寫在前面:博主是一只經過實戰開發歷練后投身培訓事業的“小山豬”,昵稱取自影片片《獅子王》中的“彭彭”,總是以樂觀、積極的心態對待周邊的事物,本人的技術路線從Java全堆疊工程師一路奔向大資料開發、資料挖掘領域,如今終有小成,愿將昔日所獲與大家交流一二,希望對學習路上的你有所助益,同時,博主也想通過此次嘗試打造一個完善的技術圖書館,任何與文章技術點有關的例外、錯誤、注意事項均會在末尾列出,歡迎大家通過各種方式提供素材,
- 對于文章中出現的任何錯誤請大家批評指出,一定及時修改,
- 有任何想要討論和學習的問題可聯系我:zhuyc@vip.163.com,
- 發布文章的風格因專欄而異,均自成體系,不足之處請大家指正,
演算法導論之經典演算法:快速排序全面決議
本文關鍵字:演算法導論、經典演算法、交換排序、快速排序、演算法實踐
文章目錄
- 演算法導論之經典演算法:快速排序全面決議
- 一、什么是演算法
- 1. 演算法的定義
- 2. 補充的概念
- 二、交換排序
- 1. 交換排序介紹
- 2. 快速排序
- 3. 偽代碼
- 三、演算法實踐
- 1. 演算法實作
- 2. 時間復雜度
- 3. 空間復雜度
一、什么是演算法
本專欄為《手撕演算法》欄目的子專欄:《演算法導論》,會講述一些經典演算法,并進行分析,在此之前我們要先了解什么是演算法,能夠解決什么樣的問題,
1. 演算法的定義
以下為經典教材《Introduction.to.Algorithms》開篇中的內容,
Informally, an algorithm is any well-de?ned computational procedure that takes some value, or set of values, as input and produces some value, or set of values, as output. An algorithm is thus a sequence of computational steps that transform the input into the output.
可以看到,任何被明確定義的計算程序都可以稱作演算法,它將某個值或一組值作為輸入,并產生某個值或一組值作為輸出,所以演算法可以被稱作將輸入轉為輸出的一系列的計算步驟,
這樣的概括是比較標準和抽象的,其實說白了就是步驟明確的解決問題的方法,由于是在計算機中執行,所以通常先用偽代碼來表示,清晰的表達出思路和步驟,這樣在真正執行的時候,就可以使用不同的語言來實作出相同的效果,
概括的說,演算法就是解決問題的工具,在描述一個演算法時,我們關注的是輸入與輸出,也就是說只要把原始資料和結果資料描述清楚了,那么演算法所做的事情也就清楚了,我們在設計一個演算法時也是需要先明確我們有什么和我們要什么,這一點相信大家在后面的文章中會慢慢體會到,
2. 補充的概念
- 資料結構
演算法經常會和資料結構一起出現,這是因為對于同一個問題(如:排序),使用不同的資料結構來存盤資料,對應的演算法可能千差萬別,所以在整個學習程序中,也會涉及到各種資料結構的使用,
常見的資料結構包括:陣列、堆、堆疊、佇列、鏈表、樹等等,
- 演算法的效率
在一個演算法設計完成后,還需要對演算法的執行情況做一個評估,一個好的演算法,可以大幅度的節省運行的資源消耗和時間,在進行評估時不需要太具體,畢竟資料量是不確定的,通常是以資料量為基準來確定一個量級,通常會使用到時間復雜度和空間復雜度這兩個概念,
- 時間復雜度
通常把演算法中的基本操作重復執行的頻度稱為演算法的時間復雜度,演算法中的基本操作一般是指演算法中最深層回圈內的陳述句(賦值、判斷、四則運算等基礎操作),我們可以把時間頻度記為T(n),它與演算法中陳述句的執行次數成正比,其中的n被稱為問題的規模,大多數情況下為輸入的資料量,
對于每一段代碼,都可以轉化為常數或與n相關的函式運算式,記做f(n),如果我們把每一段代碼的花費的時間加起來就能夠得到一個刻畫時間復雜度的運算式,在合并后保留量級最大的部分即可確定時間復雜度,記做O(f(n)),其中的O就是代表數量級,
常見的時間復雜度有(由低到高):O(1)、O(
log
?
2
n
\log _{2} n
log2?n)、O(n)、O(
n
log
?
2
n
n\log _{2} n
nlog2?n)、O(
n
2
n^{2}
n2)、O(
n
3
n^{3}
n3)、O(
2
n
2^{n}
2n)、O(n!),
- 空間復雜度
程式從開始執行到結束所需要的記憶體容量,也就是整個程序中最大需要占用多少的空間,為了評估演算法本身,輸入資料所占用的空間不會考慮,通常更關注演算法運行時需要額外定義多少臨時變數或多少存盤結構,如:如果需要借助一個臨時變數來進行兩個元素的交換,則空間復雜度為O(1),
- 偽代碼約定
偽代碼是用來描述演算法執行的步驟,不會具體到某一種語言,為了表達清晰和標準化,會有一些約定的含義:
縮進:表示塊結構,如回圈結構或選擇結構,使用縮進來表示這一部分都在該結構中,
回圈計數器:對于回圈結構,在回圈終止時,計數器的值應該為第一個超出界限的值,
to:表示回圈計數器的值增加,
downto:表示回圈計數器的值減少,
by:回圈計數器的值默認變化量為1,當大于1時可以使用by,
變數默認是區域定義的,
陣列元素訪問:通過"陣列名[下標]"形式,在偽代碼中,下標從1開始("A[1]“代表陣列A的第一個元素),
子陣列:使用”…"來代表陣列中的一個范圍,如"A[i…j]"代表從第i個到第j個元素組成的子陣列,
物件與屬性:復合的資料會被組織成物件,如鏈表包含后繼(next)和存盤的資料(data),使用“物件名 + 點 + 屬性名”,
特殊值NIL:表示指標不指向任何物件,如二叉樹節點無子孩子可認為左右子節點資訊為NIL,
return:回傳到呼叫程序的呼叫點,在偽代碼中允許回傳多個值,
and和or:與運算和或運算默認短路,即如果已經能夠確定運算式結果時,其他條件不會去判斷或執行,
二、交換排序
1. 交換排序介紹
交換排序的核心思想是,每次將元素兩兩比較,如果不滿足正確的相對序列(如:較小的應該在前)則進行交換,不斷的根據某個規律進行比較和交換,直到全部滿足為止,此時也就得到了一個有序的序列,
- 冒泡排序
也稱氣泡排序,是經典的交換排序方法,整個程序就是在無序區中對相鄰元素進行兩兩比較,將不滿足相對順序的一對兒元素進行交換,再進行下一對兒元素的比較,每一趟冒泡后,就會送一個最小的元素達到最上端,在無序區中重復這個程序,直到所有的元素有序,
文章傳送門:演算法導論之經典演算法:冒泡排序全面決議
- 快速排序
快速排序是冒泡排序的改進演算法,主要思想是在待排序列中取一個元素(通常為第一個)作為參照,將序列分為兩個子序列,比參照值小的元素和比參照值大的元素各自組成一個子序列,每趟排序會使參照元素歸位,并得到兩個子序列,在子序列中繼續執行該步驟,直到子序列的長度為0或1,
2. 快速排序
- 輸入
n個數的序列,通常直接存放在陣列中,可能是任何順序,
- 輸出
輸入序列的一個新排列,滿足從小到大的順序(默認討論升序,簡單的修改就可以實作降序排列),
- 演算法說明
快速排序是一種劃分交換排序方法,采用了分治策略,首先將原問題劃分成若干個規模更小、與原問題相似的子問題,然后用遞回方法解決這些子問題,最后再將它們組合成原問題的解,
第一趟排好序列中的一個數,放在它應該在的位置上,同時得到兩個子序列,左側都是比它小的數,右側都是比它大的數(升序排序時),接下來在每個子序列中不斷重復歸位一個元素、得到子序列這個程序,直到子序列的長度為1或0,此時整體的序列已經有序,
- 演算法流程
以下為第一趟排序的程序,選定一個待排元素x后,不斷縮小無限制區域,使得得到的兩個子序列(兩個區域)滿足其中一個都比x小,另一個都比x大,最后將待排元素插入到兩個區間中間即完成排序(暫不考慮存在相同元素),
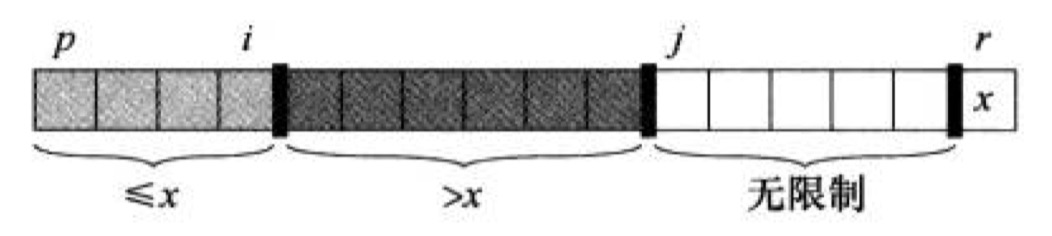
以下圖片取材自《演算法導論》,完成第一趟排序后,不斷的在得到的子序列中重復該步驟:
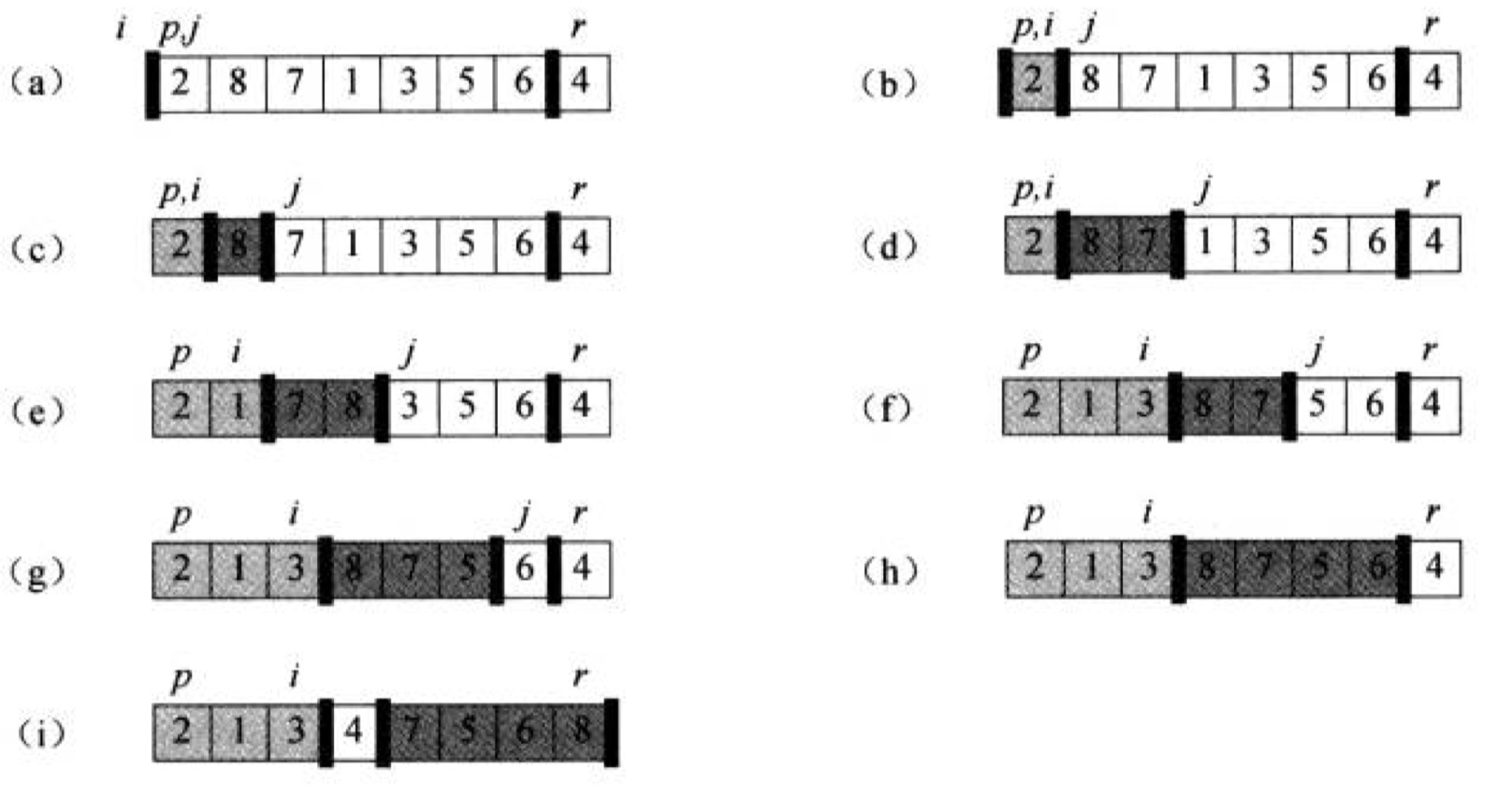
- (a)將待排元素選定為序列的最后一個元素:4,目標是在左側的無序區中劃分出兩個子序列,
- p為序列區間左端點,r為序列區間右端點,
- i的初始值在區間端點之前,用于劃分出較小元素所在區間,
- j為進行掃描時使用的變數,每次取到元素進行判斷,然后進行區間的調整,
- p與i之間的部分構成淺色區域(較小數區間),i與j之間的部分構成深色區域(較大數區間),
- (b)2 < 4,應歸入較小數區間,i進行后移(此時i與j指向同一元素),并與j指向的元素交換,淺色區域增加,
- (c)8 > 4,應歸入較大數區間,j正常后移,深色區域增加,
- (d)7 > 4,應歸入較大數區間,j正常后移,深色區域增加,
- (e)1 < 4,應歸入較小數區間,i進行后移,并與j指向的元素交換,淺色區域增加,
- (f)3 < 4,應歸入較小數區間,i進行后移,并與j指向的元素交換,淺色區域增加,
- (g)5 > 4,應歸入較大數區間,j正常后移,深色區域增加,
- (h)6 > 4,應歸入較大數區間,j正常后移,深色區域增加,
- (i)此時j已達到邊界,最后只需要將**深色區域的首個元素(8)與待排元素(4)**交換,
注:有關于子序列的劃分方式有多種實作方法,如還可以采用從兩端不斷同時向中間靠近的方式,大家可以自行實作,
3. 偽代碼
在快速排序中使用到了遞回的操作,在撰寫偽代碼時可以使用FUNCTION來宣告定義一個函式名稱,以進行呼叫:
FUNCTION PARTITION(A,p,r)
x = A[r]
i = p - 1
for j = p to r - 1
if a[j] < x
i = i + 1
exchange A[i] with A[j]
exchange A[i + 1] with A[r]
return i + 1
PARTITION函式的作用是進行第一趟排序,排好一個元素,并得到兩個子序列,回傳值就是接下來劃分子序列的參照,
FUNCTION QUICKSORT(A,p,r)
if p < r
q = PARTITION(A,p,r)
QUICKSORT(A,p,q-1)
QUICKSORT(A,q+1,r)
QUICKSORT函式中進行了遞回的操作,將原問題分解為一系列的子問題,每次都在序列上進行劃分、呼叫的操作,每次不斷的改變區間的長度,直到不需要再劃分為止,
三、演算法實踐
1. 演算法實作
- 輸入資料(input):2,8,7,1,3,5,6,4
- Java源代碼
演算法中用到了遞回呼叫,對于遞回還不太理解的小伙伴可以進傳送門:Java方法的嵌套與遞回呼叫,
public class QuickSort {
public static void main(String[] args) {
// input data
int[] a = {2,8,7,1,3,5,6,4};
// 呼叫快速排序,傳入初始的左右端點
quickSort(a,0,a.length - 1);
// 查看排序結果
for (int data : a){
System.out.print(data + "\t");
}
}
private static int partition(int[] a,int p,int r){
// 宣告待排元素
int x = a[r];
// 初始化較小數區間端點
int i = p - 1;
// 回圈結束后,區間已經劃定完畢
for(int j = p;j < r;j++){
// 將較小的數向前扔
if(a[j] < x){
i++;
// 交換兩個元素
int tmp = a[i];
a[i] = a[j];
a[j] = tmp;
}
}
// 交換待排元素到指定位置
int tmp = a[i + 1];
a[i + 1] = a[r];
a[r] = tmp;
return i + 1;
}
private static void quickSort(int[] a,int p,int r){
// 重要:遞回的出口(終止條件)為區間長度小于1
if(p < r){
// 劃分后得到已排好元素的位置
int q = partition(a,p,r);
// 根據位置得到較小數列區間
quickSort(a,p,q-1);
// 根據位置得到較大數序列區間
quickSort(a,q + 1,r);
}
}
}
推薦大家使用debug的方式來具體查看一下演算法的整個執行程序,
- 執行效果

2. 時間復雜度
對于快速排序有個小小不確定的因素就是每次待排元素的選擇,其實并不是固定的,但是由于序列也是隨機的,所以我們可以忽略這個小問題,
對于快速排序來說,由于無論如何劃分,比較的次數都是固定的,不會超過O(n),那么劃分的次數就尤為重要了,這也是重點分析的方面,
- 最壞的情況
如果初始序列已經有序時,可以試想一下,每次排好一個元素,并且都要挨個比較一次,重點是劃分得到的子序列只有一個,如果按照上文,每次選取區間右端點作為待排元素,那么每次只會得到一個較小子序列,在這個序列中再次重復劃分的步驟,同樣只能得到一個較小子序列,這種情況其實就和冒泡排序的程序很相似了,都是每次只排好一個元素,對其他元素都要比較一遍,此時的時間復雜度為O( n 2 n^{2} n2),
- 最好的情況
由于演算法是不斷在子序列上遞回執行的,如果說每次待排元素都恰好處在中間位置,將原有序列分成兩個等長的子序列,每次劃分都是這樣的情況,那么總共的劃分次數就可以用O( l o g 2 n log _{2} n log2?n)表示,這樣時間復雜度可以在O( n log ? 2 n n\log _{2} n nlog2?n),
- 平均情況
對于快速排序來說,是基于關鍵字比較的內部排序演算法中速度最快的,平均性能可以達到O( n log ? 2 n n\log _{2} n nlog2?n),
3. 空間復雜度
由于使用到了遞回操作,所以在執行程序中需要在堆疊中保存相關資訊,需要的空間就和遞回次數直接相關,可以知道,在平均情況下,需要O( l o g 2 n log _{2} n log2?n),在最壞的情況下,不會超過O(n),
掃描下方二維碼,加入官方粉絲微信群,可以與我直接交流,還有更多福利哦~

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/281304.html
標籤:其他
上一篇:Vue全家桶:Vuex