kafka的安裝機器命令:
https://www.cnblogs.com/qingyunzong/p/9005062.html
kafka特點:
1.高吞吐量,支持高并發,支持訊息磁區,和分布式系統,同時保證每個partition內的訊息順序傳輸,提供訊息持久化能力,
2.Kafka就是一種發布-訂閱模式, 消費者可以訂閱一個或多個topic,消費者可以消費該topic中所有的資料,同一條資料可以被多個消費者消費,資料被消費后不會立馬洗掉,
優點: 解耦,可開拓展性,冗余(記錄訊息id,更新狀態,保證這條id訊息一定被消費)等等,
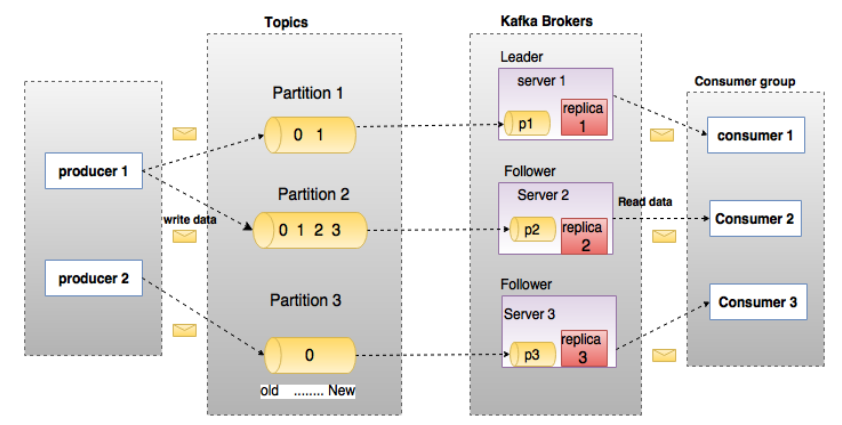
上圖中一個topic配置了3個partition,Partition1有兩個offset:0和1,Partition2有4個offset,Partition3有1個offset,
如果一個topic的副本數為3,那么Kafka將在集群中為每個partition創建3個相同的副本,集群中的每個broker存盤一個或多個partition,多個producer和consumer可同時生產和消費資料,
topic:每條發布到Kafka集群的訊息都有一個類別(理解為queue佇列),這個類別被稱為Topic,(物理上不同Topic的訊息分開存盤,邏輯上一個Topic的訊息雖然保存于一個或多個broker上但用戶只需指定訊息的Topic即可生產或消費資料而不必關心資料存于何處),
partition: 在topic中的資料分割為一個或多個partition,每個topic至少有一個partition,每個partition中的資料使用多個segment檔案存盤,partition中的資料是有序的,不同partition間的資料丟失了資料的順序,如果topic有多個partition,消費資料時就不能保證資料的順序,在需要嚴格保證訊息的消費順序的場景下,需要將partition數目設為1,
broker:Kafka 集群包含一個或多個服務器,服務器節點稱為broker, broker存盤topic的資料,如果某topic有N個partition,集群有N個broker,那么每個broker存盤該topic的一個partition,如果某topic有N個partition,集群中broker數目少于N個,那么一個broker存盤該topic的一個或多個partition,在實際生產環境中,盡量避免這種情況的發生,這種情況容易導致Kafka集群資料不均衡,
producer:生產者即資料的發布者,該角色將訊息發布到Kafka的topic中,broker接收到生產者發送的訊息后,broker將該訊息追加到當前用于追加資料的segment檔案中,生產者發送的訊息,存盤到一個partition中,生產者也可以指定資料存盤的partition,
consumer:消費者可以從broker中讀取資料,消費者可以消費多個topic中的資料,
consume group:每個Consumer屬于一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬于默認的group),同一Topic的一條訊息只能被同一個Consumer Group內的一個Consumer消費,但多個Consumer Group可同時消費這一訊息,
leader:每個partition有多個副本,其中有且僅有一個作為Leader,Leader是當前負責資料的讀寫的partition,
follower:Follower跟隨Leader,所有寫請求都通過Leader路由,資料變更會廣播給所有Follower,Follower與Leader保持資料同步,如果Leader失效,則從Follower中選舉出一個新的Leader,當Follower與Leader掛掉、卡住或者同步太慢,leader會把這個follower從“in sync replicas”(ISR)串列中洗掉,重新創建一個Follower,
offset:Kafka會為每一個Consumer Group保留一些metadata資訊——當前消費的訊息的position,也即offset,這個offset由Consumer控制,正常情況下Consumer會在消費完一條訊息后遞增該offset,當然,Consumer也可將offset設成一個較小的值,重新消費一些訊息,因為offet由Consumer控制,所以Kafka broker是無狀態的,它不需要標記哪些訊息被哪些消費過,也不需要通過broker去保證同一個Consumer Group只有一個Consumer能消費某一條訊息,因此也就不需要鎖機制,這也為Kafka的高吞吐率提供了有力保障,
Kafka提供兩種策略洗掉舊資料:
一是、基于時間,二是基于Partition檔案大小,例如可以通過配置$KAFKA_HOME/config/server.properties,讓Kafka洗掉一周前的資料,
二是、在Partition檔案超過1GB時洗掉舊資料,配置如下所示:
# The minimum age of a log file to be eligible for deletion log.retention.hours=168 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=1073741824 # The interval at which log segments are checked to see if they can be deleted according to the retention policies log.retention.check.interval.ms=300000 # If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction. log.cleaner.enable=false
三、Producer訊息路由:
Producer發送訊息到broker時,會根據Paritition機制選擇將其存盤到哪一個Partition,如果Partition機制設定合理,所有訊息可以均勻分布到不同的Partition里,這樣就實作了負載均衡,如果一個Topic對應一個檔案,那這個檔案所在的機器I/O將會成為這個Topic的性能瓶頸,而有了Partition后,不同的訊息可以并行寫入不同broker的不同Partition里,極大的提高了吞吐率,可以在$KAFKA_HOME/config/server.properties中通過配置項num.partitions來指定新建Topic的默認Partition數量,也可在創建Topic時通過引數指定,同時也可以在Topic創建之后通過Kafka提供的工具修改,
在發送一條訊息時,可以指定這條訊息的key,Producer根據這個key和Partition機制來判斷應該將這條訊息發送到哪個Parition,Paritition機制可以通過指定Producer的paritition. class這一引數來指定,該class必須實作kafka.producer.Partitioner介面,
四:Consumer Group:
這是Kafka用來實作一個Topic訊息的廣播(發給所有的Consumer)和單播(發給某一個Consumer)的手段,一個Topic可以對應多個Consumer Group,如果需要實作廣播,只要每個Consumer有一個獨立的Group就可以了,要實作單播只要所有的Consumer在同一個Group里,用Consumer Group還可以將Consumer進行自由的分組而不需要多次發送訊息到不同的Topic,
實際上,Kafka的設計理念之一就是同時提供離線處理和實時處理,根據這一特性,可以使用Storm這種實時流處理系統對訊息進行實時在線處理,同時使用Hadoop這種批處理系統進行離線處理,還可以同時將資料實時備份到另一個資料中心,只需要保證這三個操作所使用的Consumer屬于不同的Consumer Group即可,
訊息的冪等性:
At most once 訊息可能會丟,但絕不會重復傳輸
At least one 訊息絕不會丟,但可能會重復傳輸
Exactly once 每條訊息肯定會被傳輸一次且僅傳輸一次,很多時候這是用戶所想要的,
kafka默認保證At least once,并且允許通過設定Producer異步提交來實作At most once,而Exactly once要求與外部存盤系統協作,幸運的是Kafka提供的offset可以非常直接非常容易得使用這種方式,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/168204.html
標籤:Java