CSS Selector
CSS(即層疊樣式表Cascading Stylesheet),
Selector來定位(locate)頁面上的元素(Elements),Selenium官網的Document里極力推薦使用CSS locator,而不是XPath來定位元素,原因是CSS locator比XPath locator速度快.
Beautiful Soup
-
支持從HTML或XML檔案中提取資料的Python庫
-
支持Python標準庫中的HTML決議器
-
還支持一些第三方的決議器lxml, 使用的是 Xpath 語法,推薦安裝,
Beautiful Soup自動將輸入檔案轉換為Unicode編碼,輸出檔案轉換為utf-8編碼,你不需要考慮編碼方式,除非檔案沒有指定一個編碼方式,這時,Beautiful Soup就不能自動識別編碼方式了,然后,你僅僅需要說明一下原始編碼方式就可以了
-
Beautiful Soup4 安裝
官方檔案鏈接:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
可以利用 pip來安裝
pip install beautifulsoup4
- 安裝決議器(上節課已經安裝過)
pip install lxml
-
Beautiful Soup支持Python標準庫中的HTML決議器,還支持一些第三方的決議器,其中一個是 lxml .根據作業系統不同,可以選擇下列方法來安裝lxml:
另一個可供選擇的決議器是純Python實作的 html5lib , html5lib的決議方式與瀏覽器相同,可以選擇下列方法來安裝html5lib:
pip install html5lib
下表列出了主要的決議器:
| 決議器 | 使用方法 | 優勢 | 劣勢 |
|---|---|---|---|
| Python標準庫 | BeautifulSoup(markup, "html.parser") | Python的內置標準庫;執行速度適中;檔案容錯能力強 | Python 2.7.3 or 3.2.2前 的版本中檔案容錯能力差 |
| lxml HTML 決議器 | BeautifulSoup(markup, "lxml") | 速度快;檔案容錯能力強 ; | 需要安裝C語言庫 |
| lxml XML 決議器 | BeautifulSoup(markup, ["lxml-xml"]) BeautifulSoup(markup, "xml") | 速度快;唯一支持XML的決議器 | 需要安裝C語言庫 |
| html5lib | BeautifulSoup(markup, "html5lib") | 最好的容錯性;以瀏覽器的方式決議檔案;生成HTML5格式的檔案 | 速度慢;不依賴外部擴展 |
推薦使用lxml作為決議器,因為效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必須安裝lxml或html5lib, 因為那些Python版本的標準庫中內置的HTML決議方法不夠穩定.
- 快速開始
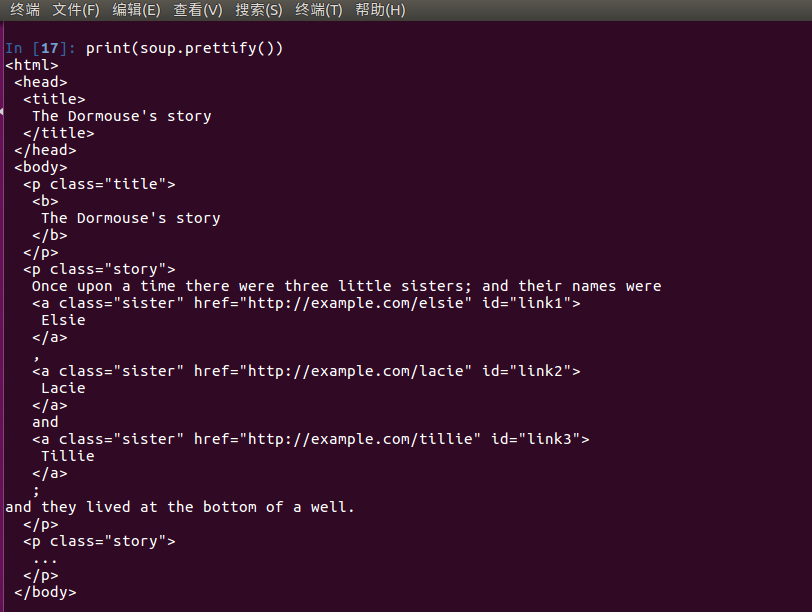
html_doc ="""
<html><head><title>The Dormouse's story</title></head>
<body>
<p ><b>The Dormouse's story</b></p>
<p >Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" id="link1">Elsie</a>,
<a href="http://example.com/lacie" id="link2">Lacie</a> and
<a href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p >...</p>
"""
使用BeautifulSoup決議這段代碼,能夠得到一個 BeautifulSoup 的物件,并能按照標準的縮進格式的結構輸出:
from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc,'lxml')
下面我們來列印一下 soup 物件的內容
print (soup)

格式化輸出soup 物件
print(soup.prettify())
CSS選擇器
在寫 CSS 時:
標簽名不加任何修飾 類名前加點 id名前加 #
利用類似的方法來篩選元素,用到的方法是 soup.select(),回傳型別是 list
- 通過標簽名查找
print (soup.select('title') )
#[<title>The Dormouse's story</title>]
?
print (soup.select('a'))
#[<a href="http://example.com/elsie" id="link1"></a>, <a href="http://example.com/lacie" id="link2">Lacie</a>, <a href="http://example.com/tillie" id="link3">Tillie</a>]
?
print (soup.select('b'))
#[<b>The Dormouse's story</b>]
- 通過類名查找
print (soup.select('.sister'))
# [<a href="http://example.com/elsie" id="link1"></a>, <a href="http://example.com/lacie" id="link2">Lacie</a>, <a href="http://example.com/tillie" id="link3">Tillie</a>]
- 通過 id 名查找
print(soup.select('#link1'))
# [<a href="http://example.com/elsie" id="link1"></a>]
- 直接子標簽查找
print (soup.select("head > title"))
#[<title>The Dormouse's story</title>]
-
組合查找
組合查找即標簽名與類名、id名進行的組合原理是一樣的,例如查找 p 標簽中,id 等于 link1的內容,
屬性和標簽不屬于同一節點 二者需要用空格分開
print (soup.select('p #link1'))
#[<a href="http://example.com/elsie" id="link1"></a>]
-
屬性查找
查找時還可以加入屬性元素,屬性需要用中括號括起來
注意屬性和標簽屬于同一節點,所以中間不能加空格,否則會無法匹配到
print (soup.select('a[]'))
#[<a href="http://example.com/elsie" id="link1"></a>, <a href="http://example.com/lacie" id="link2">Lacie</a>, <a href="http://example.com/tillie" id="link3">Tillie</a>]
print (soup.select('a[href="http://example.com/elsie"]'))
#[<a href="http://example.com/elsie" id="link1"></a>]
同樣,屬性仍然可以與上述查找方式組合,不在同一節點的空格隔開,同一節點的不加空格
print (soup.select('p a[href="http://example.com/elsie"]'))
#[<a href="http://example.com/elsie" id="link1"></a>]
以上的 select 方法回傳的結果都是串列形式,可以遍歷形式輸出
用 get_text() 方法來獲取它的內容,
print(soup.select('title')[0].get_text() )
for title in soup.select('title'):
print (title.get_text())
Tag
Tag 是什么?通俗點講就是 HTML 中的一個個標簽,例如
<a href="http://example.com/elsie" id="link1">Elsie</a>
print type(soup.select('a')[0])
輸出:
bs4.element.Tag
對于 Tag,它有兩個重要的屬性,是 name 和 attrs,下面我們分別來感受一下
- name
print (soup.name) print (soup.select('a')[0].name)
輸出:
[document] 'a'
soup 物件本身比較特殊,它的 name 即為 [document],對于其他內部標簽,輸出的值便為標簽本身的名稱,
- attrs
print (soup.select('a')[0].attrs)
輸出:
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
在這里,我們把 soup.select('a')[0] 標簽的所有屬性列印輸出了出來,得到的型別是一個字典,
如果我們想要單獨獲取某個屬性,可以這樣,例如我們獲取它的 class 叫什么
print (soup.select('a')[0].attrs['class'])
輸出:
['sister']
實戰
爬取豆瓣電影排行榜案例
https://movie.douban.com/chart
from bs4 import BeautifulSoup
import urllib.parse
import urllib.request
?
url='https://movie.douban.com/chart'
# 豆瓣排行榜
?
herders={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36', 'Referer':'https://movie.douban.com/','Connection':'keep-alive'}
# 請求頭資訊
?
req = urllib.request.Request(url,headers=herders)
# 設定請求頭
response=urllib.request.urlopen(req)
# response 是回傳回應的資料
htmlText=response.read()
# 讀取回應資料
?
?
# 把字串決議為html檔案
html = BeautifulSoup(htmlText,'lxml')
?
result = html.select(".pl2")
?
file = open('data.txt','a',encoding='utf-8')
# 打開一個文本檔案
?
# 遍歷幾個
for item in result:
str = ''
#宣告一個空的字串
str += item.select('a')[0].get_text().replace(' ','').replace("\n","")
# 獲取標題文字.替換掉空格.替換掉換行
str += '('
# 給評分加個左括號
str += item.select('.rating_nums')[0].get_text()
# 獲取評分
str += ')\n'
# 給評分加個右括號
print(str)
# 在控制臺輸出內容
file.write(str)
# 寫入檔案
?
?
file.close()
# 關閉檔案
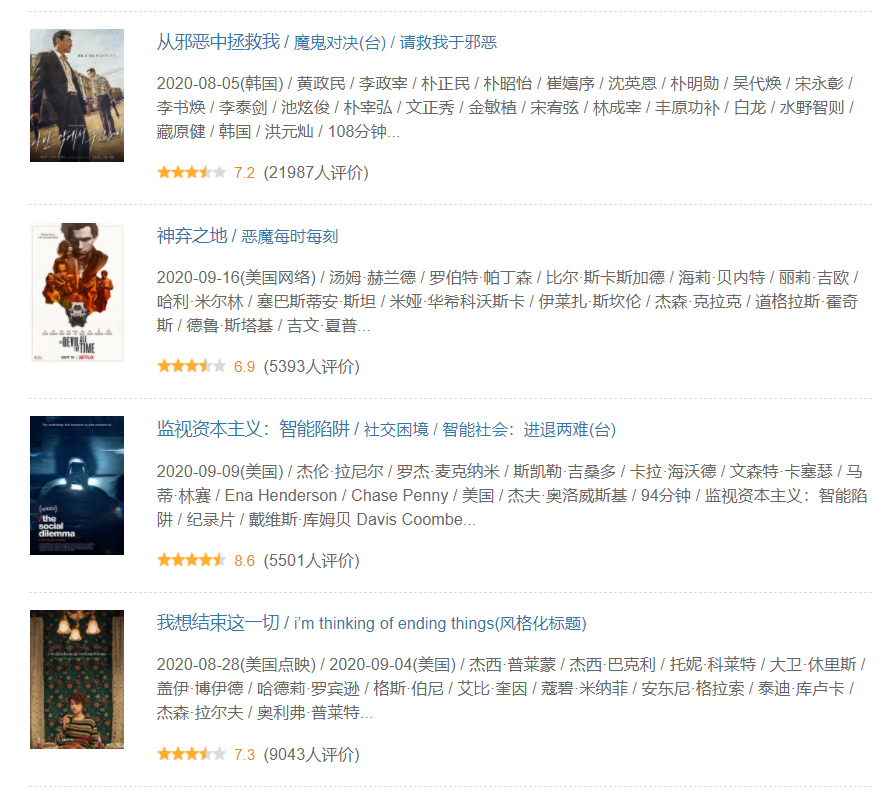
結果
從邪惡中拯救我/魔鬼對決(臺)/請救我于邪惡(7.2)
神棄之地/惡魔每時每刻(6.9)
監視資本主義:智能陷阱/社交困境/智能社會:進退兩難(臺)(8.6)
我想結束這一切/i’mthinkingofendingthings(風格化標題)(7.3)
禁錮之地/Imprisonment/TheTrapped(4.4)
鳴鳥不飛:烏云密布/SaezuruToriWaHabatakanai:TheCloudsGather(8.3)
樹上有個好地方/TheHomeintheTree(7.9)
辣手保姆2:女王蜂/撒旦保姆:血腥女王/TheBabysitter2(5.7)
凍結的希望/雪藏希望:待日重生/HopeFrozen:AQuestToLiveTwice(8.1)
鐵雨2:首腦峰會/鐵雨2:首腦會談/鋼鐵雨2:核戰危機(港)(5.8)
單詞表
"""
單詞表
Beautiful 美麗的
Soup 湯
url 統一資源定位器
lib library 庫
parse 決議
request 決議
respone 回應
select 選擇
open 打開
encoding 編碼
get_text 獲取文本
write 寫
close 關閉
問題?
好,這就是另一種與 XPath 語法有異曲同工之妙的查找方法,覺得哪種更方便?

IT入門 感謝關注 | 練習地址:www.520mg.com/it
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/168766.html
標籤:Python