學習目的
了解爬蟲,爬蟲起源;
爬蟲是什么
專業術語:網路爬蟲(又被稱為網頁蜘蛛,網路機器人)
網路爬蟲,是一種按照一定的規則,自動的抓取萬維網資訊的程式或者腳本,
爬蟲起源(產生背景)
隨著網路的迅速發展,萬維網成為大量資訊的載體,如何有效地提取并利用這些資訊成為一個巨大的挑戰;
搜索引擎有Yahoo,Google,百度等,作為一個輔助人們檢索資訊的工具成為用戶訪問萬維網的入口和指南
網路爬蟲是搜索引擎系統中十分重要的組成部分,它負責從互聯網中搜集網頁,采集資訊
這些網頁資訊用于建立索引從而為搜索 引擎提供支持,它決定著整個引擎系統的內容是否豐富,資訊是否即時,因此其性能的優劣直接影響著搜索引擎的效果,
網路爬蟲程式的優劣,很大程度上反映了一個搜索引擎的好差,
不信,你可以隨便拿一個網站去查詢一下各家搜索對它的網頁收錄情況,爬蟲強大程度跟搜索引擎好壞基本成正比,
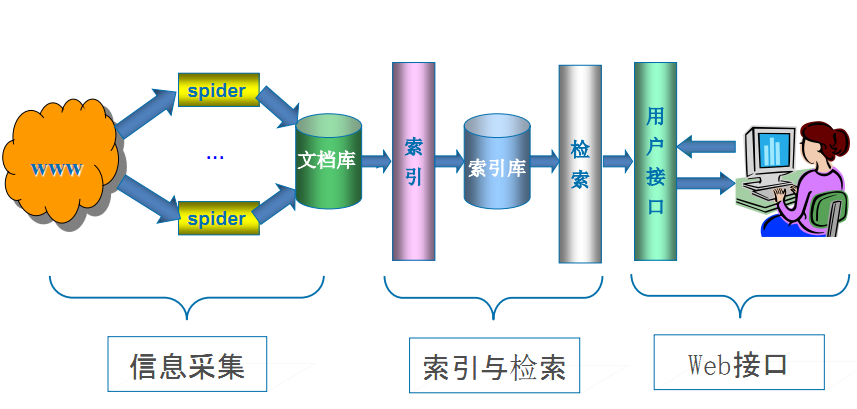
搜索引擎作業原理
第一步:抓取網頁(爬蟲)
搜索引擎是通過一種特定規律的軟體跟蹤網頁的鏈接,從一個鏈接爬到另外一個鏈接,像蜘蛛在蜘蛛網上爬行一樣,所以被稱為“蜘蛛”也被稱為“機器人”,搜索引擎蜘蛛的爬行是被輸入了一定的規則的,它需要遵從一些命令或檔案的內容,
Robots協議(也稱為爬蟲協議、機器人協議等)的全稱是“網路爬蟲排除標準”(Robots Exclusion Protocol),網站通過Robots協議告訴搜索引擎哪些頁面可以抓取,哪些頁面不能抓取
https://www.taobao.com/robots.txt http://www.qq.com/robots.txt https://www.taobao.com/robots.txt
第二步:資料存盤
搜索引擎是通過蜘蛛跟蹤鏈接爬行到網頁,并將爬行的資料存入原始頁面資料庫,其中的頁面資料與用戶瀏覽器得到的HTML是完全一樣的,搜索引擎蜘蛛在抓取頁面時,也做一定的重復內容檢測,一旦遇到權重很低的網站上有大量抄襲、采集或者復制的內容,很可能就不再爬行,
第三步:預處理
搜索引擎將蜘蛛抓取回來的頁面,進行各種步驟的預處理,
⒈提取文字⒉中文分詞⒊去停止詞⒋消除噪音(搜索引擎需要識別并消除這些噪聲,比如著作權宣告文字、導航條、廣告等……)5.正向索引6.倒排索引7.鏈接關系計算8.特殊檔案處理
除了HTML檔案外,搜索引擎通常還能抓取和索引以文字為基礎的多種檔案型別,如 PDF、Word、WPS、XLS、PPT、TXT 檔案等,我們在搜索結果中也經常會看到這些檔案型別,
但搜索引擎還不能處理圖片、視頻、Flash 這類非文字內容,也不能執行腳本和程式,
第四步:排名,提供檢索服務
但是,這些通用性搜索引擎也存在著一定的局限性,如:
(1)不同領域、不同背景的用戶往往具有不同的檢索目的和需求,通用搜索引擎所回傳的結果包含大量用戶不關心的網頁,
(2)通用搜索引擎的目標是盡可能大的網路覆寫率,有限的搜索引擎服務器資源與無限的網路資料資源之間的矛盾將進一步加深,
(3)萬維網資料形式的豐富和網路技術的不斷發展,圖片、資料庫、音頻、視頻多媒體等不同資料大量出現,通用搜索引擎往往對這些資訊含量密集且具有一定結構的資料無能為力,不能很好地發現和獲取,
(4)通用搜索引擎大多提供基于關鍵字的檢索,難以支持根據語意資訊提出的查詢,
為了解決上述問題,定向抓取相關網頁資源的聚焦爬蟲應運而生,聚焦爬蟲是一個自動下載網頁的程式,它根據既定的抓取目標,有選擇的訪問萬維網上的網頁與相關的鏈接,獲取所需要的資訊,
與通用爬蟲(general purpose web crawler)不同,聚焦爬蟲并不追求大的覆寫,而將目標定為抓取與某一特定主題內容相關的網頁,為面向主題的用戶查詢準備資料資源,
聚焦爬蟲作業原理以及關鍵技術概述
網路爬蟲是一個自動提取網頁的程式,它為搜索引擎從萬維網上下載網頁,是搜索引擎的重要組成,
傳統爬蟲從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,在抓取網頁的程序中,不斷從當前頁面上抽取新的URL放入佇列,直到滿足系統的一定停止條件,
聚焦爬蟲的作業流程較為復雜,需要根據一定的網頁分析演算法過濾與主題無關的鏈接,保留有用的鏈接并將其放入等待抓取的URL佇列,
然后,它將根據一定的搜索策略從佇列中選擇下一步要抓取的網頁URL,并重復上述程序,直到達到系統的某一條件時停止,
另外,所有被爬蟲抓取的網頁將會被系統存貯,進行一定的分析、過濾,并建立索引,以便之后的查詢和檢索;對于聚焦爬蟲來說,這一程序所得到的分析結果還可能對以后的抓取程序給出反饋和指導,
相對于通用網路爬蟲,聚焦爬蟲還需要解決三個主要問題:
(1) 對抓取目標的描述或定義;
(2) 對網頁或資料的分析與過濾;
(3) 對URL的搜索策略,
抓取目標的描述和定義是決定網頁分析演算法與URL搜索策略如何制訂的基礎,而網頁分析演算法和候選URL排序演算法是決定搜索引擎所提供的服務形式和爬蟲網頁抓取行為的關鍵所在,這兩個部分的演算法又是緊密相關的,
網路爬蟲的發展趨勢
隨著AJAX/Web2.0的流行,如何抓取AJAX等動態頁面成了搜索引擎急需解決的問題,如果搜索引擎依舊采用“爬”的機制,是無法抓取到AJAX頁面的有效資料的,對于AJAX這樣的技術,所需要的爬蟲引擎必須是基于驅動的,而如果想要實作事件驅動,首先需要解決以下問題:
第一:JavaScript的互動分析和解釋;
第二:DOM事件的處理和解釋分發;
第三:動態DOM內容語意的抽取,
爬蟲發展的幾個階段(博士論文copy)
第一個階段可以說是早期爬蟲,斯坦福的幾位同學完成的抓取,當時的互聯網基本都是完全開放的,人類流量是主流;
第二個階段是分布式爬蟲,但是爬蟲面對新的問題是資料量越來越大,傳統爬蟲已經解決不了把資料都抓全的問題,需要更多的爬蟲,于是調度問題就出現了;
第三階段是暗網爬蟲,此時面對新的問題是資料之間的link越來越少,比如淘寶,點評這類資料,彼此link很少,那么抓全這些資料就很難;還有一些資料是需要提交查詢詞才能獲取,比如機票查詢,那么需要尋找一些手段“發現”更多,更完整的不是明面上的資料,
第四階段智能爬蟲,這主要是爬蟲又開始面對新的問題:社交網路資料的抓取,
社交網路對爬蟲帶來的新的挑戰包括
有一條賬號護城河
我們通常稱UGC(User Generated Content)指用戶原創內容,為web2.0,即資料從單向傳達,到雙向互動,人民群眾可以與網站產生互動,因此產生了賬號,每個人都通過賬號來標識身份,提交資料,這樣一來社交網路就可以通過封賬號來提高資料抓取的難度,通過賬號來發現非人類流量,
之前沒有賬號只能通過cookie和ip,cookie又是易變,易揮發的,很難長期標識一個用戶,
網路走向封閉
新浪微博在2012年以前都是基本不封的,隨便寫一個程式怎么抓都不封,但是很快,越來越多的站點都開始防止競爭對手,防止爬蟲來抓取,資料逐漸走向封閉,越來越多的人難以獲得資料,甚至都出現了專業的爬蟲公司,這在2010年以前是不可想象的,,
反爬手段,封殺手法千差萬別
寫一個通用的框架抓取成百上千萬的網站已經成為歷史,或者說已經是一個技術相對成熟的作業,也就是已經有相對成熟的框架來”盜“成百上千的墓,但是極個別的墓則需要特殊手段了,目前市場上比較難以抓取的資料包括,微信公共賬號,微博,facebook,ins,淘寶等等,
具體原因各異,但基本無法用一個統一框架來完成,太特殊了,如果有一個通用的框架能解決我說的這幾個網站的抓取,這一定是一個非常震撼的產品,如果有,一定要告訴我,那我公開出來,然后就改行了,
當面對以上三個挑戰的時候,就需要智能爬蟲,智能爬蟲是讓爬蟲的行為盡可能模仿人類行為,讓反爬策略失效,只有”混在老百姓隊伍里面,才是安全的“,因此這就需要琢磨瀏覽器了,很多人把爬蟲寫在了瀏覽器插件里面,把爬蟲寫在了手機里面,寫在了路由器里面(春節搶票王),
再有一個傳統的爬蟲都是只有讀操作的,沒有寫操作,這個很容易被判是爬蟲,智能的爬蟲需要有一些自動化互動的行為,這都是一些抵御反爬策略的方法,
從商業價值上,是一個能夠抽象千百萬網站抓取框架的爬蟲工程師值錢,還是一個能抓特定難抓網站的爬蟲工程師值錢?
能花錢來買,被市場認可的資料,都是那些特別難抓的,抓取成本例外高的資料,
目前市場上主流的爬蟲工程師,都是能夠抓成百上千網站的資料,但如果想有價值,還是得有能力抓特別難抓的資料,才能估上好價錢,

IT入門 感謝關注 | 練習地址:www.520mg.com/it
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/167650.html
標籤:Python
下一篇:提升Python性能的7個習慣