文章目錄
- 1 快取行
- 2 CPU的資料一致性
- 2.1 快取一致性協議
- 2.2 鎖總線
- 3 偽共享
- 3.1 什么是偽共享
- 3.2 如何預防偽共享問題
- 4 指令重排序
- 4.1 CPU的指令重排序
- 4.2 編譯器指令重排序
- 5 防止指令重排序
- 5.1 硬體層面防止指令重排序
- 5.1.1 硬體記憶體屏障
- 5.1.2 原子指令
- 5.2 JVM規范(JSR133)
- 5.2.1 volatile
- 5.2.2 synchronized
1 快取行
??說到快取行,首先得了解CPU多核三級快取架構,
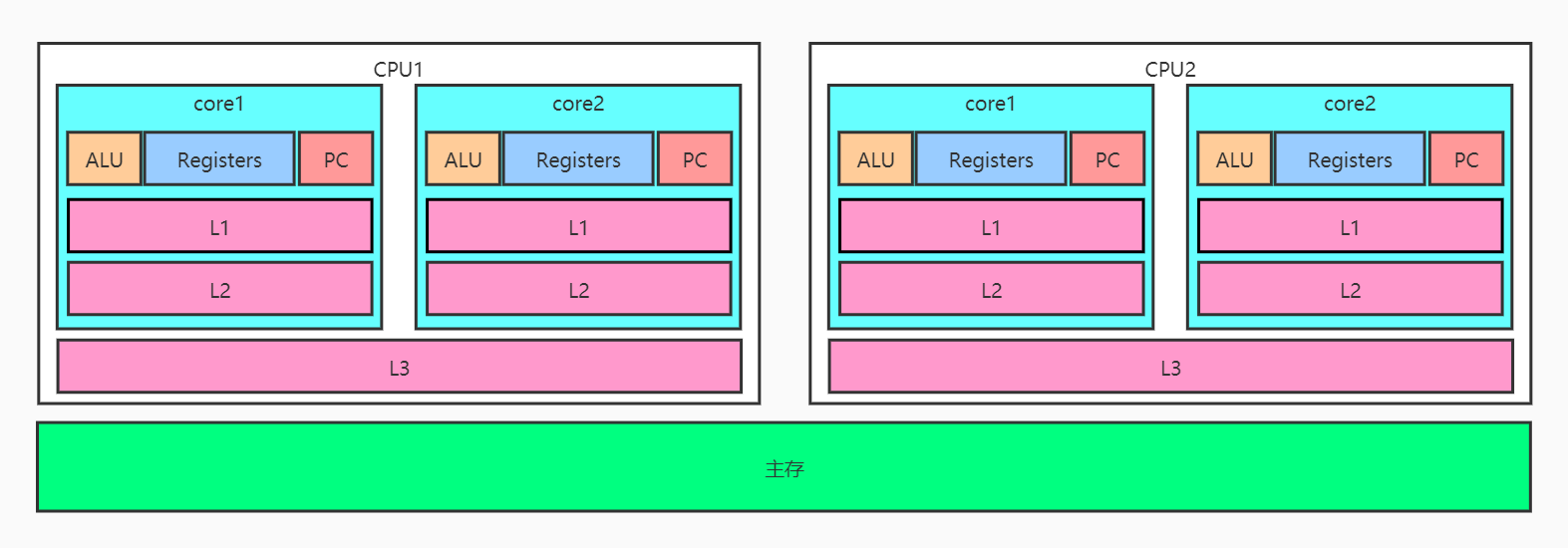
??首先有一個常識,CPU的速度是主存的100倍,為了協調CPU和主存之間的速度差異,在CPU和主存之間,加入了三級快取,其速度L1 > L2 > L3,CPU對主存中的某個資料進行讀寫操作時,先將資料從主存加載到L3,再到L2,最后到L1,根據空間區域性原理,CPU為了提高效率,減少從主存中加載資料的頻率,并非每次從主存中加載一個資料,而是按塊加載,這個資料塊在快取中成為快取行(CacheLine),每個快取行占64個位元組,
2 CPU的資料一致性
??CPU的多核三級快取架構,導致了多個核之間的L1、L2資料不一致的問題,試想L3中的一個快取行存放了一個資料num,這個快取行被加載到CPU中core1和core2的L1中,core1對num進行更新操作,此時core2并不知道core1中資料的變化,兩個core中快取的資料出現了不一致,
2.1 快取一致性協議
??為了解決CPU中資料不一致的問題,誕生了快取一致性協議,快取一致性協議有很多種實作,比如:MSI、MESI、MOSI、Synapse、Firefly和DragonProtocol等,其中,最著名的快取一致性協議當屬Intel的MESI協議,MESI協議保證了每個快取中使用的共享變數的副本是一致的,
2.2 鎖總線
??某些情況下,快取一致性協議也具有局限性,比如某些資料無法被快取,以及無法保證多個CPU之間的快取一致性,這時候,就需要在總線上加鎖來實作了,
3 偽共享
3.1 什么是偽共享
??當多執行緒修改同一個快取行中互相獨立的變數時,因為CPU需要遵守快取一致性協議,會無意中影響執行緒執行的效率,這就是偽共享,設想在同一個快取行中存放了兩個變數a和b,這個快取行被加載到core1和core2的快取中,core1要對a進行修改,core2要對b進行修改,當core1修改了a必然會影響到core2,同理當core2修改了b必然會影響到core1,兩個核之間需要頻繁地經過L3來同步資料,所以core1和core2的性能會大打折扣,并且更為致命的是,從代碼中并不能知道是否存在偽共享的問題,
3.2 如何預防偽共享問題
??為了預防偽共享產生的性能問題,一般可以借助快取行對齊來實作,比如Disruptor就使用了大量的快取行對齊編碼手段,這是一個將性能提現到極致的單機訊息佇列中間件,將會在后續的文章中進行具體介紹,
4 指令重排序
4.1 CPU的指令重排序
??現代處理器為了提升其指令執行的效率,采用了指令級并行技術(Instruction-LevelParallelism,ILP)來將多條指令重疊執行,如果不存在資料依賴性,處理器可以改變陳述句對應機器指令的執行順序,
4.2 編譯器指令重排序
??編譯源代碼時,編譯器依據對背景關系的分析,對指令進行重排序,以之更適合于CPU的并行執行,
5 防止指令重排序
??某些情況下,我們并不希望指令重排序發生,參考《多執行緒之volatile》,在硬體層面,由硬體記憶體屏障和原子指令防止指令重排序,而在JVM層面,是由JVM記憶體屏障來實作的,而JVM的記憶體屏障最侄訓是需要依賴于硬體的實作,
5.1 硬體層面防止指令重排序
5.1.1 硬體記憶體屏障
??在硬體層面,主要是利用CPU的記憶體屏障來禁止指令重排序,x86架構的CPU,有三種記憶體屏障:
- sfence(Store Fence):在sfence指令前的寫操作當必須在sfence指令后的寫操作前完成,
- lfence(Load Fence):在lfence指令前的讀操作當必須在lfence指令后的讀操作前完成,
- mfence(Memory Fence):在mfence指令前的讀寫操作當必須在mfence指令后的讀寫操作前完成,
5.1.2 原子指令
??除了記憶體屏障以外,還可以通過原子指令來實作禁止指令重排序,如x86上的lock指令,這個lock指令其實是一個Full Barrier,執行時會鎖住記憶體子系統來確保執行順序,甚至跨多個CPU,
5.2 JVM規范(JSR133)
??JVM規范中定義了四種記憶體屏障:
- LoadLoad:對于這樣的陳述句Load1; LoadLoad; Load2,在Load2及后續讀取操作要讀取的資料被訪問前,保證Load1要讀取的資料被讀取完畢,
- StoreStore:對于這樣的陳述句Store1; StoreStore; Store2,在Store2及后續寫入操作執行前,保證Store1的寫入操作對其它處理器可見,
- LoadStore:對于這樣的陳述句Load1; LoadStore; Store2,在Store2及后續寫入操作被刷出前,保證Load1要讀取的資料被讀取完畢,
- StoreLoad:對于這樣的陳述句Store1; StoreLoad; Load2,在Load2及后續所有讀取操作執行前,保證Store1的寫入對所有處理器可見,
??JVM只是對記憶體屏障定義了一個規范,而不同的虛擬機可能會有不同的實作,但其最終肯定是依賴于硬體來實作的,
5.2.1 volatile
??JVM對于volatile記憶體區的讀寫操作,都會加屏障:
- 在每個寫操作之前加StoreStoreBarrier,
- 在每個寫操作之后加StoreLoadBarrier,
- 在每個讀操作之前加LoadLoadBarrier,
- 在每個讀操作之后加LoadStoreBarrier,
5.2.2 synchronized
??synchronized代碼塊編譯成位元組碼后,會在代碼塊前后加上monitorenter指令和monitorexit指令,其在JVM中呼叫了系統提供的同步機制(C或C++實作),而在硬體層面,是通過lock comxchg指令實作(x86架構),
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/281224.html
標籤:其他
上一篇:訊息佇列和郵件發送