集合是一種容器物件,是用來存盤物件的,或者說存盤的都是物件的參考,并不是直接存盤的物件,而是存盤的物件的記憶體地址,需要注意的是,集合中不能存盤基本資料型別,即使是代碼中往集合中添加了基本資料型別,那也是進行了自動裝箱之后才放入集合的,
需要注意的是,Java中每一種不同的集合,底層會對應不同的資料結構,所以應該根據實際情況選擇使用合適的集合型別,
所有的集合都在“java.util”中,匯入的時候去util包里找即可,
注:集合的定義中會經常看到<E>等尖括號表示的語法,這是泛型的定義,表示可以根據需要傳入自己需要的型別,如果不傳入,默認就是Object型別,即如果傳入指定的型別,則集合中只能存盤指定的型別,否則集合中可以存盤Object類的所有子型別,
1、Collection集合繼承結構
Collection型別的集合特點是以單個物件的個體方式存盤元素,
java.lang.Object --> java.util.AbstractCollection<E>這個類實作了以下兩個介面:
- Iterable<E>:這個介面用于獲取遍歷集合所需要的迭代器,
- Collection<E>:這是所有集合的超級父介面,里面定義許多集合通用的方法,
Collection<E>介面中的常用方法:
- boolean add(E e):向集合末尾添加一個元素,
- int size():回傳集合中元素的個數,注意,不是回傳集合的容量,而是實際存盤的元素個數,
- void clear():清空集合中的所有元素,
- boolean contains(Object o):判斷當前集合中是否包含某個元素,這個方法其實是呼叫了元素o物件的equals方法來比較集合中的每個元素,如果有回傳true的結果,則contains方法則回傳true,否則回傳false,
- boolean remove(Object o):洗掉集合中的某個元素,這個方法也會呼叫o物件的equals方法來進行判斷,
- boolean isEmpty():判斷集合是否為空,
- Iterator<E> iterator():回傳一個迭代器,需要注意的是,回傳的迭代器一開始并沒有直接就指向了第一個元素,另一個需要注意的點,就是集合的結構或者內容發生改變時,迭代器也需要重新獲取,所以如果在迭代的程序中需要洗掉元素,那么就不能使用集合物件本身的remove方法,需要使用迭代器自身的remove方法,(回傳的迭代器從原理上可以理解為當前集合狀態的一個快照,迭代的時候只是會參照這個快照進行迭代,所以如果集合本身發生了變化,那么就和快照不一致了,此時再按照快照的狀態去迭代集合元素就會發生例外,)
- 注:因為contains和remove方法都會用到equals方法,所以需要保證往集合中添加的元素都已經重寫了equals方法,特別是自己定義的物件,
Iterator<E> iterator()中常用的方法:
- boolean hasNext():如果仍有元素可以迭代,則回傳true,否則回傳false,
- E next():回傳迭代的下一個元素,這里需要注意,如果沒有指定泛型,回傳值型別是Object,雖然存盤資料的時候可能是別的具體型別,但是獲取資料的時候必須是Object,
- default void remove():洗掉迭代器指向的當前元素,即next方法回傳的那個元素,(原理可以理解是,先洗掉快照中的當前元素,然后再同步洗掉集合中對應的元素,)
- 注:通常先使用hasNext方法判斷是否可以繼續迭代,如果可以就使用next方法回傳下一個元素, 注意,通過Iterator()方法付訓傳的迭代器并沒有指向第一個元素,只有使用next方法之后才會指向第一個元素并往后迭代,)
Collection<E>介面下常用的子介面:
- List<E>:這個介面下的集合的特點是集合元素有序可重復,并且可以通過下標訪問集合元素,實作這個介面的常用的類有ArrayList、LinkedList和Vector,
- Set<E>:這個介面下的集合的特點是集合元素無序不可重復,并且不可以通過下標訪問集合元素,實作這個介面的常用的類有HashSet和TreeSet,
List<E>介面中的常用方法:
- boolean add(E e):在集合末尾添加一個元素,
- void add(int index, E element):在串列的指定位置添加一個元素,這個方法使用的較少,因為效率較低,
- E get(int index):獲取指定位置的元素,
- int indexOf(Object o):獲取某個元素第一次出現的索引,
- int lastIndexOf(Object o):獲取某個元素最后一次出現的索引,
- E remove(int index):洗掉指定位置的元素,
- E set(int index, E element):修改指定位置的元素,
2、Map集合繼承結構
Map型別的集合特點是以key和value鍵值對的方式來存盤集合元素的,即一個鍵值對算作一個集合元素,
java.util.Map<K,?V>介面中常用的方法:
- V put(K key, V value):向Map集合中添加一個鍵值對,
- V get(Object key):通過key獲取value,
- void clear():清空Map集合,
- boolean containsKey(Object key):判斷Map集合中是否包含某個key,注意底層方法都是呼叫的equals方法比對的,
- boolean containsValue(Object value):判斷Map集合中是否包含某個value,注意底層方法都是呼叫的equals方法比對的,
- boolean isEmpty():判斷Map集合中元素個數是否為0,
- Set<K> keySet():獲取Map集合中所有的key,
- Collection<V> values():獲取集合中所有的value,
- V remove(Object key):通過key洗掉鍵值對,
- int size():獲取Map集合中鍵值對的個數,
- Set<Map.Entry<K, V>> entrySet():將Map集合轉換為Set集合,Set集合中元素的型別是“Map.Entry<K, V>”,相當于是將Map集合中每個元素的key和value聯合起來當成了Set集合中的一個元素了,
java.util.Map<K,?V>介面的常用實作類:
- HashMap<K,?V>:這是Map下常用的集合,特點是集合的key無序不可重復,但是value可以重復,
- Hashtable<K,?V> --> Properties:Hashtable本身和HashMap的作用類似,但是Hashtable是執行緒安全的,由于這個執行緒安全的實作方式導致效率較低,所以用的較少了,用的較多的是它的子類Properties,
- SortedMap<K,?V> --> TreeMap<K,?V>:TreeMap<K,?V>也是一個Map集合下常用的集合,特點是除了集合的key無序不可重復外,由于實作了SortedMap<K,?V>介面,集合的key在存放進去后會自動排序,
3、ArrayList<E>
特點:集合元素有序可重復,可通過下標訪問集合元素,并且是非執行緒安全的,
方法:Collection<E>和List<E>介面中的方法ArrayList<E>都可以使用,
執行緒安全:如果想要將ArrayList<E>變為執行緒安全的,可以通過“java.util.Collections”的synchronizedList(yourList)方法將你的ArrayList物件傳入,之后的ArrayList就會變成執行緒安全的了,
底層原理:ArrayList底層采用的是Object型別陣列的資料結構,創建物件時可以傳入陣列的大小,如果沒有傳入陣列大小,則會在初始化時創建一個空串列,然后在第一次往里面添加資料時才會創建一個大小為10的陣列,在往陣列中添加資料時,如果容量滿了,那么陣列會自動進行擴容,并且擴容之后的陣列容量為原容量的1.5倍,
優缺點:就和陣列的優缺點一樣,查詢效率很快,往末尾添加資料也很快,但是隨機增刪元素的效率較低,所以使用的使用應該盡量避免隨機增刪以及擴容的操作,
使用示例:
import java.util.ArrayList; import java.util.Iterator; import java.util.List; public class GenericTest { public static void main(String[] args) { // 指定集合中的元素型別為Pet,不能存盤其它型別的元素 // 使用new的時候可以不用再傳入型別了,可以自動推斷,此時的運算式<>也稱為鉆石運算式 // 如果不指定泛型,也是可以的,默認就是Object型別 List<Pet> petList = new ArrayList<>(); Cat c = new Cat(); Dog d = new Dog(); petList.add(c); petList.add(d); // 迭代器的宣告也需要加上泛型的定義 Iterator<Pet> it = petList.iterator(); while (it.hasNext()) { // 原本next方法回傳值的型別為Object,使用泛型之后回傳的型別直接就是指定 // 的型別,不需要進行型別轉換了, Pet p = it.next(); p.play(); // 當然,如果要使用具體的子類物件的方法,還是需要轉型之后才能呼叫 if (p instanceof Cat){ Cat myCat = (Cat)p; myCat.sleep(); } if (p instanceof Dog){ Dog myDog = (Dog)p; myDog.bark(); } } /* 輸出結果: 寵物在玩耍! 貓咪在睡覺! 寵物在玩耍! 狗子在嚎叫! */ } } class Pet { public void play() { System.out.println("寵物在玩耍!"); } } class Cat extends Pet { public void sleep() { System.out.println("貓咪在睡覺!"); } } class Dog extends Pet { public void bark() { System.out.println("狗子在嚎叫!"); } }
4、LinkedList<E>
特點:集合元素有序可重復,可通過下標訪問集合元素,
方法:Collection<E>和List<E>介面中的方法ArrayList<E>都可以使用,
底層原理:底層采用的是雙向鏈表的資料結構,存盤的時候會將元素封裝到一個Node物件中,這個Node物件除了有元素本身外,還有兩個變數next和prev,用于下一個節點和上一個節點的地址,這樣就形成了一個“雙向”的鏈表了,雖然是鏈表,但是還是可以使用下標,但是不推薦使用下標進行查詢,因為每次查詢都得從頭結點開始,效率較低,
優缺點:查詢效率較低,因為每次都要從頭結點開始查詢,但是隨機增刪元素的效率較高,因為只會涉及到上一個節點和下一個節點中變數next和prev的修改,不會像陣列那樣會涉及到該元素之后的值的整體移動,所以在選擇使用上,如果隨機增刪的業務較多,應該使用LinkedList,如果需要往集合中頻繁的添加或查詢資料,就使用ArrayList,
容量:LinkedList因為是鏈表的資料結構,所以在記憶體空間上是沒有連續性的,并且也沒有容量的說法,剛開始都是空的,沒有任何元素,
5、Vector<E>
Vector和ArrayList一樣底層都是陣列的資料結構,在使用上也是一樣的,區別在于Vector是執行緒安全的,但是也是因為這點,導致效率較低,而ArrayList可以使用其他更好的方法來保證執行緒安全,所以Vector已經使用的較少了,
6、HashSet<E>
特點:集合元素無序不可重復,不可通過下標訪問集合元素,
方法:Collection<E>介面中的方法ArrayList<E>都可以使用,
底層原理:HashSet底層其實是采用HashMap型別來存盤元素的,不過只是用到了HashMap的key部分,value部分并沒有用到,HashMap的key本身就是無序不可重復的,所以可以看成是HashMap所有的Key組成了一個HashSet,所以想要更好的理解HashSet,參見HashMap部分的筆記,
7、TreeSet<E>
特點:集合元素無序不可重復,不可通過下標訪問集合元素,但是存放到集合中的資料都是按升序自動排好序的,
方法:Collection<E>介面中的方法ArrayList<E>都可以使用,
底層原理:由于TreeSet實作了SortedSet,所以存放進去的元素都是排好序的,“無序不可重復”中的無序指的是存入進去的順序和取出來的順序不一致,這和存入進去之后自動排序是不一樣的,不要搞混了,和HashSet類似,TreeSet底層其實使用Map下的TreeMap來存盤資料的,它也是只用到了TreeMap的key部分,沒有用到value部分,所以理解TreeSet,可以參見TreeMap部分的筆記,
自動排序:為了改變自動升序為自動降序排列,或者存盤自定義的型別的時候,需要重寫或自定義TreeSet的排序機制,特別是自定義的型別,如果沒有同時定義好排序機制的話是會報錯的,自定義排序機制為:給這個自定義的類實作“java.lang.Comparable”介面或者自定義一個比較器“java.util.Comparator”,示例如下:
import java.util.Comparator; import java.util.TreeSet; public class TreeSetTest { public static void main(String[] args) { User u1 = new User(10); User u2 = new User(30); User u3 = new User(20); // 默認使用無參構造方法,即比較器為null,此時需要在類中實作Comparable介面的compareTo方法 TreeSet<User> ts = new TreeSet<>(); // 也可以自定義一個比較器,傳入構造方法 // TreeSet<User> ts = new TreeSet<>(new UserComparator()); ts.add(u1); ts.add(u2); ts.add(u3); for (User u : ts){ System.out.println(u); } } } /* 如果是需要往TreeSet中添加,則需要實作Comparable介面,并重寫compareTo方法 */ class User implements Comparable<User>{ int age; public User(){ } public User(int age){ this.age = age; } /* 排序會根據compareTo方法回傳大于0、小于0或者等于0三種情況進行排序 可根據自身需要根據三種結果進行自定義排序的規則的撰寫 */ public int compareTo(User u){ return this.age - u.age; } public String toString(){ return "User: " + age; } } /* 構造器需要實作Comparator介面,并重寫compare方法 */ class UserComparator implements Comparator<User>{ public int compare(User u1, User u2){ return u1.age - u2.age; } }
8、HashMap<K,?V>
特點:使用鍵值對存盤資料,key無序不可重復,value是可以重復的,并且是非執行緒安全的,
底層原理:HashMap的底層其實是哈希表或者說散串列的資料結構,而這個哈希表又是由陣列和單向鏈表或者紅黑樹組成,初始化時它是單向鏈表,當添加的元素導致單向鏈表的節點數超過8個時,就會自動轉換為紅黑樹,而紅黑樹的節點數如果少于了6個,又會自動轉換為單向鏈表,之所以這樣實作,還是想要更加快速地對集合元素進行查詢,陣列部分其實是一個Node型別的一位陣列,每個元素都是一個Node物件,Node物件有“final int hash”、“final K key”、“V value”、“Node<K, V> next”四個基本屬性,其中hash表示是將key通過從Object重寫的hashCode方法回傳的哈希值,并且這個hash值在底層可以通過另外的哈希演算法(這個演算法不需要關注)得到對應的陣列下標,即這個hash值可以看成是和陣列下標對應的,或者直接將他看成陣列下標也行,next則表示下一個節點的記憶體地址,以最開始的陣列和單向鏈表為例,使用put方法和get方法更加詳細的說明HashMap的原理,
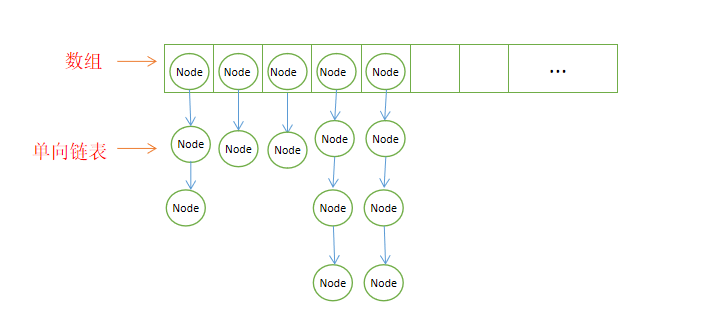
put方法原理:當執行put方法將一個鍵值對存入HashMap集合時,會按照以下步驟執行:
- 第一步:先將key和value封裝到Node物件中,然后底層會呼叫key的hashCode方法(這個方法就是Object類中繼承來并重寫的方法)得到hash值,此時Node物件中有三個值已經初始化好了:key,value和hash值,另一個next為空,
- 第二步:將hash值通過底層另外的哈希演算法轉換為陣列的下標,如果陣列對應下標位置沒有任何元素,就把此Node物件添加到這個位置上,如果下標對應的位置上已經有了元素,那么就會此Node物件的key去和此位置對應的鏈表從頭結點一個一個挨著去使用equals方法進行匹配,如果所有節點的equals方法都回傳false,那么就將此Node節點添加到鏈表的末尾,否則就將equals方法回傳true的節點的value覆寫掉,
get方法原理:當使用一個key值通過get方法獲取對應的value時,會按照以下步驟執行:
- 第一步:先呼叫key的hashCode()方法得出hash值,然后通過底層另外的哈希演算法得出陣列的下標,
- 第二步:然后通過這個下標快速定位到陣列的對應位置上,如果這個位置上什么也沒有,則回傳null,否則就會使用key在對應位置的單向鏈表上從頭結點開始一個節點一個節點的使用equals方法去比較對應節點的key,如果有一個節點的equals方法回傳true,則回傳對應的value,否則,如果所有的節點都回傳false最后的結果就直接回傳null,
hashCode()和equals()方法重寫:由以上put和get的實作原理可以看出,同一個陣列位置的單向鏈表上的所有節點的hash值都是相同的,但是key的equals方法回傳值肯定是不同的,同時也可以發現,使用HashMap時,key物件需要重寫兩個方法,hashCode()和equals()方法,重寫hashCode方法時需要注意以下內容:
- 如果hashCode方法固定回傳一個值,那么最終的結果就是只有一個單向鏈表,這種情況也稱之為散列分布不均勻,
- 如果hashCode方法每一個物件都回傳不同的值,那么就導致陣列的每個位置上都只有一個元素,這肯定也是不行的,變成了單純的一維陣列了,沒有單向鏈表了,
- 重寫hashCode時應該盡量保證散列均勻,比如100個物件回傳10個hashCode值,這就是散列均勻的,
- 注:但是不用擔心,hashCode()和equals()這兩個方法的重寫大部分情況都可以通過IDEA工具自動生成,不用我們手動撰寫,
陣列容量:HashMap集合的默認容量是16,默認加載因子是0.75,表示默認的陣列長度為16,當實際的陣列使用達到容量的75%時就會進行自動擴容,擴容之后的容量是原容量的2倍,也可以在初始化時指定容量大小,但是官方推薦初始化容量最好是2的倍數,不然會影響HashMap的執行效率,
使用示例:
import java.util.HashMap; import java.util.Map; import java.util.Set; public class MapTest { public static void main(String[] args) { Map<Integer, String> map = new HashMap<>(); map.put(1, "張三"); map.put(2, "李四"); // 通過key遍歷Map中的鍵值對 Set<Integer> keys = map.keySet(); for (Integer key : keys) { String value = map.get(key); System.out.println(key + "=" + value); } // 通過Set<Map.Entry<Integer, String>>直接遍歷Map中的鍵值對 // 如果記憶體允許,這種方式效率會比較高,適合大資料量的遍歷 Set<Map.Entry<Integer, String>> es = map.entrySet(); for (Map.Entry<Integer, String> node : es){ System.out.println(node.getKey() + "=" + node.getValue()); } } }
9、Hashtable<K,?V> 和Properties
Hashtable和HashMap的使用相似的,區別在于Hashtable是執行緒安全的,而后者是非執行緒安全的,但是和Vector的情況一樣,Hashtable執行緒安全的實作方式導致了效率較低的問題,所以使用的較少了,
Hashtable的一個子類Properties相比而言要常用一點,Properties也是執行緒安全的,Properties物件也稱之為屬性物件,它的特點是key和value都只支持String型別,常用的方法有:
- Object setProperty(String key, String value):呼叫Hashtable的put方法,
- String getProperty(String key):獲取指定key的value,如果沒有則回傳null,
- String getProperty(String key, String defualtValue):獲取指定key的value,如果沒有查找到則回傳defualtValue,
注:Properties的在“Java筆記:IO流” 筆記的最后“10. io和Properties聯合使用以讀取組態檔”有一個使用示例,可以參考下,
10、TreeMap<K,?V>
特點:使用鍵值對存盤資料,key無序不可重復,value是可以重復的,并且存入之后會按key升序自動排序,
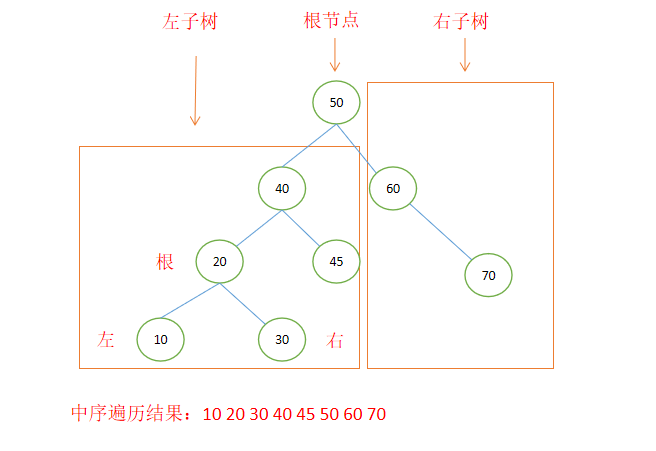
底層原理:TreeMap實作了SortedMap<K,?V>介面,并且底層其實是自平衡二叉樹的資料結構,這種資料結構遵循左小右大的原則存放資料,存入的key和value其實是封裝到了一個Entry<K,V>節點物件中,這個節點物件除了存入的key和value,還有三個變數left、right和parent用于存放左子節點、右子節點和父節點的記憶體地址,這樣就剛好形成一個二叉樹,遍歷這個二叉樹時,通常有三種方式:前序遍歷(根左右)、中序遍歷(左根右)和后序遍歷(左右根),這個“前中后”指的是根(節點)相對于“左右”的位置或者說遍歷中的順序,對于中序遍歷,特點是遍歷出來的資料自動就是從小到大排序的,
11、Collections工具類
這個類專門定義了一些方便集合操作的方法,常用的有:
- synchronizedList:將一個非執行緒安全的串列變為執行緒安全的,
- sort:將一個串列排序,注意,這個介面需要排序的元素實作了Comparable介面,不然會報錯,
- sort(List集合, 比較器):這種方式就不用實作Comparable介面了,但是需要提供一個比較器,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/167443.html
標籤:Java