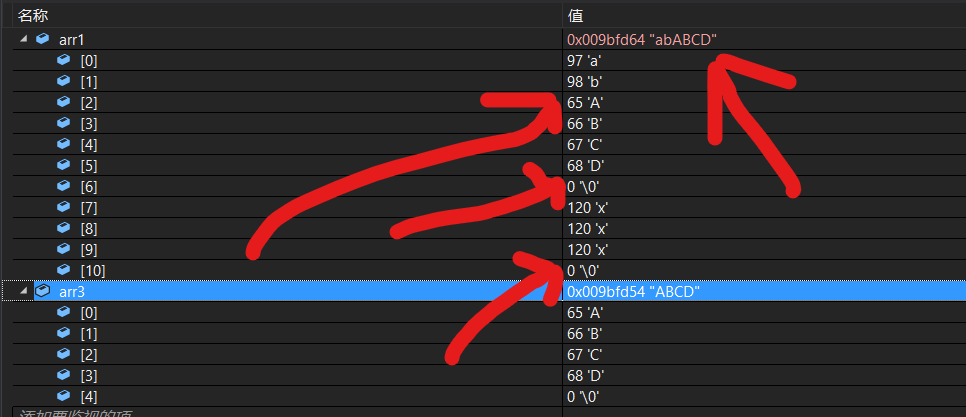
總結:
-
源字串必須以 ‘\0’ 結束,
-
目標空間必須有足夠的大,能容納下源字串的內容,
-
目標空間必須可修改,
strcat的模擬實作
char* ,my_strcat(char* strDestination, const char* strSource)
{
char* ret = strDestination;
/*先找到目標空間的\0*/
while(*strDestination) strDestination++;
/*開始追加*/
while(*strDestination++= *(char*)strSource++);
return ret;
}
strcmp
如果有下面的題:
#include <stdio.h>
int main()
{
char* p1 = "abcdef";
char* p2 = "aqwer";
if(p1 < p2) printf("-1\n");
if(p1 == p2) printf("0\n");
if(p1 > p2) printf("1\n");
return 0;
}
答案: 0
你會發現,
p1與p2并沒有真正的再比較全部字符,而是比較了第一個字符部分.因此我們想要真正的比較字串就需要一個函式: ----->
strcmp
int strcmp ( const char * str1, const char * str2 );
- 如果第一個字串大于第二個字串,則回傳大于0數字
- 如果第一個字串等于第二個字串,則回傳0
- 如果第一個字串小于第二個字串,則回傳小于0數字
例如:
#include <stdio.h> int main() { char* p1 = "abcdef"; char* p2 = "aqwer"; char* p3 = "aavd"; char* p4 = "abcdef"; printf("%d\n", strcmp(p1, p2)); printf("%d\n", strcmp(p1, p3)); printf("%d\n", strcmp(p1, p4)); return 0; }

strcmp模擬實作
int my_strcmp(const char* arr1, const char* arr2)
{
while (*(char*)arr1 && (*(char*)arr1 == *(char*)arr2))
{
(char*)arr1++;
(char*)arr2++;
}
if (!*(char*)arr1) return 0;
/*當跳出回圈就表示碰到不一樣的了,所以回傳差值*/
return *(char*)arr1 - *(char*)arr2;
}
長度受限制的函式
前面的三個不受長度限制的函式有局限性:
比如strcpy:------->源字串需要末尾有\0,且必須拷貝到\0結束,不關心是否目的地裝得下源字串,撐爆就報錯
? strcat:------->源字串需要末尾有\0,且必須追加到\0結束,不關心是否目的地裝得下源字串,撐爆就報錯
? strcmp:------->源字串需要末尾有\0,且必須比較到\0結束,不關心是否目的地裝得下源字串,撐爆就報錯
因此,變有了下面的與前三者功能相似,但是可以控制數量的長度受限函式
strncpy
用法與strcpy一樣,但是多了個引數 size_t count,即需要拷貝的字符數量
char * strncpy ( char * destination, const char * source, size_t count );
用法:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = "abcdefg";
char arr2[] = "XXXX";
strncpy(arr1,arr2,3);
printf("%s",arr1);
return 0;
}
答案:
XXXdefg你會看到,并沒有再把
arr2的\0給放進arr1
**注意點:**當count的數量大于arr2的長度時候,會自動用\0補數,比如:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = "abcdefghijklmnopq";
char arr2[] = "XXXX";
strncpy(arr1,arr2,15);
printf("%s",arr1);
return 0;
}
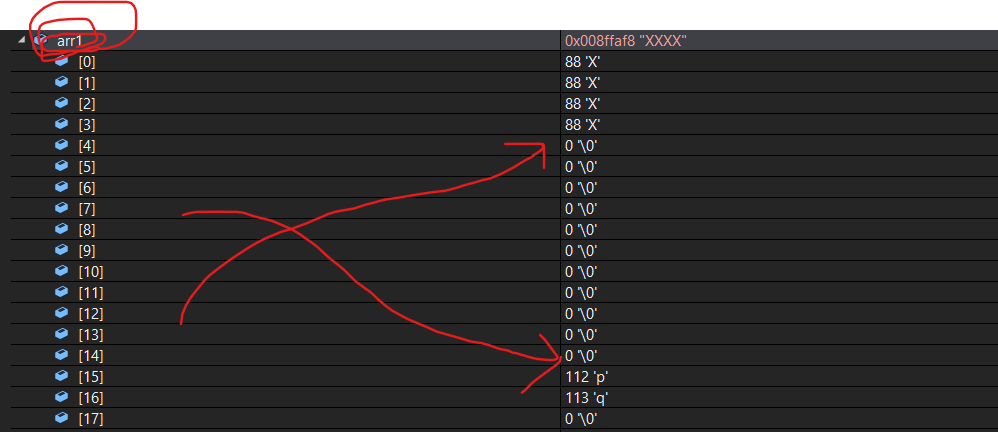
可以清楚的看到arr1里面的內容:自動補充了很多\0
模擬實作strncpy
char* my_strncpy(char* str1, const char* str2, size_t count)
{
char* ret = str1;
while (count&& (*str1++ = *(char*)str2++)) count--;
if (count)
/*--count 是因為str1已經為\0,不再需要繼續賦值\0,所以先減一下*/
while (--count) *str1++ = '\0';
return ret;
}
strncat
用法與
strcat一樣,但是多了個引數size_t count,即需要追加的字符數量
char * strncat ( char * destination, const char * source, size_t count );
用法示例:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[50] = "abcdef\0abcdefghilj";
char arr2[] = "XXXX";
strncat(arr1, arr2, 15);
printf("%s", arr1);
return 0;
}
答案:
abcdefXXXX而當
count>arr2時,就不再管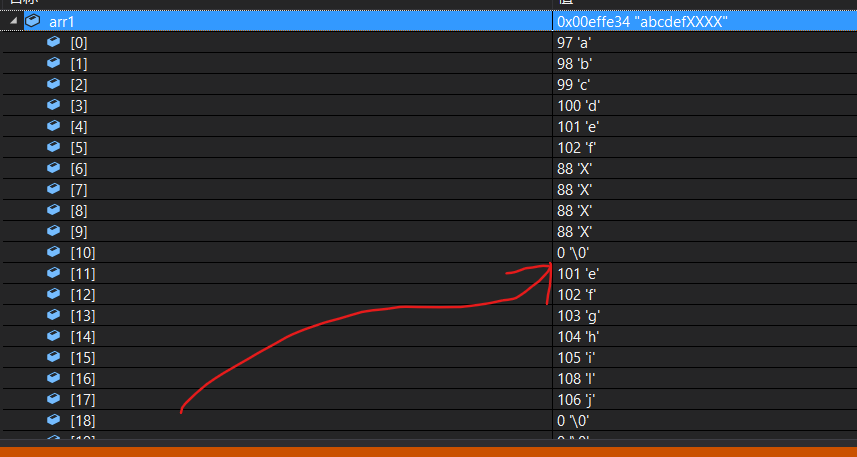
模擬實作strncat
char* my_strncat(char* str1, const char* str2, size_t count)
{
char* ret = str1;
while (*str1) str1++;
while (count-- && (*str1++ = *(char*)str2++));
return ret;
}
strncmp
int strncmp ( const char * str1, const char * str2, size_t num );用法與前面一樣,我就不再贅述怎么用,直接開始模擬
strncmp的模擬實作
int my_strncmp(const char* str1, const char* str2, size_t num)
{
while (num-- && *str1 && (*str1 == *str2))
{
str1++;
str2++;
}
return *(char*)str1 - *(char*)str2;
}
字串的查找
strstr功能是查找一個字串是否是另一個字串的子串.
- 并且如果找到就回傳在目的地中源字串的第一個地址,找不到就回傳空指標(NULL)
例如 :
#include <stdio.h> #include <string.h> int main () { char str[] ="This is a simple string"; char * pch; pch = strstr (str,"simple"); if (pch != NULL) strncpy (pch,"sample",6); puts (str); return 0; }結果:
This is a simple string,可以看見,雖然前面呼叫了strncpy但是對str好像并沒有影響,因為pch是將接收的是str中的simple的首地址.即S
模擬實作strstr
char* my_strstr(const char* dest,const char* src)
{
/*第一步,一一比較.當src都比較完了(*src等于\0),則說明是子串*/
while(*dest) //確保dest每個字符后面的字串與src匹配
{
char* ret = dest;
//一一比對,當src等于\0,說明全部比對完成.
while((*ret == *src) && (*src!='\0'))
{
ret++;
src++;
}
if(!*src) return dest;
(char*)dest++;
}
return NULL;
}
像上面這樣真的完畢了嗎??? 我們似乎只處理了 像下面一樣的例子:
目標:
"abcdefg"源串:
"cdef"
那么,還有什么不一樣的例子我們沒有考慮到呢???哦??好像是這個
目標:
"abcdefg"源串:
"defghi"
而且好像還有這個
目標:
"ABCDDDEFGH"源串:
"DDEFG"這種情況如果只用最開始模擬的情況,則會回傳空指標.
所以針對第二種與第三種情況,內層回圈還應該有另外一個條件,即*dest ! = '\0' .
并且,每個字符后面的字串比較完畢,指標又回傳到所比較字串開頭.因此,添加以下代碼
char* my_strstr(const char* dest, const char* src)
{
char* s1;
char* s2;
char* cur = (char*)dest;
/*第一步,一一比較.當src都比較完了(*src等于\0),則說明是子串*/
while (*cur) //確保dest每個字符后面的字串與src匹配
{
s1 = (char*)cur;
s2 = (char*)src;
//一一比對,當src等于\0,說明全部比對完成
while ((*s1 != '\0') && (*s2 != '\0')&&(*s1 == *s2))
{
s1++;
s2++;
}
if (!*s2) return cur;
cur++;
}
return NULL;
}
另外,對于求子字串的演算法還有KMP,可以參考一位大佬的文章KMP
strtok
字串分割函式,即目標字串通過設定的分割符進行分割出來
官方寫法:
char * strtok ( char * str, const char * delimiters );第一個引數是目標**
被分割字串,第二個引數是分隔符集合**用法:
- 傳入一份臨時拷貝的字串給
str,因為不想要源字串被真正的分割.- 對于同一個字串,第一次呼叫,必須傳入地址,第二次以及多次傳入
NULL- 對于
strtok的妙用一般是使用for回圈.- 未分割完時,回傳值是被分割的小段字串的首地址,分割完時,回傳NULL
示例1:
#include <stdio.h>
#include <string.h>
int main()
{
char str[] = "www.123pao@qq.com/cn";
char delimiters[] = ".@/";
printf("%s\n",strtok(str,delimiters));
printf("%s\n",strtok(NULL,delimiters));
printf("%s\n",strtok(NULL,delimiters));
printf("%s\n",strtok(NULL,delimiters));
return 0;
}
結果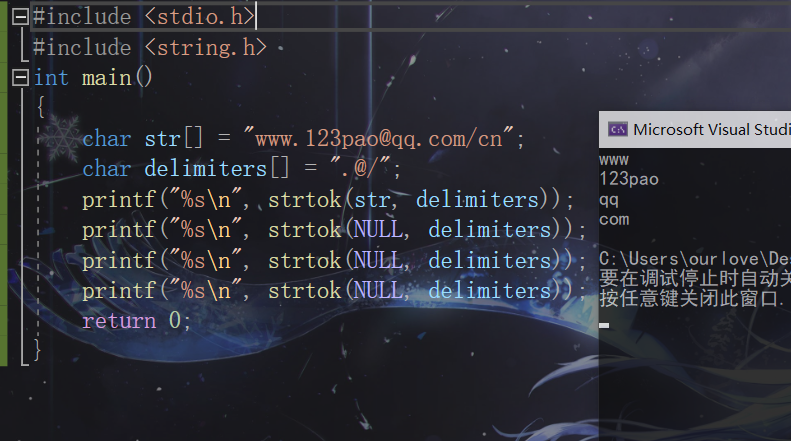
巧妙用法示例2:
#include <stdio.h>
#include <string.h>
int main()
{
char str[] = "www.123pao@qq.com/cn";
char delimiters[] = ".@/";
char* p;
for(p = strtok(str,delimiters);p != NULL;p = strtok(NULL,delimiters))
{
printf("%s\n",p);
}
return 0;
}
結果: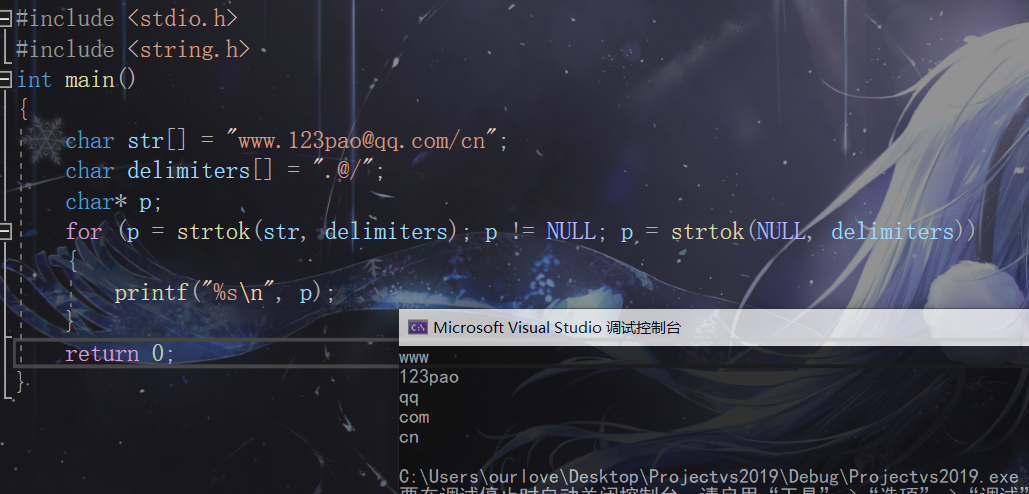
錯誤資訊報告
strerror
官方寫法: char * strerror ( int errnum ) 即輸入一個代表錯誤碼的整數,然后會回傳錯誤資訊
示例1:
#include <stdio.h>
#include <string.h>
int main()
{
printf("%s\n",strerror(0));
printf("%s\n",strerror(1));
printf("%s\n",strerror(2));
printf("%s\n",strerror(3));
return 0;
}
結果:
但是這個函式我們經常用在哪里呢???,答案是配合errno使用
errno是一個全域的錯誤碼變數- 當C語言庫函式在執行程序中,發生錯誤,就會把對應錯誤碼,賦值到
errno中.
示例2:
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main()
{
FILE* pf = fopen("text.txt","r");//隨便寫的一個檔案名,并不存在.
if(pf == NULL) printf("%s",strerror(errno));
else printf("打開成功!!!!!!!");
return 0;
}
結果:
字符分類函式(需要引入<ctype.h>)
iscntrl 任何可控字符
isspace 空白字符:空格, \f(換頁), \n(換行),\t(水平制表符),\r(回車),\v(錘子制表符)
isdigit 檢驗十進制數字 0 ~ 9
isxdigit 檢驗16進制數字 0 ~ F
islower 檢驗是否是小寫字母 a ~ z
isupper 檢驗是否是大寫字母 A ~ Z
isalpha 檢驗是都是字母 a ~ z 和 A ~ Z
isalnum 檢驗是否是數字和字符 0~9 a~z A~Z
驗證:隨機用幾個函式示范
#include <stdio.h>
#include <ctype.h>
int main()
{
char num[] = "abEF 123";
printf("%d\n",islower(num[0]));
printf("%d\n",isupper(num[2]));
printf("%d\n",isdigit(num[5]));
return 0;
}
結果:
2 1 4
但是不同電腦可能不同結果.因為只要符合就回傳的是 非零數
字符轉換函式(tolower和toupper)
#include <stdio.h>
#include <ctype.h>
#include <string.h>
int main()
{
char a[] = "abcdef";
char b[] = "ASDFG";
for (int i = 0; i < strlen(a); i++)
{
printf("%c",toupper(a[i]));
}
printf("\n");
for (int i = 0; i < strlen(b); i++)
{
printf("%c", tolower(b[i]));
}
printf("\n");
return 0;
}
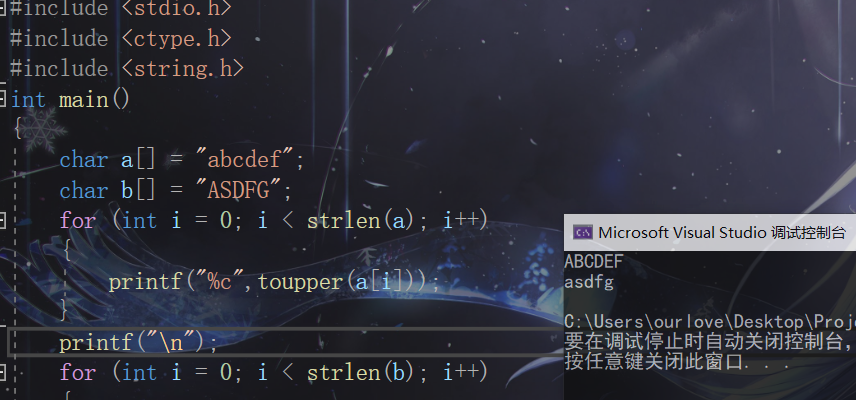
記憶體函式
上面我已經敘述了很多的關于字串的處理函式
包括以下:
strlenstrcpystrcatstrcmpstrncpystrncatstrncmpstrstrstrtok字符分類函式 字符轉換 函式
但是我們能夠明顯的發現,我們都是局限在處理 字串 上面,并不能處理其他的型別.
比如我需要復制一份陣列,如果我們用strcpy試試.
#include <stdio.h>
#include <string.h>
int main()
{
int num1[] = {1,3,5,7,9};
int num2[5] = {0}; //初始化為0
strcpy(num2,num1);
for(int i= 0;i<5;i++)
{
printf("%d\n", num[i]);
}
return 0;
}
結果:
1
0
0
0
0
原因: strcpy 是一個位元組一個位元組進行復制的,而我們的計算機大部分都是小端存盤.
即陣列num1的存放結構如圖;

所以當strcpy復制了01 之后,后面就是0,便停止了復制.而目的陣列num2本就是全部為0,所以當第一個位元組被復制一份01以后,num2[0]的值就是1,而后面都沒有復制,所以全是0
因此,我們引入了記憶體處理函式,主要是下面幾個 :
memcpymemmovememcmpmemset
memcpy的使用與模擬
官方檔案:
void * memcpy ( void * destination, const void * source, size_t num );第一個引數: 目的地地址
第二個引數: 源字串地址
第三個引數: 位元組數量
memcpy使用例子;
#include <stdio.h>
#include <string.h>
int main()
{
int num1[5] = { 8,8,8,8,8 }; //初始化為0
int num2[5] = { 1,3,5,7,9 };
memcpy(num1, num2, 12); // 12個位元組就是3個整數
for (int i = 0; i < 5; i++)
{
printf("%d ", num1[i]);
}
return 0;
}
結果: ****
****
成功復制!!!
memcpy的模擬實作
其實這個模擬還是比較簡單的(相比于
qsort的模擬),因為都用到了 萬能指標void*,接收一切
在我么實作這個函式之前,我們需要首先確定他是怎么復制的…前面已經說過,是一個位元組一個位元組復制的.那么我們肯定需要一個回圈,且回圈20次,但是接收的引數都是指標,而且 目的地還是 void*指標,那么怎么連接上 第三個引數與 第一個引數呢?,答案是 字符指標
因為一個字符指標的跳躍性就是 一個位元組,剛好符合 size_t num
void* my_memcpy(void* dest, const void* src, size_t num)
{
char* ret = dest;
while (num--)
{
*(char*)dest = *(char*)src;
++(char*)dest;
//之所以前置++,是因為結合性++高于(型別轉化),而dest與src都是void*
//不能加減,所以就會報錯,所以變成前置++
++(char*)src;
}
return ret;
}
memmove的使用與模擬
官方檔案:
void * memcpy ( void * destination, const void * source, size_t num );用法與
memcpy一模一樣.這里就不再贅述.那么他的功能是什么呢?? 他的功能也與
memcpy一模一樣,那我們還學習什么呢??那么,如果我們用自己寫的函式
my_memcpy實作把自己的一部分復制到另一部分去呢???比如下面例子:
int arr[] = {1,2,3,4,5,6,7,8,9,10};如果我想把 1 2 3 4 5 放到 4 5 6 7 8的位置呢??如果使用自己實作的
my_memcpy答案是這樣的1 2 3 1 2 3 1 2 9 10
為什么呢??因為當空間重疊時候,自己去復制自己時候,有一部分就會被覆寫,如圖

而memmove的作用就是來實作重疊空間的復制
演算法描述:
那么重疊空間我們怎么來實作進行復制呢???
很簡單,我們倒著來放.比如剛才的1 2 3 4 5 放到 4 5 6 7 8,
我們從后開始,先把5 放到 8位置-------> 4放到 7位置----->3放到6位置------>2放到5位置------->1放到4位置
問題1 :
所有的都可以這樣嗎?? 那我如果想要把4 5 6 7 8 放到1 2 3 4 5位置呢???如果倒著放,就會又混亂.因此我們是需要分情況進行設計的.
情況1:
目的位置在源位置之后,比如1 2 3 4 5是源位置,1就是源首地址. 而4 5 6 7 8是目的地址,而4就是目的首地址.這符合目的位置在原位置之后,就采用 從后向前復制
而這種情況的難點就是怎么找最后一個元素的最后一個位元組位置
答案是
dest+num-1和src + num -1,為何??見圖:
情況2:
除去
情況1的情況,就都采用 挨著順序復制
模擬:
void* my_memmove(void* dest,const void* src,size_t num)
{
char* ret = dest;
if(dest > src)
{
while(num--)
{
//因為這里已經減了一次,所以不再需要num-1;
*((char*)dest + num) = *((char*)src + num);
}
}
else
{
while(num--)
{
*(char*)dest = *(char*)src;
++(char*)dest;
++(char*)src;
}
}
return ret;
}
有人會問:那么我偏要用memcpy進行重疊空間試試,行嘛??行!!!
在最底層,
memcpy實際上是與memmove一模一樣的.都可以復制 重疊行與非重疊性的空間,但是為什么我們要弄兩個呢>解釋:
在c語言標準里面:
memcpy只需要實作不重疊空間復制
memmove只需要實作重疊空間復制懂了嗎???也就是說,他們都是超額完成了自己任務,我們去模擬,只是為了掌握演算法與思想
所以才分開了memcpy與memmove進行模擬
memcmp`的使用與模擬
官方檔案:
int memcmp ( const void * ptr1, const void * ptr2, size_t num );第一個引數: 目的地地址
第二個引數: 源目標地址
第三個引數: 直接數量
使用: 與前面所講的大致一樣.不再一 一贅述,此處只講模擬.在模擬之前建議再看看此文上面的
strcmp,有異曲同工之妙
memcmp模擬
int my_memcmp(const void * ptr1, const void * ptr2, size_t num)
{
while(num-- && (*(char*)ptr1 == *(char*)ptr2))
{
++(char*)ptr1;
++(char*)ptr2; //為什么前置++,之前strcmp講解過
}
return *(char*)ptr1 - *(char*)ptr2;
}
memset的使用及注意事項
官方檔案:
void * memset ( void * ptr, int value, size_t num );第一個引數: 目標地址
第二個引數: 某個確定的字符
第三個引數: 位元組數量.
使用:
#include <stdio.h>
#include <string.h>
int main()
{
char str[10];
memset(str,'*',sizeof(str));
for(int i = 0;i<10;i++)
{
printf("%c ",str[i]);
}
return 0;
}
結果: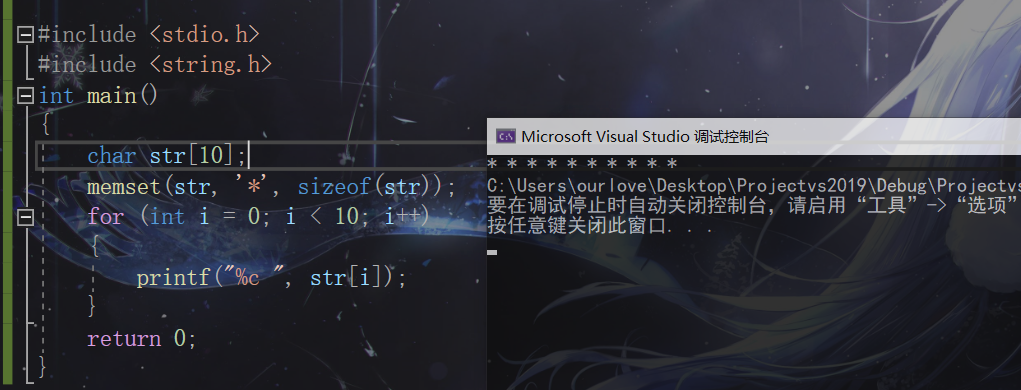
錯誤使用注意事項:
#include <stdio.h>
#include <string.h>
int main()
{
char str[10];
int num[10];
memset(str,10,sizeof(str));
memset(num,10,sizeof(str));
printf("這是字符陣列內容--------------------------------\n")
for(int i = 0;i<10;i++)
{
printf("%d ",str[i]);
}
printf("這是整型陣列內容--------------------------------\n")
for(int i = 0;i<10;i++)
{
printf("%d ",num[i]);
}
return 0;
}
結果:
會發現整型陣列與我們想象的不一樣,因為一個整型陣列是4個位元組.
而memset是針對位元組操作的.所以注意,一般我們只是用于整型陣列初始化為0,或者-1,這才是準確的
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/280731.html
標籤:其他