1、為什么有訊息系統
-
解耦合
-
異步處理 例如電商平臺,秒殺活動,一般流程會分為:1:
風險控制、2:庫存鎖定、3:生成訂單、4:短信通知、5:更新資料通過訊息系統將秒殺活動業務拆分開,將不急需處理的業務放在后面慢慢處理;流程改為:1:風險控制、2:庫存鎖定、3:訊息系統、4:生成訂單、5:短信通知、6:更新資料 -
流量的控制 3.1 網關在接受到請求后,就把請求放入到訊息佇列里面 3.2 后端的服務從訊息佇列里面獲取到請求,完成后續的秒殺處理流程,然后再給用戶回傳結果,優點:控制了流量 缺點:會讓流程變慢
2、Kafka核心概念
生產者:Producer 往Kafka集群生成資料消費者:Consumer 往Kafka里面去獲取資料,處理資料、消費資料Kafka的資料是由消費者自己去拉去Kafka里面的資料主題:topic磁區:partition 默認一個topic有一個磁區(partition),自己可設定多個磁區(磁區分散存盤在服務器不同節點上)
3、Kafka的集群架構
Kafka集群中,一個kafka服務器就是一個broker Topic只是邏輯上的概念,partition在磁盤上就體現為一個目錄Consumer Group:消費組 消費資料的時候,都必須指定一個group id,指定一個組的id假定程式A和程式B指定的group id號一樣,那么兩個程式就屬于同一個消費組特殊: 比如,有一個主題topicA程式A去消費了這個topicA,那么程式B就不能再去消費topicA(程式A和程式B屬于一個消費組) 再比如程式A已經消費了topicA里面的資料,現在還是重新再次消費topicA的資料,是不可以的,但是重新指定一個group id號以后,可以消費,不同消費組之間沒有影響,消費組需自定義,消費者名稱程式自動生成(獨一無二),Controller:Kafka節點里面的一個主節點,借助zookeeper
4、Kafka磁盤順序寫保證寫資料性能
kafka寫資料:順序寫,往磁盤上寫資料時,就是追加資料,沒有隨機寫的操作,經驗: 如果一個服務器磁盤達到一定的個數,磁盤也達到一定轉數,往磁盤里面順序寫(追加寫)資料的速度和寫記憶體的速度差不多生產者生產訊息,經過kafka服務先寫到os cache 記憶體中,然后經過sync順序寫到磁盤上
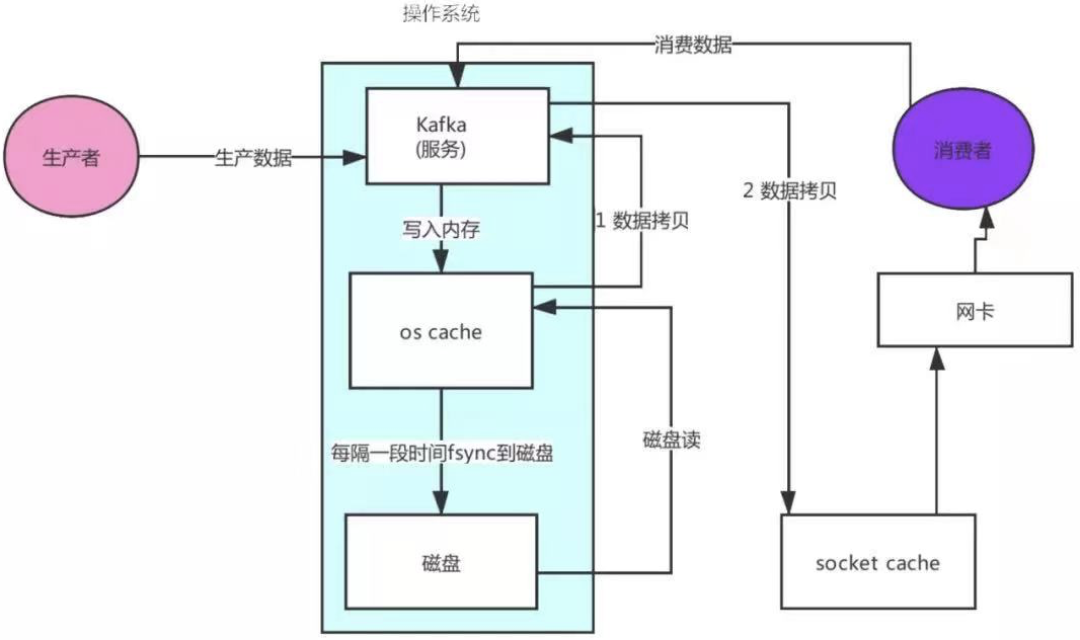
5、Kafka零拷貝機制保證讀資料高性能
消費者讀取資料流程:
-
消費者發送請求給kafka服務
-
kafka服務去os cache快取讀取資料(快取沒有就去磁盤讀取資料)
-
從磁盤讀取了資料到os cache快取中
-
os cache復制資料到kafka應用程式中
-
kafka將資料(復制)發送到socket cache中
-
socket cache通過網卡傳輸給消費者
kafka linux sendfile技術 — 零拷貝
1.消費者發送請求給kafka服務 2.kafka服務去os cache快取讀取資料(快取沒有就去磁盤讀取資料) 3.從磁盤讀取了資料到os cache快取中 4.os cache直接將資料發送給網卡 5.通過網卡將資料傳輸給消費者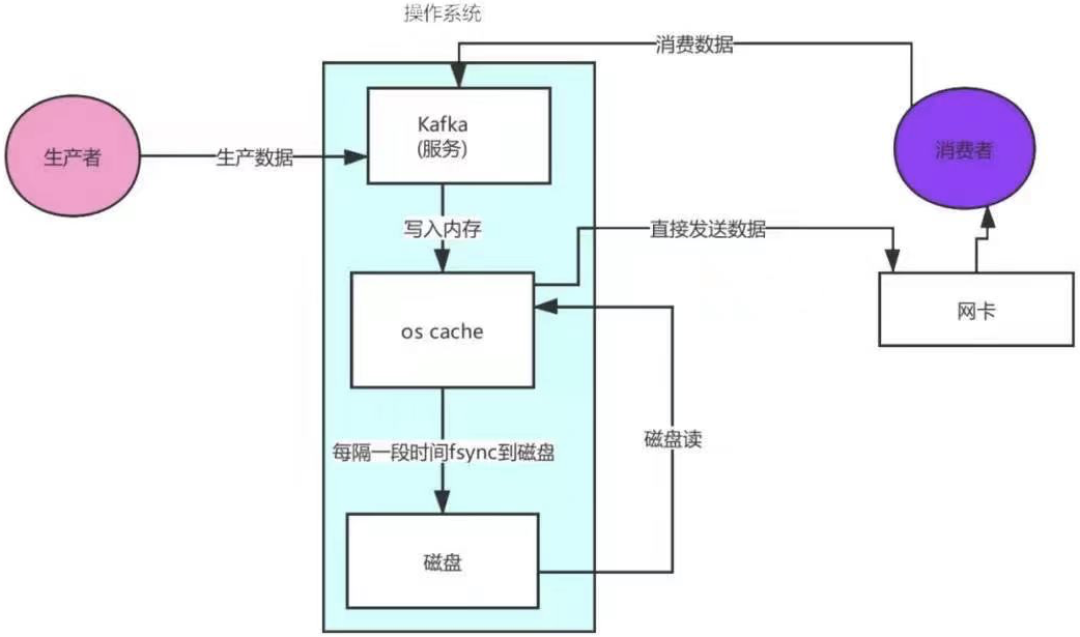
6、Kafka日志分段保存
Kafka中一個主題,一般會設定磁區;比如創建了一個topic_a,然后創建的時候指定了這個主題有三個磁區,其實在三臺服務器上,會創建三個目錄,服務器1(kafka1)創建目錄topic_a-0:,目錄下面是我們檔案(存盤資料),kafka資料就是message,資料存盤在log檔案里,.log結尾的就是日志檔案,在kafka中把資料檔案就叫做日志檔案 ,一個磁區下面默認有n多個日志檔案(分段存盤),一個日志檔案默認1G,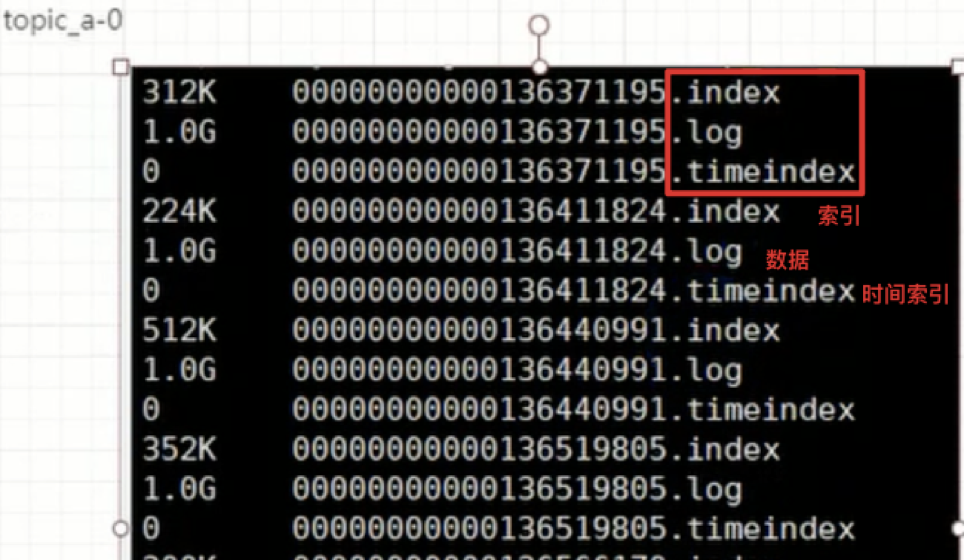 服務器2(kafka2):創建目錄topic_a-1: 服務器3(kafka3):創建目錄topic_a-2:
服務器2(kafka2):創建目錄topic_a-1: 服務器3(kafka3):創建目錄topic_a-2:
7、Kafka二分查找定位資料
Kafka里面每一條訊息,都有自己的offset(相對偏移量),存在物理磁盤上面,在position Position:物理位置(磁盤上面哪個地方)也就是說一條訊息就有兩個位置:offset:相對偏移量(相對位置)position:磁盤物理位置稀疏索引: Kafka中采用了稀疏索引的方式讀取索引,kafka每當寫入了4k大小的日志(.log),就往index里寫入一個記錄索引,其中會采用二分查找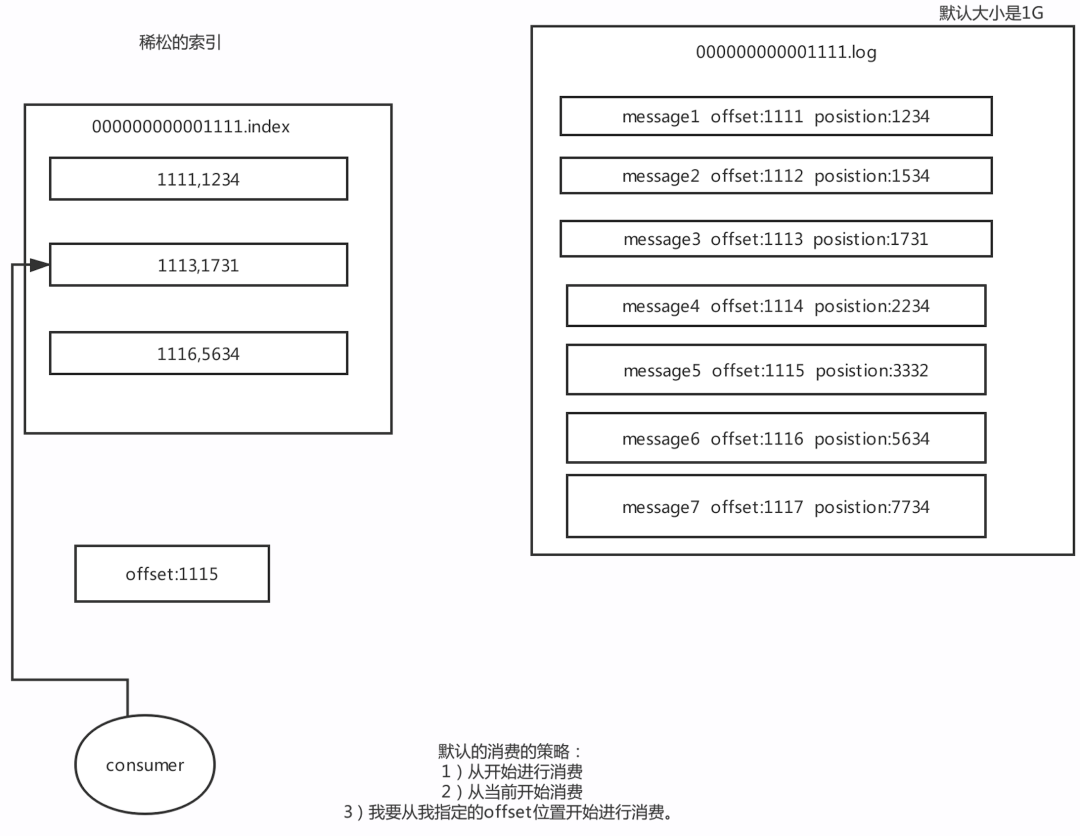
8、高并發網路設計(先了解NIO)
網路設計部分是kafka中設計最好的一個部分,這也是保證Kafka高并發、高性能的原因,對kafka進行調優,就得對kafka原理比較了解,尤其是網路設計部分
Reactor網路設計模式1: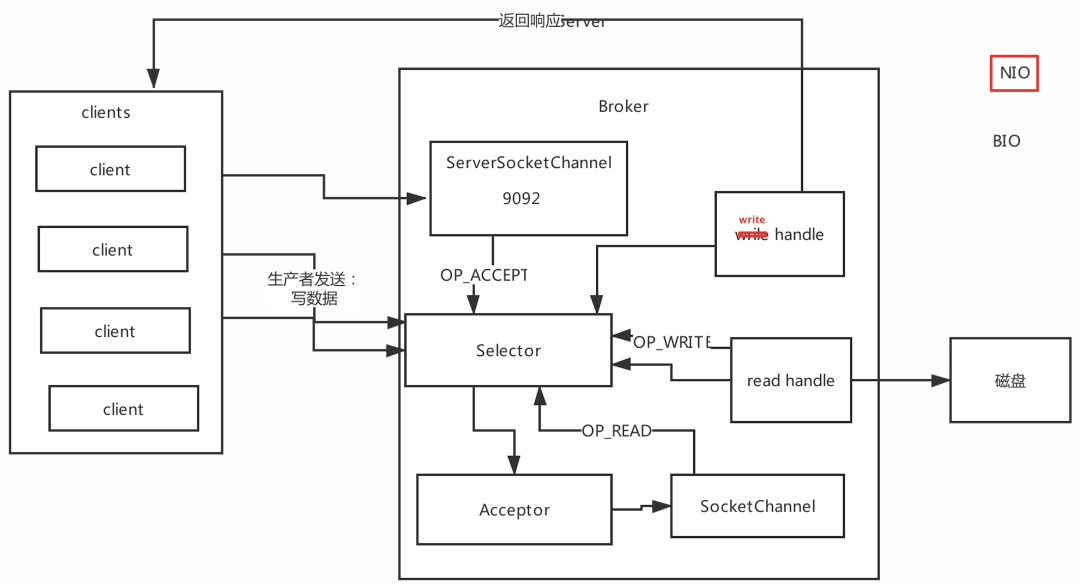 Reactor網路設計模式2:
Reactor網路設計模式2: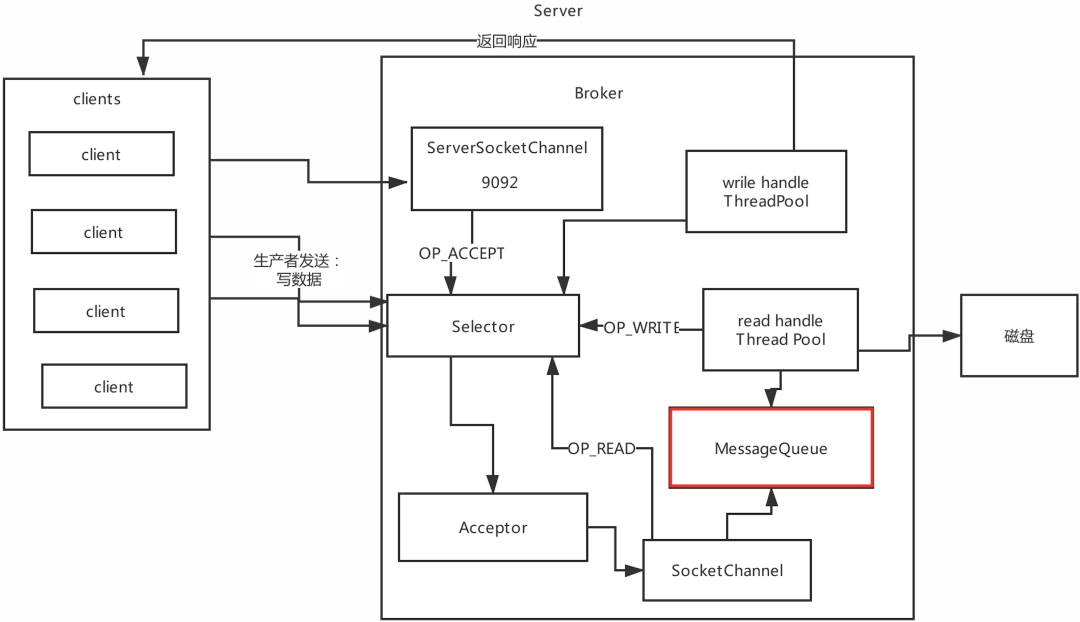 Reactor網路設計模式3:
Reactor網路設計模式3: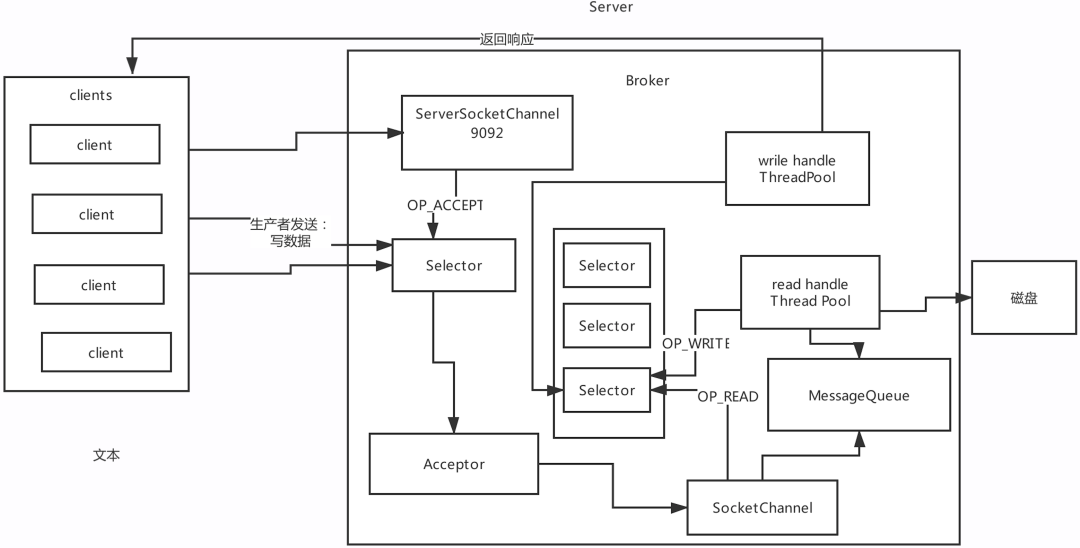 Kafka超高并發網路設計:
Kafka超高并發網路設計: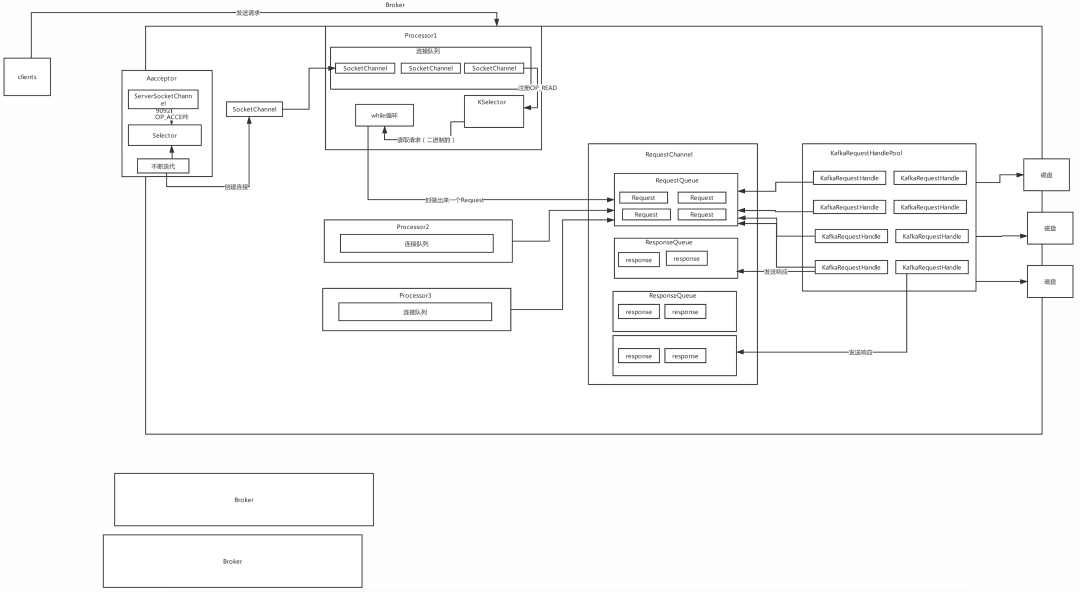

9、Kafka冗余副本保證高可用
在kafka里面磁區是有副本的,注:0.8以前是沒有副本機制的,創建主題時,可以指定磁區,也可以指定副本個數,副本是有角色的:leader partition:1、寫資料、讀資料操作都是從leader partition去操作的,2、會維護一個ISR(in-sync- replica )串列,但是會根據一定的規則洗掉ISR串列里面的值 生產者發送來一個訊息,訊息首先要寫入到leader partition中 寫完了以后,還要把訊息寫入到ISR串列里面的其它磁區,寫完后才算這個訊息提交 follower partition:從leader partition同步資料,
10、優秀架構思考-總結
Kafka — 高并發、高可用、高性能 高可用:多副本機制 高并發:網路架構設計 三層架構:多selector -> 多執行緒 -> 佇列的設計(NIO) 高性能:寫資料:
-
把資料先寫入到OS Cache
-
寫到磁盤上面是順序寫,性能很高
讀資料:
-
根據稀疏索引,快速定位到要消費的資料
-
零拷貝機制 減少資料的拷貝 減少了應用程式與作業系統背景關系切換
11、Kafka生產環境搭建
11.1 需求場景分析
電商平臺,需要每天10億請求都要發送到Kafka集群上面,二八反正,一般評估出來問題都不大,10億請求 -> 24 過來的,一般情況下,每天的12:00 到早上8:00 這段時間其實是沒有多大的資料量的,80%的請求是用的另外16小時的處理的,16個小時處理 -> 8億的請求,16 * 0.2 = 3個小時 處理了8億請求的80%的資料
也就是說6億的資料是靠3個小時處理完的,我們簡單的算一下高峰期時候的qps6億/3小時 =5.5萬/s qps=5.5萬
10億請求 * 50kb = 46T 每天需要存盤46T的資料
一般情況下,我們都會設定兩個副本 46T * 2 = 92T Kafka里面的資料是有保留的時間周期,保留最近3天的資料,92T * 3天 = 276T我這兒說的是50kb不是說一條訊息就是50kb不是(把日志合并了,多條日志合并在一起),通常情況下,一條訊息就幾b,也有可能就是幾百位元組,
11.2 物理機數量評估
1)首先分析一下是需要虛擬機還是物理機 像Kafka mysql hadoop這些集群搭建的時候,我們生產里面都是使用物理機,2)高峰期需要處理的請求總的請求每秒5.5萬個,其實一兩臺物理機絕對是可以抗住的,一般情況下,我們評估機器的時候,是按照高峰期的4倍的去評估,如果是4倍的話,大概我們集群的能力要準備到 20萬qps,這樣子的集群才是比較安全的集群,大概就需要5臺物理機,每臺承受4萬請求,
場景總結:搞定10億請求,高峰期5.5萬的qps,276T的資料,需要5臺物理機,
11.3 磁盤選擇
搞定10億請求,高峰期5.5萬的qps,276T的資料,需要5臺物理機,1)SSD固態硬碟,還是需要普通的機械硬碟SSD硬碟:性能比較好,但是價格貴 SAS盤:某方面性能不是很好,但是比較便宜,SSD硬碟性能比較好,指的是它隨機讀寫的性能比較好,適合MySQL這樣集群,但是其實他的順序寫的性能跟SAS盤差不多,kafka的理解:就是用的順序寫,所以我們就用普通的【機械硬碟】就可以了,
2)需要我們評估每臺服務器需要多少塊磁盤 5臺服務器,一共需要276T ,大約每臺服務器 需要存盤60T的資料,我們公司里面服務器的配置用的是 11塊硬碟,每個硬碟 7T,11 * 7T = 77T
77T * 5 臺服務器 = 385T,
場景總結:
搞定10億請求,需要5臺物理機,11(SAS) * 7T
11.4 記憶體評估
搞定10億請求,需要5臺物理機,11(SAS) * 7T
我們發現kafka讀寫資料的流程 都是基于os cache,換句話說假設咱們的os cashe無限大那么整個kafka是不是相當于就是基于記憶體去操作,如果是基于記憶體去操作,性能肯定很好,記憶體是有限的,1) 盡可能多的記憶體資源要給 os cache 2) Kafka的代碼用 核心的代碼用的是scala寫的,客戶端的代碼java寫的,都是基于jvm,所以我們還要給一部分的記憶體給jvm,Kafka的設計,沒有把很多資料結構都放在jvm里面,所以我們的這個jvm不需要太大的記憶體,根據經驗,給個10G就可以了,
NameNode: jvm里面還放了元資料(幾十G),JVM一定要給得很大,比如給個100G,
假設我們這個10請求的這個專案,一共會有100個topic,100 topic * 5 partition * 2 = 1000 partition 一個partition其實就是物理機上面的一個目錄,這個目錄下面會有很多個.log的檔案,.log就是存盤資料檔案,默認情況下一個.log檔案的大小是1G,我們如果要保證 1000個partition 的最新的.log 檔案的資料 如果都在記憶體里面,這個時候性能就是最好,1000 * 1G = 1000G記憶體. 我們只需要把當前最新的這個log 保證里面的25%的最新的資料在記憶體里面,250M * 1000 = 0.25 G* 1000 =250G的記憶體,
250記憶體 / 5 = 50G記憶體 50G+10G = 60G記憶體
64G的記憶體,另外的4G,作業系統本生是不是也需要記憶體,其實Kafka的jvm也可以不用給到10G這么多,評估出來64G是可以的,當然如果能給到128G的記憶體的服務器,那就最好,
我剛剛評估的時候用的都是一個topic是5個partition,但是如果是資料量比較大的topic,可能會有10個partition,
總結:搞定10億請求,需要5臺物理機,11(SAS) * 7T ,需要64G的記憶體(128G更好)
11.5 CPU壓力評估
評估一下每臺服務器需要多少cpu core(資源很有限)
我們評估需要多少個cpu ,依據就是看我們的服務里面有多少執行緒去跑,執行緒就是依托cpu 去運行的,如果我們的執行緒比較多,但是cpu core比較少,這樣的話,我們的機器負載就會很高,性能不就不好,
評估一下,kafka的一臺服務器 啟動以后會有多少執行緒?
Acceptor執行緒 1 processor執行緒 3 6~9個執行緒 處理請求執行緒 8個 32個執行緒 定時清理的執行緒,拉取資料的執行緒,定時檢查ISR串列的機制 等等,所以大概一個Kafka的服務啟動起來以后,會有一百多個執行緒,
cpu core = 4個,一遍來說,幾十個執行緒,就肯定把cpu 打滿了,cpu core = 8個,應該很輕松的能支持幾十個執行緒,如果我們的執行緒是100多個,或者差不多200個,那么8 個 cpu core是搞不定的,所以我們這兒建議:CPU core = 16個,如果可以的話,能有32個cpu core 那就最好,
結論:kafka集群,最低也要給16個cpu core,如果能給到32 cpu core那就更好,2cpu * 8 =16 cpu core 4cpu * 8 = 32 cpu core
總結:搞定10億請求,需要5臺物理機,11(SAS) * 7T ,需要64G的記憶體(128G更好),需要16個cpu core(32個更好)
11.6 網路需求評估
評估我們需要什么樣網卡?一般要么是千兆的網卡(1G/s),還有的就是萬兆的網卡(10G/s)
高峰期的時候 每秒會有5.5萬的請求涌入,5.5/5 = 大約是每臺服務器會有1萬個請求涌入,
我們之前說的,
10000 * 50kb = 488M 也就是每條服務器,每秒要接受488M的資料,資料還要有副本,副本之間的同步
也是走的網路的請求,488 * 2 = 976m/s
說明一下:
很多公司的資料,一個請求里面是沒有50kb這么大的,我們公司是因為主機在生產端封裝了資料
然后把多條資料合并在一起了,所以我們的一個請求才會有這么大,
說明一下:
一般情況下,網卡的帶寬是達不到極限的,如果是千兆的網卡,我們能用的一般就是700M左右,
但是如果最好的情況,我們還是使用萬兆的網卡,
如果使用的是萬兆的,那就是很輕松,
11.7 集群規劃
請求量 規劃物理機的個數 分析磁盤的個數,選擇使用什么樣的磁盤 記憶體 cpu core 網卡就是告訴大家,以后要是公司里面有什么需求,進行資源的評估,服務器的評估,大家按照我的思路去評估
一條訊息的大小 50kb -> 1kb 500byte 1Mip 主機名 192.168.0.100 hadoop1 192.168.0.101 hadoop2 192.168.0.102 hadoop3
主機的規劃:kafka集群架構的時候:主從式的架構:controller -> 通過zk集群來管理整個集群的元資料,
-
zookeeper集群 hadoop1 hadoop2 hadoop3
-
kafka集群 理論上來講,我們不應該把kafka的服務于zk的服務安裝在一起,但是我們這兒服務器有限,所以我們kafka集群也是安裝在hadoop1 haadoop2 hadoop3
12、kafka運維
12.1 常見運維工具介紹
KafkaManager — 頁面管理工具
12.2 常見運維命令
場景一:topic資料量太大,要增加topic數
一開始創建主題的時候,資料量不大,給的磁區數不多,
kafka-topics.sh --create --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181 --replication-factor 1 --partitions 1 --topic test6
kafka-topics.sh --alter --zookeeper hadoop1:2181,hadoop2:2181,ha
broker id:
hadoop1:0 hadoop2:1 hadoop3:2 假設一個partition有三個副本:partition0:a,b,c
a:leader partition b,c:follower partition
ISR:{a,b,c}如果一個follower磁區 超過10秒 沒有向leader partition去拉取資料,那么這個磁區就從ISR串列里面移除,
場景二:核心topic增加副本因子
如果對核心業務資料需要增加副本因子 vim test.json腳本,將下面一行json腳本保存
{“version”:1,“partitions”:[{“topic”:“test6”,“partition”:0,“replicas”:[0,1,2]},{“topic”:“test6”,“partition”:1,“replicas”:[0,1,2]},{“topic”:“test6”,“partition”:2,“replicas”:[0,1,2]}]}
執行上面json腳本:
kafka-reassign-partitions.sh --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181 --reassignment-json-file test.json --execute
場景三:負載不均衡的topic,手動遷移vi topics-to-move.json
{“topics”: [{“topic”: “test01”}, {“topic”: “test02”}], “version”: 1} // 把你所有的topic都寫在這里
kafka-reassgin-partitions.sh --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181 --topics-to-move-json-file topics-to-move.json --broker-list “5,6” --generate
把你所有的包括新加入的broker機器都寫在這里,就會說是把所有的partition均勻的分散在各個broker上,包括新進來的broker此時會生成一個遷移方案,可以保存到一個檔案里去:expand-cluster-reassignment.json
kafka-reassign-partitions.sh --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
kafka-reassign-partitions.sh --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
這種資料遷移操作一定要在晚上低峰的時候來做,因為他會在機器之間遷移資料,非常的占用帶寬資源–generate: 根據給予的Topic串列和Broker串列生成遷移計劃,generate并不會真正進行訊息遷移,而是將訊息遷移計劃計算出來,供execute命令使用,–execute: 根據給予的訊息遷移計劃進行遷移,–verify: 檢查訊息是否已經遷移完成,
場景四:如果某個broker leader partition過多
正常情況下,我們的leader partition在服務器之間是負載均衡,hadoop1 4 hadoop2 1 hadoop3 1
現在各個業務方可以自行申請創建topic,磁區數量都是自動分配和后續動態調整的, kafka本身會自動把leader partition均勻分散在各個機器上,這樣可以保證每臺機器的讀寫吞吐量都是均勻的 但是也有例外,那就是如果某些broker宕機,會導致leader partition過于集中在其他少部分幾臺broker上, 這會導致少數幾臺broker的讀寫請求壓力過高,其他宕機的broker重啟之后都是folloer partition,讀寫請求很低, 造成集群負載不均衡有一個引數,auto.leader.rebalance.enable,默認是true, 每隔300秒(leader.imbalance.check.interval.seconds)檢查leader負載是否平衡 如果一臺broker上的不均衡的leader超過了10%,leader.imbalance.per.broker.percentage, 就會對這個broker進行選舉 配置引數:auto.leader.rebalance.enable 默認是true leader.imbalance.per.broker.percentage: 每個broker允許的不平衡的leader的比率,如果每個broker超過了這個值,控制器會觸發leader的平衡,這個值表示百分比,10% leader.imbalance.check.interval.seconds:默認值300秒
13、Kafka生產者
13.1 消費者發送訊息原理
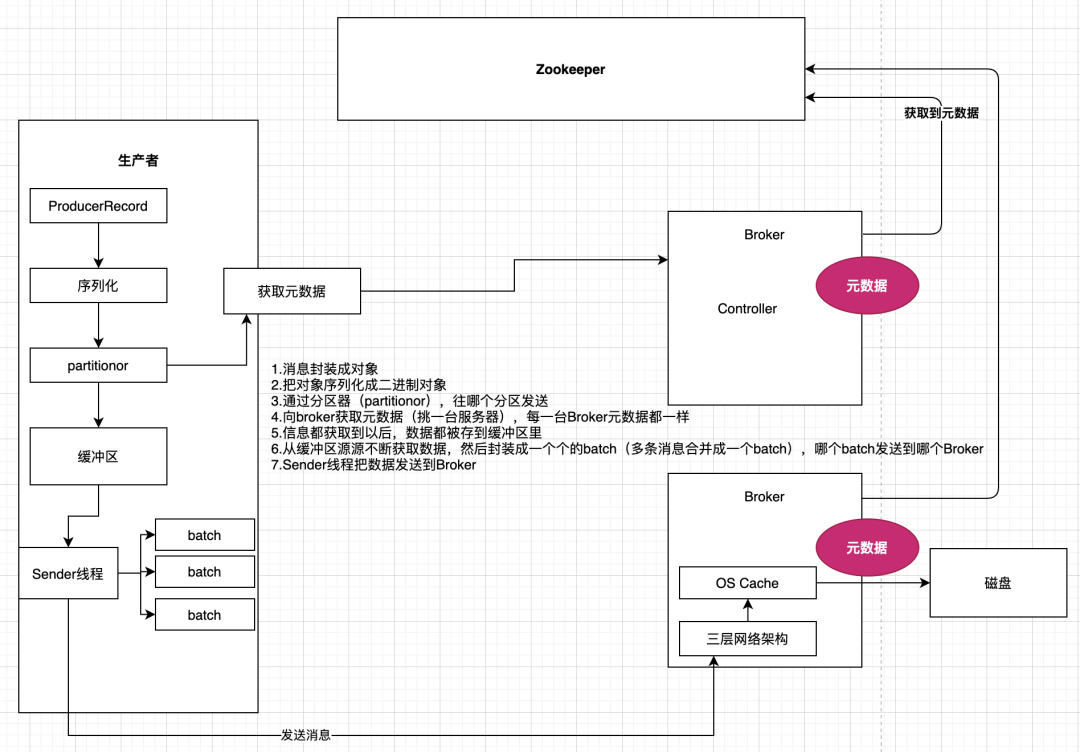
13.2 消費者發送訊息原理—基礎案例演示

13.3 如何提升吞吐量
如何提升吞吐量:引數一:buffer.memory:設定發送訊息的緩沖區,默認值是33554432,就是32MB 引數二:compression.type:默認是none,不壓縮,但是也可以使用lz4壓縮,效率還是不錯的,壓縮之后可以減小資料量,提升吞吐量,但是會加大producer端的cpu開銷 引數三:batch.size:設定batch的大小,如果batch太小,會導致頻繁網路請求,吞吐量下降;如果batch太大,會導致一條訊息需要等待很久才能被發送出去,而且會讓記憶體緩沖區有很大壓力,過多資料緩沖在記憶體里,默認值是:16384,就是16kb,也就是一個batch滿了16kb就發送出去,一般在實際生產環境,這個batch的值可以增大一些來提升吞吐量,如果一個批次設定大了,會有延遲,一般根據一條訊息大小來設定,如果我們訊息比較少,配合使用的引數linger.ms,這個值默認是0,意思就是訊息必須立即被發送,但是這是不對的,一般設定一個100毫秒之類的,這樣的話就是說,這個訊息被發送出去后進入一個batch,如果100毫秒內,這個batch滿了16kb,自然就會發送出去,
13.4 如何處理例外
-
LeaderNotAvailableException:這個就是如果某臺機器掛了,此時leader副本不可用,會導致你寫入失敗,要等待其他follower副本切換為leader副本之后,才能繼續寫入,此時可以重試發送即可;如果說你平時重啟kafka的broker行程,肯定會導致leader切換,一定會導致你寫入報錯,是LeaderNotAvailableException,
-
NotControllerException:這個也是同理,如果說Controller所在Broker掛了,那么此時會有問題,需要等待Controller重新選舉,此時也是一樣就是重試即可,
-
NetworkException:網路例外 timeout a. 配置retries引數,他會自動重試的 b. 但是如果重試幾次之后還是不行,就會提供Exception給我們來處理了,我們獲取到例外以后,再對這個訊息進行單獨處理,我們會有備用的鏈路,發送不成功的訊息發送到Redis或者寫到檔案系統中,甚至是丟棄,
13.5 重試機制
重試會帶來一些問題:
-
訊息會重復有的時候一些leader切換之類的問題,需要進行重試,設定retries即可,但是訊息重試會導致,重復發送的問題,比如說網路抖動一下導致他以為沒成功,就重試了,其實人家都成功了.
-
訊息亂序訊息重試是可能導致訊息的亂序的,因為可能排在你后面的訊息都發送出去了,所以可以使用"max.in.flight.requests.per.connection"引數設定為1, 這樣可以保證producer同一時間只能發送一條訊息,兩次重試的間隔默認是100毫秒,用"retry.backoff.ms"來進行設定 基本上在開發程序中,靠重試機制基本就可以搞定95%的例外問題,
13.6 ACK引數詳解
producer端設定的 request.required.acks=0;只要請求已發送出去,就算是發送完了,不關心有沒有寫成功,性能很好,如果是對一些日志進行分析,可以承受丟資料的情況,用這個引數,性能會很好,request.required.acks=1;發送一條訊息,當leader partition寫入成功以后,才算寫入成功,不過這種方式也有丟資料的可能,request.required.acks=-1;需要ISR串列里面,所有副本都寫完以后,這條訊息才算寫入成功,ISR:1個副本,1 leader partition 1 follower partition kafka服務端:min.insync.replicas:1, 如果我們不設定的話,默認這個值是1 一個leader partition會維護一個ISR串列,這個值就是限制ISR串列里面 至少得有幾個副本,比如這個值是2,那么當ISR串列里面只有一個副本的時候,往這個磁區插入資料的時候會報錯,設計一個不丟資料的方案:資料不丟失的方案:1)磁區副本 >=2 2)acks = -1 3)min.insync.replicas >=2 還有可能就是發送有例外:對例外進行處理
13.7 自定義磁區
磁區:1、沒有設定key我們的訊息就會被輪訓的發送到不同的磁區,2、設定了keykafka自帶的磁區器,會根據key計算出來一個hash值,這個hash值會對應某一個磁區,如果key相同的,那么hash值必然相同,key相同的值,必然是會被發送到同一個磁區,但是有些比較特殊的時候,我們就需要自定義磁區
public class HotDataPartitioner implements Partitioner {
private Random random;
@Override
public void configure(Map<String, ?> configs) {
random = new Random();
}
@Override
public int partition(String topic, Object keyObj, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String key = (String)keyObj;
List partitionInfoList = cluster.availablePartitionsForTopic(topic);
//獲取到磁區的個數 0,1,2
int partitionCount = partitionInfoList.size();
//最后一個磁區
int hotDataPartition = partitionCount - 1;
return !key.contains(“hot_data”) ? random.nextInt(partitionCount - 1) : hotDataPartition;
}
}
如何使用:配置上這個類即可:props.put(”partitioner.class”, “com.zhss.HotDataPartitioner”);
13.8 綜合案例演示
14.1 消費組概念 groupid相同就屬于同一個消費組 1)每個consumer都要屬于一個consumer.group,就是一個消費組,topic的一個磁區只會分配給 一個消費組下的一個consumer來處理,每個consumer可能會分配多個磁區,也有可能某個consumer沒有分配到任何磁區 2)如果想要實作一個廣播的效果,那只需要使用不同的group id去消費就可以,topicA: partition0、partition1 groupA:consumer1:消費 partition0 consuemr2:消費 partition1 consuemr3:消費不到資料 groupB: consuemr3:消費到partition0和partition1 3)如果consumer group中某個消費者掛了,此時會自動把分配給他的磁區交給其他的消費者,如果他又重啟了,那么又會把一些磁區重新交還給他
14、Kafka消費者
14.1 消費組概念
groupid相同就屬于同一個消費組 1)每個consumer都要屬于一個consumer.group,就是一個消費組,topic的一個磁區只會分配給 一個消費組下的一個consumer來處理,每個consumer可能會分配多個磁區,也有可能某個consumer沒有分配到任何磁區 2)如果想要實作一個廣播的效果,那只需要使用不同的group id去消費就可以,topicA: partition0、partition1 groupA:consumer1:消費 partition0 consuemr2:消費 partition1 consuemr3:消費不到資料 groupB: consuemr3:消費到partition0和partition1 3)如果consumer group中某個消費者掛了,此時會自動把分配給他的磁區交給其他的消費者,如果他又重啟了,那么又會把一些磁區重新交還給他
14.2 基礎案例演示

14.3 偏移量管理
-
每個consumer記憶體里資料結構保存對每個topic的每個磁區的消費offset,定期會提交offset,老版本是寫入zk,但是那樣高并發請求zk是不合理的架構設計,zk是做分布式系統的協調的,輕量級的元資料存盤,不能負責高并發讀寫,作為資料存盤,
-
現在新的版本提交offset發送給kafka內部topic:__consumer_offsets,提交過去的時候, key是group.id+topic+磁區號,value就是當前offset的值,每隔一段時間,kafka內部會對這個topic進行compact(合并),也就是每個group.id+topic+磁區號就保留最新資料,
-
__consumer_offsets可能會接收高并發的請求,所以默認磁區50個(leader partitiron -> 50 kafka),這樣如果你的kafka部署了一個大的集群,比如有50臺機器,就可以用50臺機器來抗offset提交的請求壓力. 消費者 -> broker端的資料 message -> 磁盤 -> offset 順序遞增 從哪兒開始消費?-> offset 消費者(offset)
14.4 偏移量監控工具介紹
-
web頁面管理的一個管理軟體(kafka Manager) 修改bin/kafka-run-class.sh腳本,第一行增加JMX_PORT=9988 重啟kafka行程
-
另一個軟體:主要監控的consumer的偏移量,就是一個jar包 java -cp KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb –offsetStorage kafka \(根據版本:偏移量存在kafka就填kafka,存在zookeeper就填zookeeper) –zk hadoop1:2181 –port 9004 –refresh 15.seconds –retain 2.days,
14.5 消費例外感知
heartbeat.interval.ms:consumer心跳時間間隔,必須得與coordinator保持心跳才能知道consumer是否故障了, 然后如果故障之后,就會通過心跳下發rebalance的指令給其他的consumer通知他們進行rebalance的操作 session.timeout.ms:kafka多長時間感知不到一個consumer就認為他故障了,默認是10秒 max.poll.interval.ms:如果在兩次poll操作之間,超過了這個時間,那么就會認為這個consume處理能力太弱了,會被踢出消費組,磁區分配給別人去消費,一般來說結合業務處理的性能來設定就可以了,
14.6 核心引數解釋
fetch.max.bytes:獲取一條訊息最大的位元組數,一般建議設定大一些,默認是1M 其實我們在之前多個地方都見到過這個類似的引數,意思就是說一條資訊最大能多大?
-
Producer 發送的資料,一條訊息最大多大, -> 10M
-
Broker 存盤資料,一條訊息最大能接受多大 -> 10M
-
Consumer max.poll.records: 一次poll回傳訊息的最大條數,默認是500條 connection.max.idle.ms:consumer跟broker的socket連接如果空閑超過了一定的時間,此時就會自動回收連接,但是下次消費就要重新建立socket連接,這個建議設定為-1,不要去回收 enable.auto.commit: 開啟自動提交偏移量 auto.commit.interval.ms: 每隔多久提交一次偏移量,默認值5000毫秒 _consumer_offset auto.offset.reset:earliest 當各磁區下有已提交的offset時,從提交的offset開始消費;無提交的offset時,從頭開始消費 topica -> partition0:1000 partitino1:2000 latest 當各磁區下有已提交的offset時,從提交的offset開始消費;無提交的offset時,消費新產生的該磁區下的資料 none topic各磁區都存在已提交的offset時,從offset后開始消費;只要有一個磁區不存在已提交的offset,則拋出例外
14.7 綜合案例演示
引入案例:二手電商平臺(歡樂送),根據用戶消費的金額,對用戶星星進行累計,訂單系統(生產者) -> Kafka集群里面發送了訊息,會員系統(消費者) -> Kafak集群里面消費訊息,對訊息進行處理,
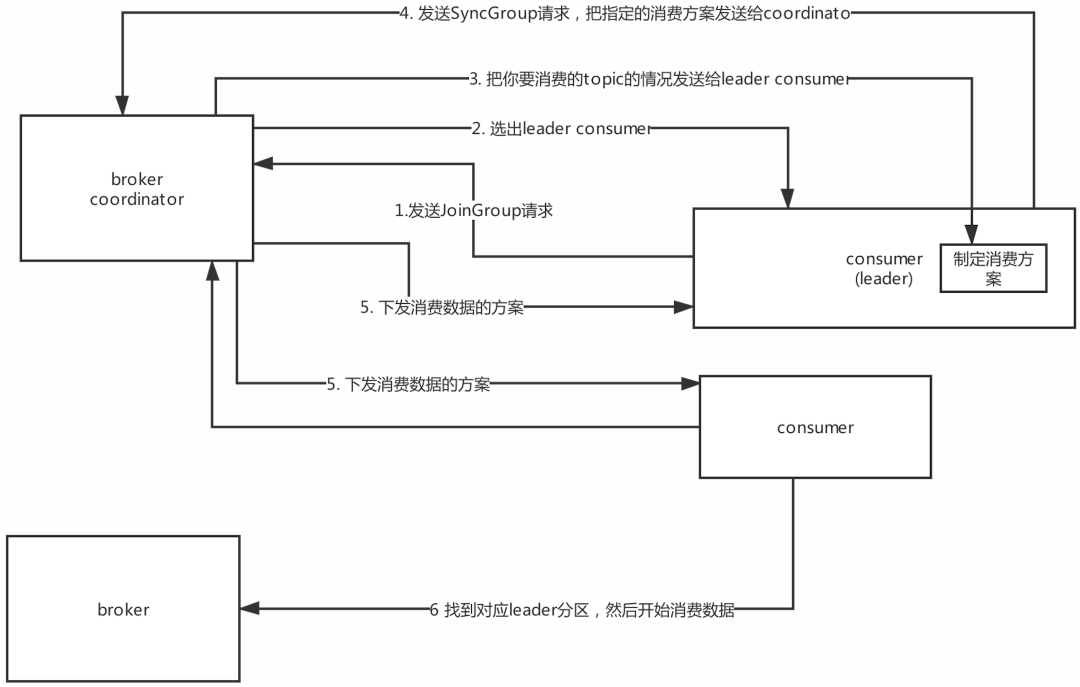
14.8 group coordinator原理
面試題:消費者是如何實作rebalance的?— 根據coordinator實作
-
什么是coordinator 每個consumer group都會選擇一個broker作為自己的coordinator,他是負責監控這個消費組里的各個消費者的心跳,以及判斷是否宕機,然后開啟rebalance的
-
如何選擇coordinator機器 首先對groupId進行hash(數字),接著對__consumer_offsets的磁區數量取模,默認是50,_consumer_offsets的磁區數可以通過offsets.topic.num.partitions來設定,找到磁區以后,這個磁區所在的broker機器就是coordinator機器,比如說:groupId,“myconsumer_group” -> hash值(數字)-> 對50取模 -> 8 __consumer_offsets 這個主題的8號磁區在哪臺broker上面,那一臺就是coordinator 就知道這個consumer group下的所有的消費者提交offset的時候是往哪個磁區去提交offset,
-
運行流程 1)每個consumer都發送JoinGroup請求到Coordinator, 2)然后Coordinator從一個consumer group中選擇一個consumer作為leader, 3)把consumer group情況發送給這個leader, 4)接著這個leader會負責制定消費方案, 5)通過SyncGroup發給Coordinator 6)接著Coordinator就把消費方案下發給各個consumer,他們會從指定的磁區的 leader broker開始進行socket連接以及消費訊息
14.9 rebalance策略
consumer group靠coordinator實作了Rebalance
這里有三種rebalance的策略:range、round-robin、sticky
比如我們消費的一個主題有12個磁區:p0,p1,p2,p3,p4,p5,p6,p7,p8,p9,p10,p11 假設我們的消費者組里面有三個消費者
-
range策略 range策略就是按照partiton的序號范圍 p0~3 consumer1 p4~7 consumer2 p8~11 consumer3 默認就是這個策略;
-
round-robin策略 就是輪詢分配 consumer1:0,3,6,9 consumer2:1,4,7,10 consumer3:2,5,8,11 但是前面的這兩個方案有個問題:12 -> 2 每個消費者會消費6個磁區
假設consuemr1掛了:p0-5分配給consumer2,p6-11分配給consumer3 這樣的話,原本在consumer2上的的p6,p7磁區就被分配到了 consumer3上,
-
sticky策略 最新的一個sticky策略,就是說盡可能保證在rebalance的時候,讓原本屬于這個consumer 的磁區還是屬于他們,然后把多余的磁區再均勻分配過去,這樣盡可能維持原來的磁區分配的策略
consumer1:0-3 consumer2: 4-7 consumer3: 8-11 假設consumer3掛了 consumer1:0-3,+8,9 consumer2: 4-7,+10,11
15、Broker管理
15.1 Leo、hw含義
-
Kafka的核心原理
-
如何去評估一個集群資源
-
搭建了一套kafka集群 -》 介紹了簡單的一些運維管理的操作,
-
生產者(使用,核心的引數)
-
消費者(原理,使用的,核心引數)
-
broker內部的一些原理
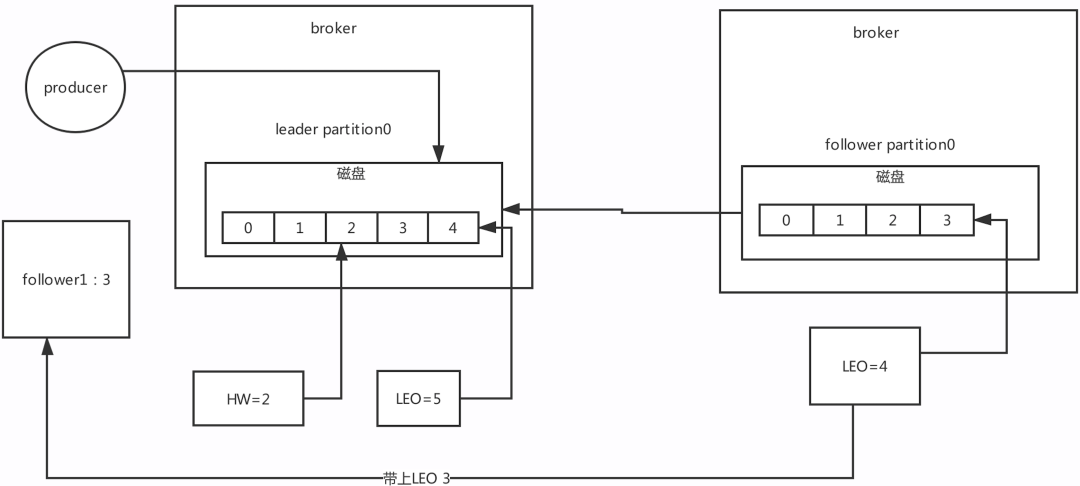
核心的概念:LEO,HW LEO:是跟offset偏移量有關系,
LEO:在kafka里面,無論leader partition還是follower partition統一都稱作副本(replica),
每次partition接收到一條訊息,都會更新自己的LEO,也就是log end offset,LEO其實就是最新的offset + 1
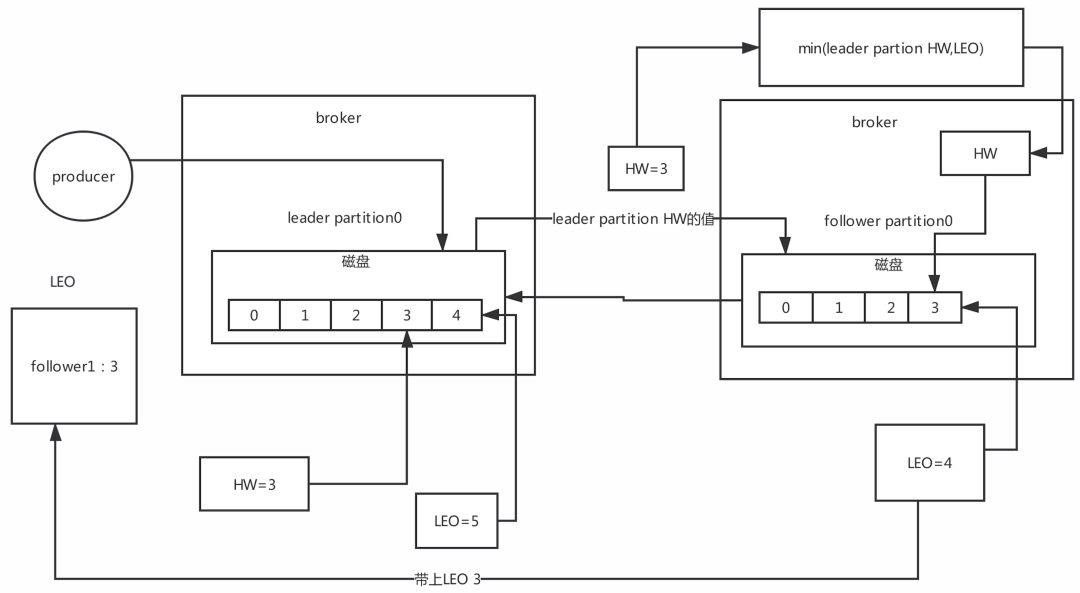
HW:高水位 LEO有一個很重要的功能就是更新HW,如果follower和leader的LEO同步了,此時HW就可以更新 HW之前的資料對消費者是可見,訊息屬于commit狀態,HW之后的訊息消費者消費不到,
15.2 Leo更新
15.3 hw更新
15.4 controller如何管理整個集群
1: 競爭controller的 /controller/id 2:controller服務監聽的目錄:/broker/ids/ 用來感知 broker上下線 /broker/topics/ 創建主題,我們當時創建主題命令,提供的引數,ZK地址,/admin/reassign_partitions 磁區重分配 ……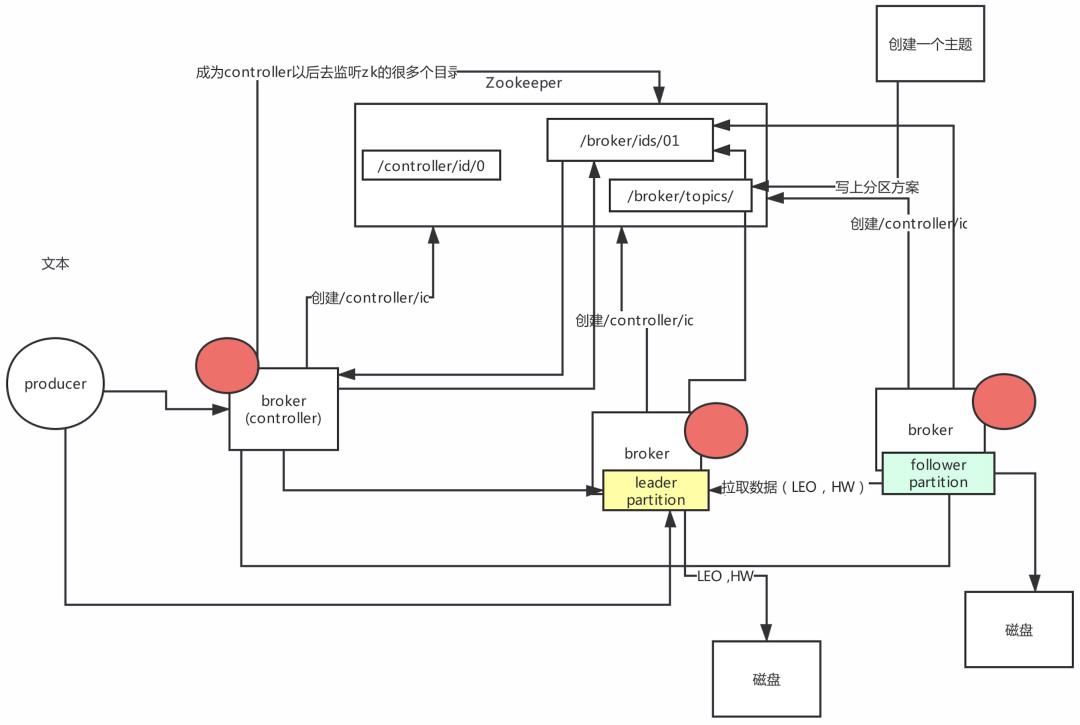
15.5 延時任務
kafka的延遲調度機制(擴展知識) 我們先看一下kafka里面哪些地方需要有任務要進行延遲調度,第一類延時的任務:比如說producer的acks=-1,必須等待leader和follower都寫完才能回傳回應,有一個超時時間,默認是30秒(request.timeout.ms),所以需要在寫入一條資料到leader磁盤之后,就必須有一個延時任務,到期時間是30秒延時任務 放到DelayedOperationPurgatory(延時管理器)中,假如在30秒之前如果所有follower都寫入副本到本地磁盤了,那么這個任務就會被自動觸發蘇醒,就可以回傳回應結果給客戶端了, 否則的話,這個延時任務自己指定了最多是30秒到期,如果到了超時時間都沒等到,就直接超時回傳例外,第二類延時的任務:follower往leader拉取訊息的時候,如果發現是空的,此時會創建一個延時拉取任務 延時時間到了之后(比如到了100ms),就給follower回傳一個空的資料,然后follower再次發送請求讀取訊息, 但是如果延時的程序中(還沒到100ms),leader寫入了訊息,這個任務就會自動蘇醒,自動執行拉取任務,
海量的延時任務,需要去調度,
15.6 時間輪機制
-
什么會有要設計時間輪?Kafka內部有很多延時任務,沒有基于JDK Timer來實作,那個插入和洗掉任務的時間復雜度是O(nlogn), 而是基于了自己寫的時間輪來實作的,時間復雜度是O(1),依靠時間輪機制,延時任務插入和洗掉,O(1)
-
時間輪是什么?其實時間輪說白其實就是一個陣列,tickMs:時間輪間隔 1ms wheelSize:時間輪大小 20 interval:timckMS * whellSize,一個時間輪的總的時間跨度,20ms currentTime:當時時間的指標,a:因為時間輪是一個陣列,所以要獲取里面資料的時候,靠的是index,時間復雜度是O(1) b:陣列某個位置上對應的任務,用的是雙向鏈表存盤的,往雙向鏈表里面插入,洗掉任務,時間復雜度也是O(1) 舉例:插入一個8ms以后要執行的任務 19ms 3.多層級的時間輪 比如:要插入一個110毫秒以后運行的任務,tickMs:時間輪間隔 20ms wheelSize:時間輪大小 20 interval:timckMS * whellSize,一個時間輪的總的時間跨度,20ms currentTime:當時時間的指標,第一層時間輪:1ms * 20 第二層時間輪:20ms * 20 第三層時間輪:400ms * 20
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/281222.html
標籤:其他
上一篇:JavaWeb經典案例--用戶資訊管理(利用Map集合物件)
下一篇:訊息佇列和郵件發送