?一般來講對我們而言,需要抓取的是某個網站或者某個應用的內容,提取有用的價值,內容一般分為兩部分,非結構化的文本,或結構化的文本,
關于結構化的資料
JSON、XML、HTML
HTML文本(包含JavaScript代碼)是最常見的資料格式,理應屬于結構化的文本組織,但因為一般我們需要的關鍵資訊并非直接可以得到
需要進行對HTML的決議查找,甚至一些字串操作才能得到,所以還是歸類于非結構化的資料處理中,
把網頁比作一個人,那么HTML便是他的骨架,JS便是他的肌肉,CSS便是它的衣服,
常見決議方式如下:XPath、CSS選擇器、正則運算式
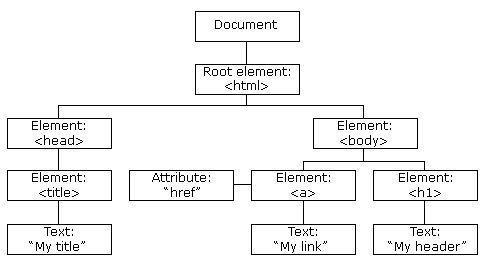
HTML DOM 示例
HTML DOM 定義了訪問和操作 HTML 檔案的標準方法,
DOM 以樹結構表達 HTML 檔案,
文本資料
例如一篇文章,或者一句話,我們的初衷是提取有效資訊,所以如果是滯后處理,可以直接存盤,如果是需要實時提取有用資訊,常見的處理方式如下:
-
分詞根據抓取的網站型別,使用不同詞庫,進行基本的分詞,然后變成詞頻統計,類似于向量的表示,詞為方向,詞頻為長度,
-
NLP自然語言處理,進行語意分析,用結果表示,例如正負面等,

IT入門 感謝關注 | 練習地址:www.520mg.com/it
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/168216.html
標籤:其他