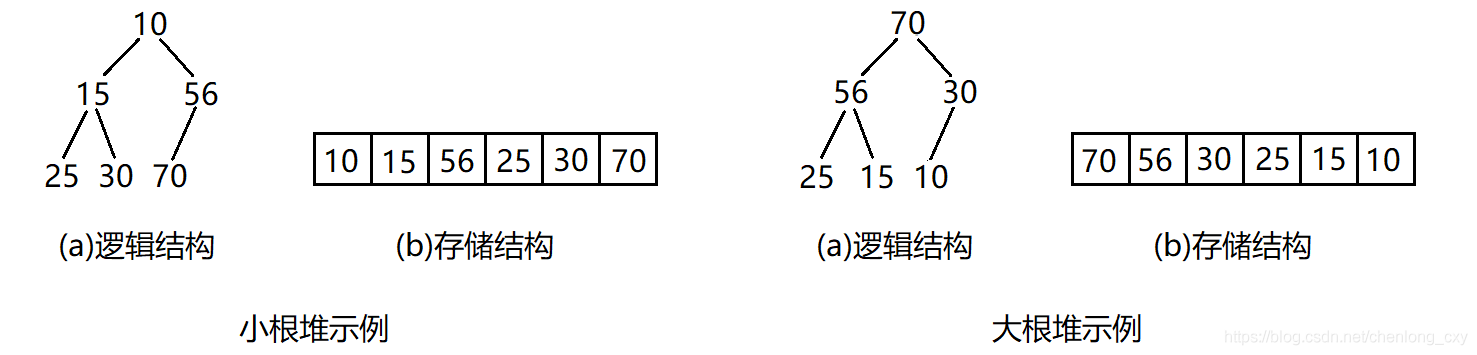
堆的介紹
堆的概念
堆:如果有一個關鍵碼的集合K={k0,k1,k2,…,kn-1},把它的所有元素按完全二叉樹的順序存盤方式存盤在一個一維陣列中,并滿足ki<=k2i+1且ki<=k2i+2(或滿足ki>=k2i+1且ki>=k2i+2),其中i=0,1,2,…,則稱該集合為堆,
小堆:將根結點最小的堆叫做小堆,也叫最小堆或小根堆,
大堆:將根結點最大的堆叫做大堆,也叫最大堆或大根堆,
堆的性質:
?堆中某個結點的值總是不大于或不小于其父結點的值,
?堆總是一棵完全二叉樹,
堆的結構
堆的向下調整演算法
?現在我們給出一個陣列,邏輯上看作一棵完全二叉樹,我們通過從根節點開始的向下調整演算法可以把它調整成一個小堆,
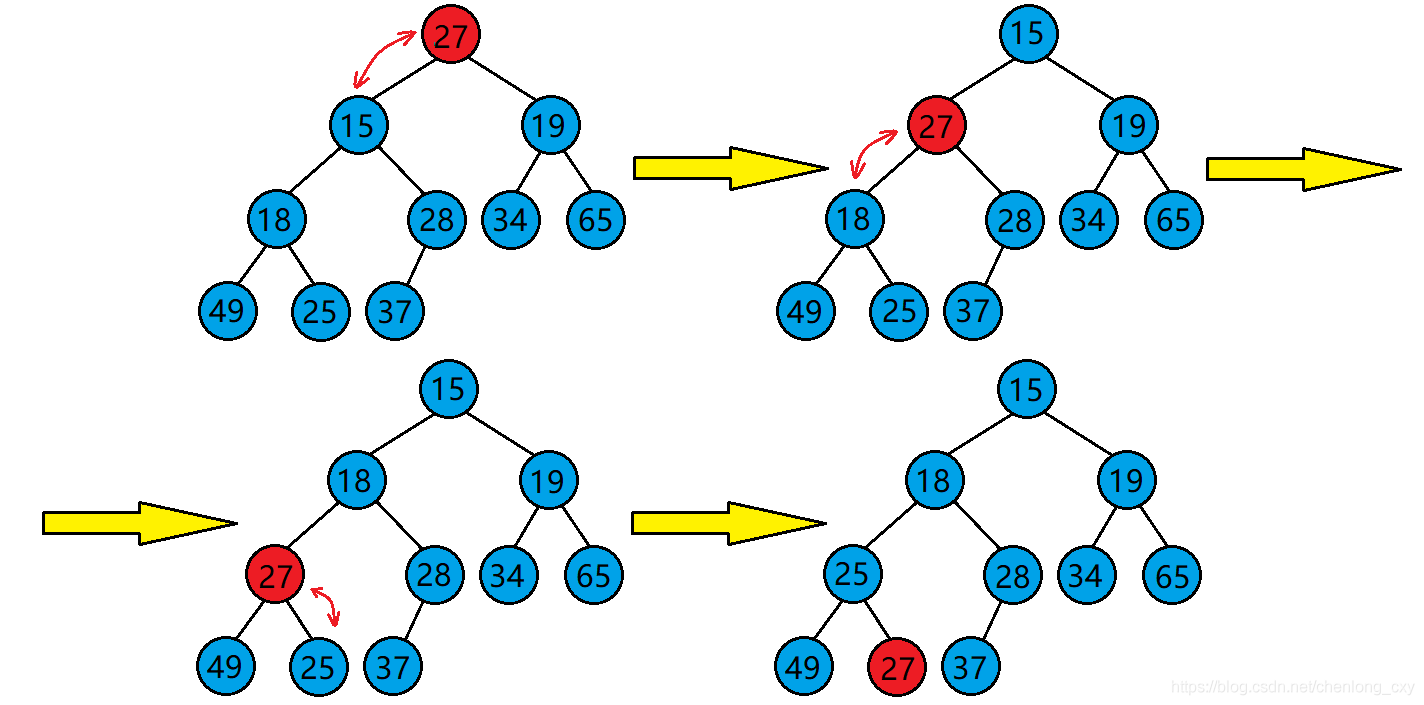
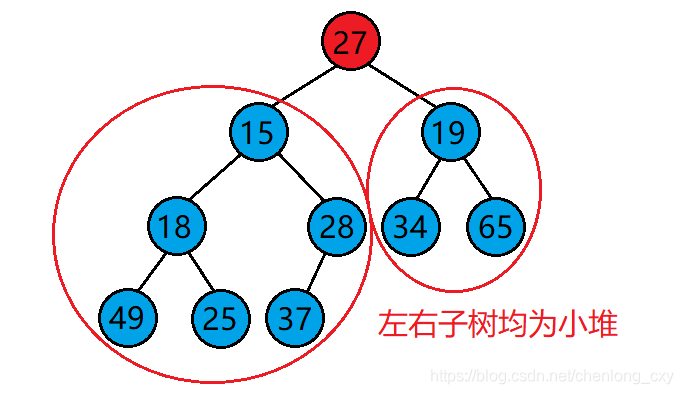
但是,使用向下調整演算法需要滿足一個前提:
?若想將其調整為小堆,那么根結點的左右子樹必須都為小堆,
?若想將其調整為大堆,那么根結點的左右子樹必須都為大堆,
向下調整演算法的基本思想(以建小堆為例):
?1.從根結點處開始,選出左右孩子中值較小的孩子,
?2.讓小的孩子與其父親進行比較,
?若小的孩子比父親還小,則該孩子與其父親的位置進行交換,并將原來小的孩子的位置當成父親繼續向下進行調整,直到調整到葉子結點為止,
?若小的孩子比父親大,則不需處理了,調整完成,整個樹已經是小堆了,
代碼如下:
//交換函式
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
//堆的向下調整(小堆)
void AdjustDown(int* a, int n, int parent)
{
//child記錄左右孩子中值較小的孩子的下標
int child = 2 * parent + 1;//先默認其左孩子的值較小
while (child < n)
{
if (child + 1 < n&&a[child + 1] < a[child])//右孩子存在并且右孩子比左孩子還小
{
child++;//較小的孩子改為右孩子
}
if (a[child] < a[parent])//左右孩子中較小孩子的值比父結點還小
{
//將父結點與較小的子結點交換
Swap(&a[child], &a[parent]);
//繼續向下進行調整
parent = child;
child = 2 * parent + 1;
}
else//已成堆
{
break;
}
}
}
?使用堆的向下調整演算法,最壞的情況下(即一直需要交換結點),需要回圈的次數為:h - 1次(h為樹的高度),而h = log2(N+1)(N為樹的總結點數),所以堆的向下調整演算法的時間復雜度為:O(logN) ,
?上面說到,使用堆的向下調整演算法需要滿足其根結點的左右子樹均為大堆或是小堆才行,那么如何才能將一個任意樹調整為堆呢?
?答案很簡單,我們只需要從倒數第一個非葉子結點開始,從后往前,按下標,依次作為根去向下調整即可,
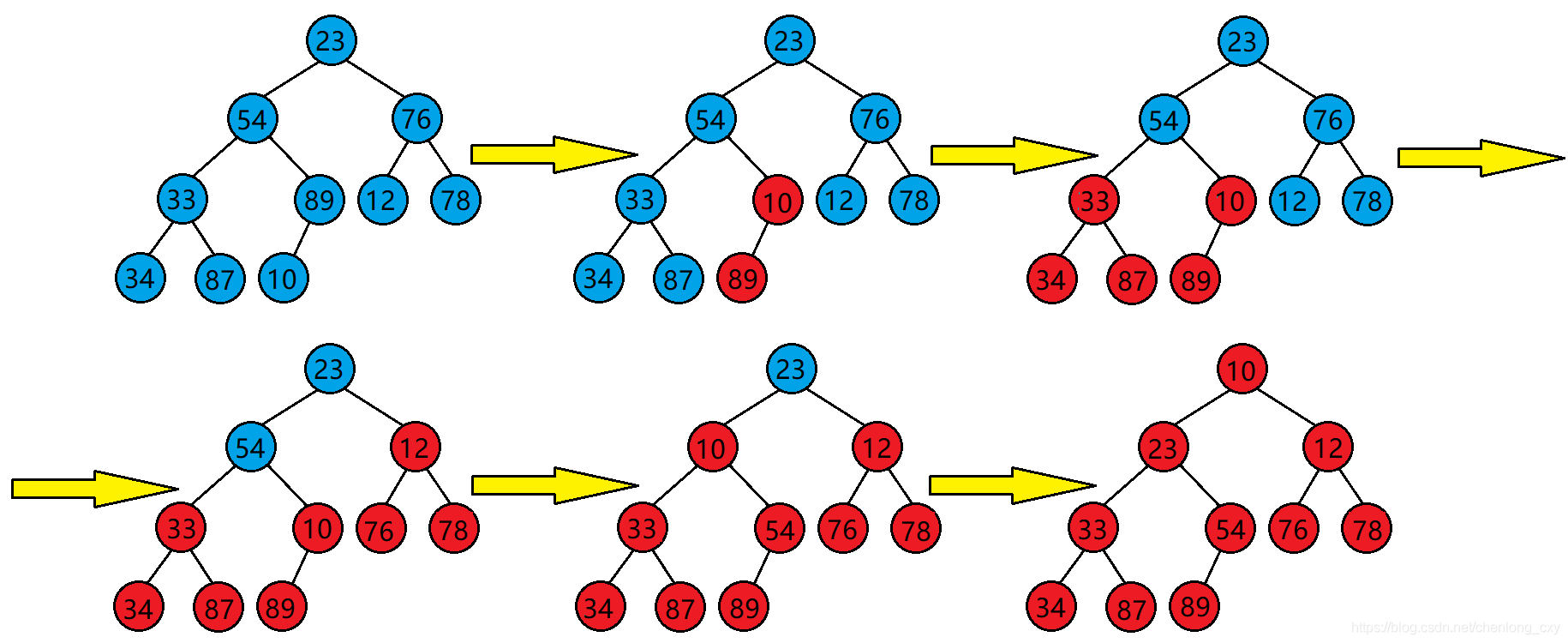
代碼:
//建堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(php->a, php->size, i);
}
那么建堆的時間復雜度又是多少呢?
?當結點數無窮大時,完全二叉樹與其層數相同的滿二叉樹相比較來說,它們相差的結點數可以忽略不計,所以計算時間復雜度的時候我們可以將完全二叉樹看作與其層數相同的滿二叉樹來進行計算,
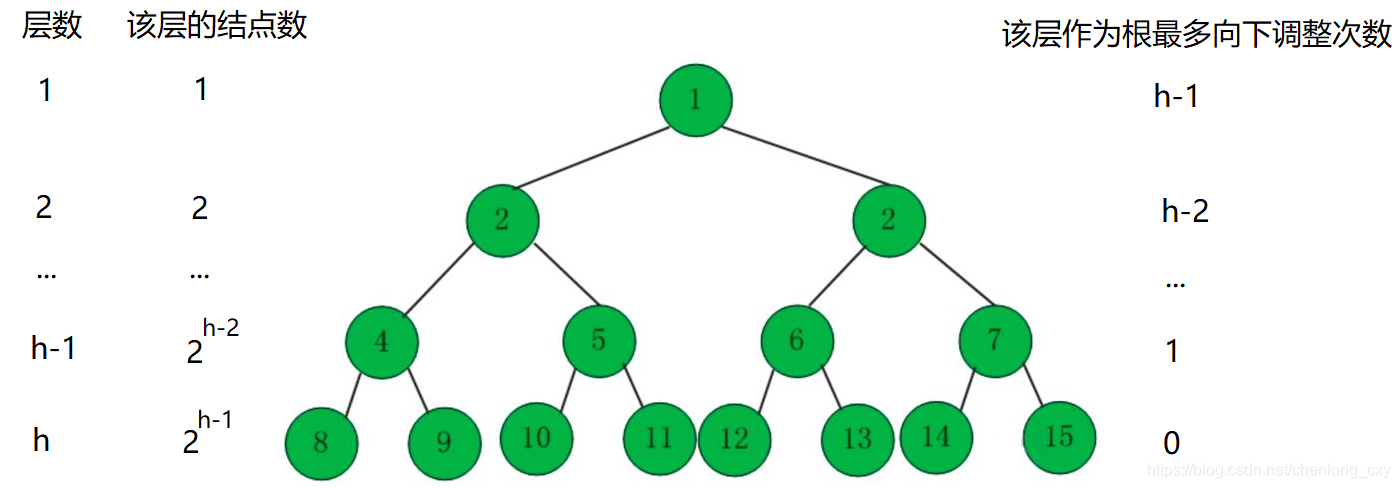
我們計算建堆程序中總共交換的次數:
T
(
n
)
=
1
×
(
h
?
1
)
+
2
×
(
h
?
2
)
+
.
.
.
+
2
h
?
3
×
2
+
2
h
?
2
×
1
T(n) = 1\times(h-1) + 2\times(h-2) + ... + 2^{h-3}\times2 + 2^{h-2}\times1
T(n)=1×(h?1)+2×(h?2)+...+2h?3×2+2h?2×1
兩邊同時乘2得:
2
T
(
n
)
=
2
×
(
h
?
1
)
+
2
2
×
(
h
?
2
)
+
.
.
.
+
2
h
?
2
×
2
+
2
h
?
1
×
1
2T(n) = 2\times(h-1) + 2^2\times(h-2) + ... + 2^{h-2}\times2 + 2^{h-1}\times1
2T(n)=2×(h?1)+22×(h?2)+...+2h?2×2+2h?1×1
兩式相減得:
T
(
n
)
=
1
?
h
+
2
1
+
2
2
+
.
.
.
+
2
h
?
2
+
2
h
?
1
T(n)=1-h+2^1+2^2+...+2^{h-2}+2^{h-1}
T(n)=1?h+21+22+...+2h?2+2h?1
運用等比數列求和得:
T
(
n
)
=
2
h
?
h
?
1
T(n)=2^h-h-1
T(n)=2h?h?1
由二叉樹的性質,有
N
=
2
h
?
1
N=2^h-1
N=2h?1和
h
=
log
?
2
(
N
+
1
)
h=\log_2(N+1)
h=log2?(N+1),于是
T
(
n
)
=
N
?
log
?
2
(
N
+
1
)
T(n)=N-\log_2(N+1)
T(n)=N?log2?(N+1)
用大O的漸進表示法:
T
(
n
)
=
O
(
N
)
T(n)=O(N)
T(n)=O(N)
總結一下:
?堆的向下調整演算法的時間復雜度:
T
(
n
)
=
O
(
log
?
N
)
T(n)=O(\log N)
T(n)=O(logN),
?建堆的時間復雜度:
T
(
n
)
=
O
(
N
)
T(n)=O(N)
T(n)=O(N),
堆的向上調整演算法
當我們在一個堆的末尾插入一個資料后,需要對堆進行調整,使其仍然是一個堆,這時需要用到堆的向上調整演算法,
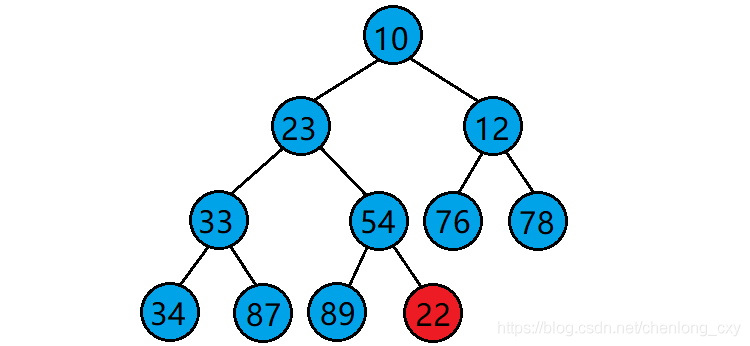
向上調整演算法的基本思想(以建小堆為例):
?1.將目標結點與其父結點比較,
?2.若目標結點的值比其父結點的值小,則交換目標結點與其父結點的位置,并將原目標結點的父結點當作新的目標結點繼續進行向上調整,若目標結點的值比其父結點的值大,則停止向上調整,此時該樹已經是小堆了,
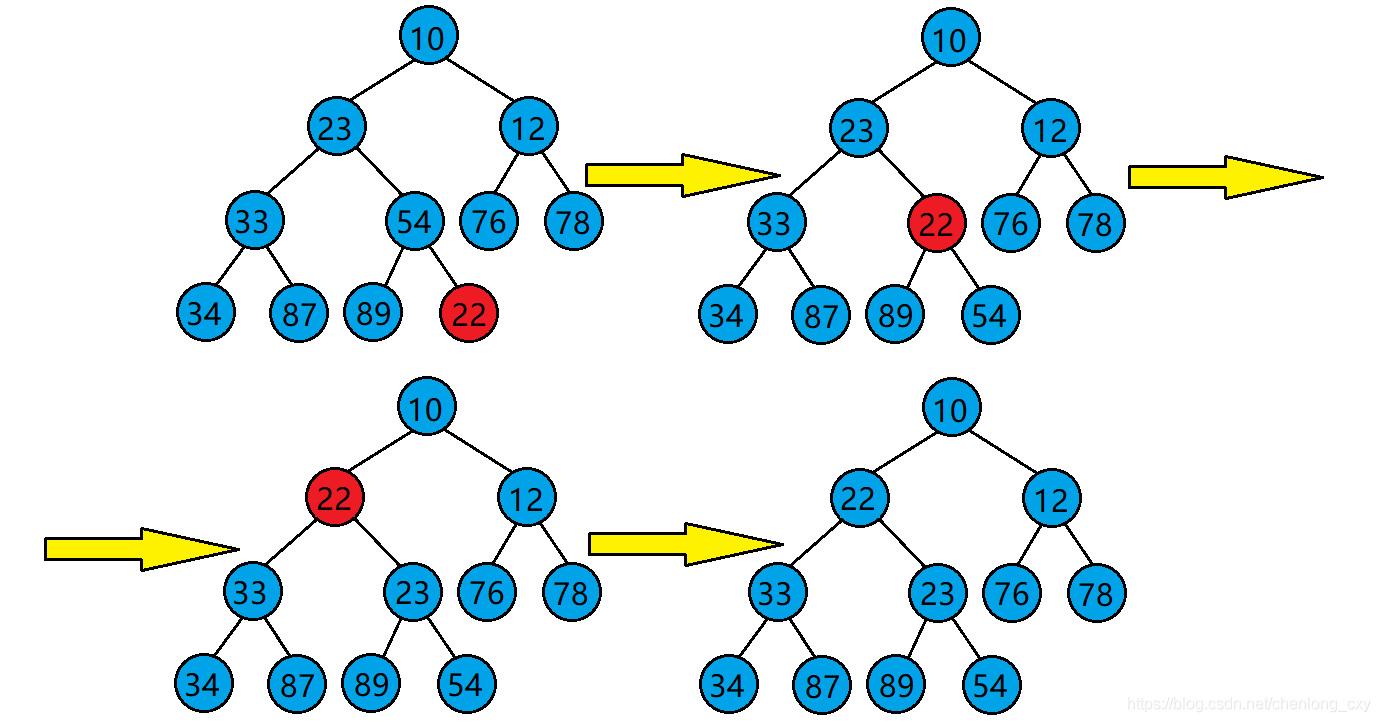
代碼如下:
//交換函式
void Swap(HPDataType* x, HPDataType* y)
{
HPDataType tmp = *x;
*x = *y;
*y = tmp;
}
//堆的向上調整(小堆)
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)//調整到根結點的位置截止
{
if (a[child] < a[parent])//孩子結點的值小于父結點的值
{
//將父結點與孩子結點交換
Swap(&a[child], &a[parent]);
//繼續向上進行調整
child = parent;
parent = (child - 1) / 2;
}
else//已成堆
{
break;
}
}
}
堆的實作
初始化堆
?首先,必須創建一個堆型別,該型別中需包含堆的基本資訊:存盤資料的陣列、堆中元素的個數以及當前堆的最大容量,
typedef int HPDataType;//堆中存盤資料的型別
typedef struct Heap
{
HPDataType* a;//用于存盤資料的陣列
int size;//記錄堆中已有元素個數
int capacity;//記錄堆的容量
}HP;
?然后我們需要一個初始化函式,對剛創建的堆進行初始化,注意在初始化期間要將傳入資料建堆,
//初始化堆
void HeapInit(HP* php, HPDataType* a, int n)
{
assert(php);
HPDataType* tmp = (HPDataType*)malloc(sizeof(HPDataType)*n);//申請一個堆結構
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
php->a = tmp;
memcpy(php->a, a, sizeof(HPDataType)*n);//拷貝資料到堆中
php->size = n;
php->capacity = n;
int i = 0;
//建堆
for (i = (php->size - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(php->a, php->size, i);
}
}
銷毀堆
?為了避免記憶體泄漏,使用完動態開辟的記憶體空間后都要及時釋放該空間,所以,一個用于釋放記憶體空間的函式是必不可少的,
//銷毀堆
void HeapDestroy(HP* php)
{
assert(php);
free(php->a);//釋放動態開辟的陣列
php->a = NULL;//及時置空
php->size = 0;//元素個數置0
php->capacity = 0;//容量置0
}
列印堆
?列印堆中的資料,這里用了兩種列印格式,第一種列印格式是按照堆的物理結構進行列印,即列印為一排連續的數字,第二種列印格式是按照堆的邏輯結構進行列印,即列印成樹形結構,
//求結點數為n的二叉樹的深度
int depth(int n)
{
assert(n >= 0);
if (n>0)
{
int m = 2;
int hight = 1;
while (m < n + 1)
{
m *= 2;
hight++;
}
return hight;
}
else
{
return 0;
}
}
//列印堆
void HeapPrint(HP* php)
{
assert(php);
//按照物理結構進行列印
int i = 0;
for (i = 0; i < php->size; i++)
{
printf("%d ", php->a[i]);
}
printf("\n");
//按照樹形結構進行列印
int h = depth(php->size);
int N = (int)pow(2, h) - 1;//與該二叉樹深度相同的滿二叉樹的結點總數
int space = N - 1;//記錄每一行前面的空格數
int row = 1;//當前列印的行數
int pos = 0;//待列印資料的下標
while (1)
{
//列印前面的空格
int i = 0;
for (i = 0; i < space; i++)
{
printf(" ");
}
//列印資料和間距
int count = (int)pow(2, row - 1);//每一行的數字個數
while (count--)//列印一行
{
printf("%02d", php->a[pos++]);//列印資料
if (pos >= php->size)//資料列印完畢
{
printf("\n");
return;
}
int distance = (space + 1) * 2;//兩個數之間的空格數
while (distance--)//列印兩個數之間的空格
{
printf(" ");
}
}
printf("\n");
row++;
space = space / 2 - 1;
}
}
堆的插入
?資料插入時是插入到陣列的末尾,即樹形結構的最后一層的最后一個結點,所以插入資料后我們需要運用堆的向上調整演算法對堆進行調整,使其在插入資料后仍然保持堆的結構,
//堆的插入
void HeapPush(HP* php, HPDataType x)
{
assert(php);
if (php->size == php->capacity)
{
HPDataType* tmp = (HPDataType*)realloc(php->a, 2 * php->capacity*sizeof(HPDataType));
if (tmp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
php->a = tmp;
php->capacity *= 2;
}
php->a[php->size] = x;
php->size++;
//向上調整
AdjustUp(php->a, php->size - 1);
}
堆的洗掉
?堆的洗掉,洗掉的是堆頂的元素,但是這個洗掉程序可并不是直接洗掉堆頂的資料,而是先將堆頂的資料與最后一個結點的位置交換,然后再洗掉最后一個結點,再對堆進行一次向下調整,
?原因:我們若是直接洗掉堆頂的資料,那么原堆后面資料的父子關系就全部打亂了,需要全體重新建堆,時間復雜度為
O
(
N
)
O(N)
O(N),若是用上述方法,那么只需要對堆進行一次向下調整即可,因為此時根結點的左右子樹都是小堆,我們只需要在根結點處進行一次向下調整即可,時間復雜度為
O
(
log
?
(
N
)
)
O(\log(N))
O(log(N)),
//堆的洗掉
void HeapPop(HP* php)
{
assert(php);
assert(!HeapEmpty(php));
Swap(&php->a[0], &php->a[php->size - 1]);//交換堆頂和最后一個結點的位置
php->size--;//洗掉最后一個結點(也就是洗掉原來堆頂的元素)
AdjustDown(php->a, php->size, 0);//向下調整
}
獲取堆頂的資料
獲取堆頂的資料,即回傳陣列下標為0的資料,
//獲取堆頂的資料
HPDataType HeapTop(HP* php)
{
assert(php);
assert(!HeapEmpty(php));
return php->a[0];//回傳堆頂資料
}
獲取堆的資料個數
獲取堆的資料個數,即回傳堆結構體中的size變數,
//獲取堆中資料個數
int HeapSize(HP* php)
{
assert(php);
return php->size;//回傳堆中資料個數
}
堆的判空
堆的判空,即判斷堆結構體中的size變數是否為0,
//堆的判空
bool HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;//判斷堆中資料是否為0
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/281684.html
標籤:其他