哈嘍,大家好,我終于回來了!19號剛提交完大論文,就被抓去出差了,折騰了整整一周,26號晚上,才回到學校,鴿了好久都沒更新干貨了,今天更新一篇關于Arm的筆試面試題目,文章內容已同步更新在github,
ARM體系與架構
硬體基礎
NAND FLASH 和NOR FLASH異同?
不同點
| 類別 | NOR | NAND |
|---|---|---|
| 讀 | 快 像訪問SRAM一樣,可以隨機訪問任意地址的資料;如:unsighed short *pwAddr = (unsighed short *)0x02;unisignded short wVal;wVal = *pwAddr | 快,有嚴格的時序要求,需要通過一個函式才能讀取資料,先發送讀命令->發送地址->判斷nandflash是否就緒->讀取一頁資料讀命令、發送地址、判斷狀態、讀資料都是通過操作暫存器實作的,如資料暫存器NFDATA |
| 寫 | 慢,寫之前需要擦除,因為寫只能是1->0,擦除可以使0->1 | 快,寫之前需要擦除,因為寫只能是1->0,擦除可以使0->1 |
| 擦除 | 非常慢(5S) | 快(3ms) |
| XIP | 代碼可以直接在NOR FLASH上運行 | NO |
| 可靠性 | 比較高,位反轉的比例小于NAND FLASH的10% | 比較低,位反轉比較常見,必須有校驗措施 |
| 介面 | 與RAM介面相同,地址和資料總線分開 | I/O介面 |
| 可擦除次數 | 10000~100000 | 100000~1000000 |
| 容量 | 小,1MB~32MB | 大,16MB~512MB |
| 主要用途 | 常用于保存代碼和關鍵資料 | 用于保存資料 |
| 價格 | 高 | 低 |
注意:nandflash和norflash的0地址是不沖突的,norflash占用BANK地址,而nandflash不占用BANK地址,它的0地址是內部的,
相同點
| 1 | 寫之前都要先擦除,因為寫操作只能使1->0,而擦除動作是為了把所有位都變1 |
|---|---|
| 2 | 擦除單元都以塊為單位 |
CPU,MPU,MCU,SOC,SOPC聯系與差別?
1.CPU(Central Processing Unit),是一臺計算機的運算核心和控制核心,CPU由運算器、控制器和暫存器及實作它們之間聯系的資料、控制及狀態的總線構成,差不多所有的CPU的運作原理可分為四個階段:提取(Fetch)、解碼(Decode)、執行(Execute)和寫回(Writeback), CPU從存盤器或高速緩沖存盤器中取出指令,放入指令暫存器,并對指令譯碼,并執行指令,所謂的計算機的可編程性主要是指對CPU的編程,
2.MPU (Micro Processor Unit),叫微處理器(不是微控制器),通常代表一個功能強大的CPU(暫且理解為增強版的CPU吧),但不是為任何已有的特定計算目的而設計的芯片,這種芯片往往是個人計算機和高端作業站的核心CPU,最常見的微處理器是Motorola的68K系列和Intel的X86系列,
3.MCU(Micro Control Unit),叫微控制器,是指隨著大規模集成電路的出現及其發展,將計算機的CPU、RAM、ROM、定時計數器和多種I/O介面集成在一片芯片上,形成芯片級的芯片,比如51,avr這些芯片,內部除了CPU外還有RAM,ROM,可以直接加簡單的外圍器件(電阻,電容)就可以運行代碼了,而MPU如x86,arm這些就不能直接放代碼了,它只不過是增強版的CPU,所以得添加RAM,ROM,
MCU MPU 最主要的區別就睡能否直接運行代碼,MCU有內部的RAM ROM,而MPU是增強版的CPU,需要添加外部RAM ROM才可以運行代碼,
4.SOC(System on Chip),指的是片上系統,MCU只是芯片級的芯片,而SOC是系統級的芯片,它既MCU(51,avr)那樣有內置RAM,ROM同時又像MPU(arm)那樣強大的,不單單是放簡單的代碼,可以放系統級的代碼,也就是說可以運行作業系統(將就認為是MCU集成化與MPU強處理力各優點二合一),
5.SOPC(System On a Programmable Chip)可編程片上系統(FPGA就是其中一種),上面4點的硬體配置是固化的,就是說51單片機就是51單片機,不能變為avr,而avr就是avr不是51單片機,他們的硬體是一次性掩膜成型的,能改的就是軟體配置,說白點就是改代碼,本來是跑流水燈的,改下代碼,變成數碼管,而SOPC則是硬體配置,軟體配置都可以修改,軟體配置跟上面一樣,沒什么好說的,至于硬體,是可以自己構建的也就是說這個芯片是自己構造出來的,這顆芯片我們叫“白片”,什么芯片都不是,把硬體配置資訊下載進去了,他就是相應的芯片了,可以讓他變成51,也可以是avr,甚至arm,同時SOPC是在SOC基礎上來的,所以他也是系統級的芯片,所以記得當把他變成arm時還得加外圍ROM,RAM之類的,不然就是MPU了,
什么是交叉編譯?
在一種計算機環境中運行的編譯程式,能編譯出在另外一種環境下運行的代碼,我們就稱這種編譯器支持交叉編譯,這個編譯程序就叫交叉編譯,簡單地說,就是在一個平臺上生成另一個平臺上的可執行代碼,
這里需要注意的是所謂平臺,實際上包含兩個概念:體系結構(Architecture)、作業系統(OperatingSystem),同一個體系結構可以運行不同的作業系統;同樣,同一個作業系統也可以在不同的體系結構上運行,舉例來說,我們常說的x86 Linux平臺實際上是Intel x86體系結構和Linux for x86作業系統的統稱;而x86 WinNT平臺實際上是Intel x86體系結構和Windows NT for x86作業系統的簡稱,
為什么需要交叉編譯?
有時是因為目的平臺上不允許或不能夠安裝我們所需要的編譯器,而我們又需要這個編譯器的某些特征;有時是因為目的平臺上的資源貧乏,無法運行我們所需要編譯器;有時又是因為目的平臺還沒有建立,連作業系統都沒有,根本談不上運行什么編譯器,
描述一下嵌入式基于ROM的運行方式和基于RAM的運行方式有什么區別?
基于RAM
- 需要把硬碟和其他介質的代碼先加載到ram中,加載程序中一般有重定位的操作,
- 速度比基于ROM的快,可用RAM比基于ROM的少,因為所有的代碼,資料都必須存放在RAM中,
基于ROM
-
速度較基于RAM的慢,因為會有一個把變數,部分代碼等從存盤器(硬碟,flash)搬移到RAM的程序,
-
可用RAM資源比基于RAM的多;
ARM處理器
什么是哈佛結構和馮諾依曼結構?
定義
馮諾依曼結構釆用指令和資料統一編址,使用同條總線傳輸,CPU讀取指令和資料的操作無法重疊,
哈佛結構釆用指令和資料獨立編址,使用兩條獨立的總線傳輸,CPU讀取指令和資料的操作可以重疊,
利弊
馮諾依曼結構主要用于通用計算機領域,需要對存盤器中的代碼和資料頻繁的進行修改,統一編址有利于節約資源,
哈佛結構主要用于嵌入式計算機,程式固化在硬體中,有較高的可靠性、運算速度和較大的吞吐,
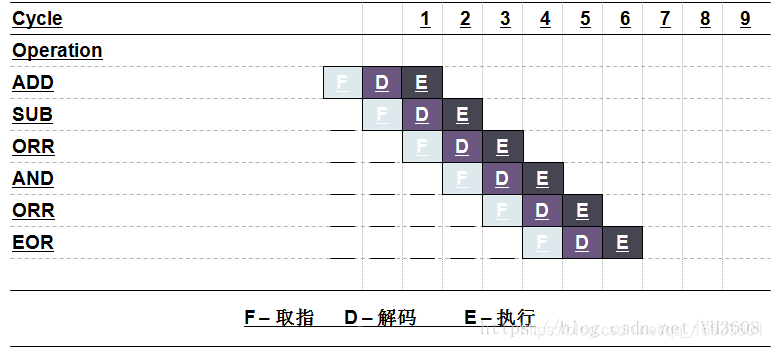
什么是ARM流水線技術?
流水線技術通 過多個功能部件并行作業來縮短程式執行時間,提高處理器核的效率和吞吐率,從而成為微處理器設計中最為重要的技術之一,ARM7處理器核使用了典型三級流水線的馮·諾伊曼結構,ARM9系列則采用了基于五級流水線的哈佛結構,通過增加流水線級數簡化了流水線各級的邏輯,進一步提高了處理器的性能,
PC代表程式計數器,流水線使用三個階段,因此指令分為三個階段執行:1.取指(從存盤器裝載一條指令);2.譯碼(識別將要被執行的指令);3.執行(處理指令并將結果寫回暫存器),而R15(PC)總是指向“正在取指”的指令,而不是指向“正在執行”的指令或正在“譯碼”的指令,一般來說,人們習慣性約定將“正在執行的指令作為參考點”,稱之為當前第一條指令,因此PC總是指向第三條指令,當ARM狀態時,每條指令為4位元組長,所以PC始終指向該指令地址加8位元組的地址,即:PC值=當前程式執行位置+8;
ARM指令是三級流水線,取指,譯指,執行,同時執行的,現在PC指向的是正在取指的地址(下一條指令),那么cpu正在譯指的指令地址是PC-4(假設在ARM狀態下,一個指令占4個位元組),cpu正在執行的指令地址是PC-8,也就是說PC所指向的地址和現在所執行的指令地址相差8,
當突然發生中斷的時候,保存的是PC的地址(PC-8+4 = PC-4 下一條指令的地址)
這樣你就知道了,如果回傳的時候回傳PC,那么中間就有一個指令沒有執行,所以用SUB pc lr-irq #4,
ARM有幾種作業模式?
-
用戶模式(USR)
用戶模式是用戶程式的作業模式,它運行在作業系統的用戶態,它沒有權限去操作其它硬體資源,只能執行處理自己的資料,也不能切換到其它模式下,要想
訪問硬體資源或切換到其它模式只能通過軟中斷或產生例外,
-
系統模式(SYS)
系統模式是特權模式,不受用戶模式的限制,用戶模式和系統模式共用一套暫存器,作業系統在該模式下可以方便的訪問用戶模式的暫存器,而且作業系統的
一些特權任務可以使用這個模式訪問一些受控的資源,
說明:用戶模式與系統模式兩者使用相同的暫存器,都沒有SPSR(Saved Program Statement Register,已保存程式狀態暫存器),但系統模式比用戶模式有更高的權限,可以訪問所有系統資源,
-
一般中斷模式(IRQ)
一般中斷模式也叫普通中斷模式,用于處理一般的中斷請求,通常在硬體產生中斷信號之后自動進入該模式,該模式為特權模式,可以自由訪問系統硬體資源,
-
快速中斷模式(FIQ)
快速中斷模式是相對一般中斷模式而言的,它是用來處理對時間要求比較緊急的中斷請求,主要用于高速資料傳輸及通道處理中,(快中斷有許多(R8~R14)自己的專用暫存器,發生中斷時,使用自己的暫存器就避免了保存和恢復某些暫存器,如果例外中斷處理程式中使用它自己的物理暫存器之外的其他暫存器,例外中斷處理程式必須保存和恢復這些暫存器) -
管理模式(SVC)
管理模式是CPU上電后默認模式,因此,在該模式下主要用來做系統的初始化,軟中斷處理也在該模式下,當用戶模式下的用戶程式請求使用硬體資源時,通過軟體中斷進入該模式,說明:系統復位或開機、軟中斷時進入到SVC模式下,
-
終止模式(ABT):
中止模式用于支持虛擬記憶體或存盤器保護,當用戶程式訪問非法地址,沒有權限讀取的記憶體地址時,會進入該模式,linux下編程時經常出現的segment fault通常都是在該模式下拋出回傳的, -
未定義模式(UND):
未定義模式用于支持硬體協處理器的軟體仿真,CPU在指令的譯碼階段不能識別該指令操作時,會進入未定義模式,
- 除了用戶模式外,其它6種模式稱為特權模式,所謂特權模式,即具有如下權利:
a. MRS(把狀態暫存器的內容放到通用暫存器);
b. MSR(把通用暫存器的內容放到狀態暫存器中),
由于狀態暫存器中的內容不能夠改變,因此,要先把內容復制到通用暫存器中,然后修改通用暫存器中的內容,再把通用暫存器中的內容復制給狀態暫存器中,即可完成“修改狀態暫存器”的任務,
- 剩下的六種模式中除去系統模式外,統稱為例外模式,
Arm有多少32位暫存器?
ARM處理器共有37個暫存器,它包含31個通用暫存器和6個狀態暫存器,
Arm2440和6410有什么區別?
-
主頻不同,2440是400M的,6410是533/667M的;
-
處理器版本不一樣:2440是arm920T內核,6410是arm1176ZJF內核;
-
6410在視頻處理方面比2440要強很多,內部視頻解碼器,包括MPEG4等視頻格式;
-
6410支持WMV9、xvid、mpeg4、h264等格式的硬解碼和編碼;
-
6410多和很多擴展介面比如:tv-out、CF卡和S-Video輸出等;
-
spi、串口、sd介面也比那兩個要豐富;
-
6410采用的是DDR記憶體控制器;2440采用的是SDRam記憶體控制器;
-
6410為雙總線架構,一路用于記憶體總線、一路用于Flash總線;
-
6410的啟動方式更加靈活:主要包括SD、Nand Flash、Nor Flash和OneFlash等設備啟動;
-
6410的Nand Flash支持SLC和MLC兩種架構,從而大大擴大存盤空間;
-
6410為雙總線架構,一路用于記憶體總線、一路用于Flash總線;
-
6410具備8路DMA通道,包括LCD、UART、Camera等專用DMA通道;
-
6410還支持2D和3D的圖形加速;
ARM指令集分為幾類?
2類,分別為Thumb指令集,ARM指令集,ARM指令長度為32位,Thumb指令長度為16位,這種特點使得ARM既能執行16位指令,又能執行32位指令,從而增強了ARM內核的功能,
通用暫存器包括R0~R15,可以分為具體哪三類?
通用暫存器包括R0-R15,可以分為3類:
-
未分組暫存器R0-R7
在所有運行模式下,未分組暫存器都指向同一個物理暫存器,他們未被系統用作特殊的用途,因此在中斷或例外處理進行例外模式轉換時,由于不同的處理器運行模式均使用相同的物理暫存器,所以可能造成暫存器中資料的破壞,
-
分組暫存器R8-R14
對于分組暫存器,他們每次所訪問的物理暫存器都與當前的處理器運行模式相關,
R13常用作存放堆疊指標,用戶也可以使用其他暫存器存放堆疊指標,但在Thumb指令集下,某些指令強制要求使用R13存放堆疊指標,
R14稱為鏈接暫存器(LR,Link Register),當執行子程式時,R14可得到R15(PC)的備份,執行完子程式后,又將R14的值復制回PC,即使用R14保存回傳地址,
-
程式計數器PC(R15)
暫存器R15用作程式計數器(PC),在ARM狀態下,位[1:0]為0,位[31:2]用于保存PC;在Thumb狀態下,位[0]為0,位[31:1]用于保存PC,
Arm處理器有幾種作業狀態?
從編程的角度來看,ARM微處理器的作業狀態一般ARM和Thumb有兩種,并可在兩種狀態之間切換,
-
ARM狀態:此時處理器執行32位的字對齊ARM指令,絕大部分作業在此狀態,
-
Thumb狀態:此時處理器執行16位的半字對齊的Thumb指令,
ARM系統中,在函式呼叫的時候,引數是通過哪種方式傳遞的?
當引數小于等于4的時候是通過r0-r3暫存器來進行傳遞的,當引數大于4的時候是通過壓堆疊的方式進行傳遞,
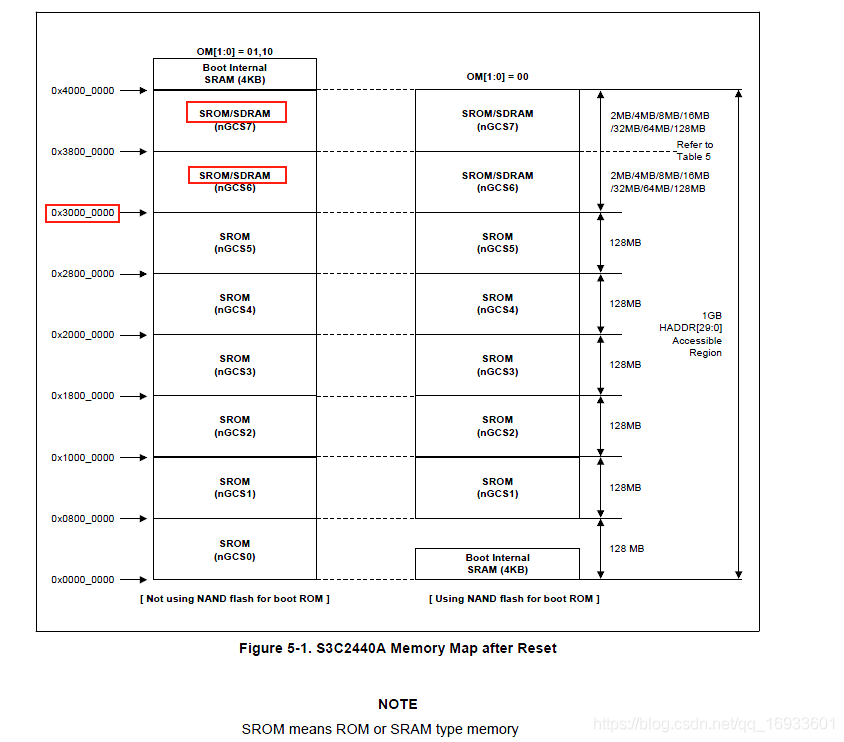
為什么2440的記憶體起始地址是0x30000000?
S3C2440處理器有八個固定的記憶體塊,只有兩個是可以作為ROM,SRAM和SDRAM等存盤器bank,具體如下圖所示,
ARM協處理器指令包括哪3類,請描述它們的功能,
ARM協處理器指令包括以下3類:
-
用于ARM處理器初始化ARM協處理器的資料處理操作,
-
用于ARM處理器的暫存器和ARM協處理器的暫存器間的資料傳送操作,
-
用于在ARM協處理器的暫存器和記憶體單元之間傳送資料,
什么是PLL(鎖相環)?
簡單來說,輸入時鐘的存在是作為“參考源”,鎖相環不是為了單純產生同頻同相信號,而是一般集成進某種“頻率綜合電路”,產生一個不同頻,但鎖相的信號,
有點繞,打個比方:某參考晶振10Mhz,頻率綜合器A使用該參考源產生了900Mhz時鐘,而頻率綜合器B產生了1Ghz時鐘,雖然兩路頻率不同,但由于使用的通一個參考源,他們倆仍然是同源信號,相反,如果不同源,那么即便同頻他們也不可能一致,因為世界上沒有兩個鐘能做到完全一樣,總有微弱的頻差,導致相位飄移,在很多現實應用中有要求同源時鐘的場合,所以,鎖相環被廣泛應用,鎖相環的另外一項衍生應用是相干解調,可以自己查查相關資料,
中斷與例外
中斷與例外有何區別?
中斷是指外部硬體產生的一個電信號從CPU的中斷引腳進入,打斷CPU的運行,
例外是指軟體運行程序中發生了一些必須作出處理的事件,CPU自動產生一個陷入來打斷CPU的運行,例外在處理的時候必須考慮與處理器的時鐘同步,實際上例外也稱為同步中斷,在處理器執行到因編譯錯誤而導致的錯誤指令時,或者在執行期間出現特殊錯誤,必須靠內核處理的時候,處理器就會產生一個例外,
中斷與DMA有何區別?
DMA:是一種無須CPU的參與,就可以讓外設與系統記憶體之間進行雙向資料傳輸的硬體機制,使用DMA可以使系統CPU從實際的I/O資料傳輸程序中擺脫出來,從而大大提高系統的吞吐率,
中斷:是指CPU在執行程式的程序中,出現了某些突發事件時,CPU必須暫停執行當前的程式,轉去處理突發事件,處理完畢后CPU又回傳源程式被中斷的位置并繼續執行,
所以中斷和DMA的區別就是:DMA不需CPU參與,而中斷是需要CPU參與的,
中斷能不能睡眠,為什么?下半部能不能睡眠?
-
中斷處理的時候,不應該發生行程切換,因為在中斷背景關系中,唯一能打斷當前中斷handler的只有更高優先級的中斷,它不會被行程打斷,如果在中斷背景關系中休眠,則沒有辦法喚醒它,因為所有的wake_up_xxx都是針對某個行程而言的,而在中斷背景關系中,沒有行程的概念,沒有一個task_struct(這點對于softirq和tasklet一樣),因此真的休眠了,比如呼叫了會導致阻塞的例程,內核幾乎肯定會死,
-
schedule()在切換行程時,保存當前的行程背景關系(CPU暫存器的值、行程的狀態以及堆疊中的內容),以便以后恢復此行程運行,中斷發生后,內核會先保存當前被中斷的行程背景關系(在呼叫中斷處理程式后恢復),
但在中斷處理程式里,CPU暫存器的值肯定已經變化了(最重要的程式計數器PC、堆疊SP等),如果此時因為睡眠或阻塞操作呼叫了schedule(),則保存的行程背景關系就不是當前的行程背景關系了,所以,不可以在中斷處理程式中呼叫schedule(),
-
2.4內核中schedule()函式本身在進來的時候判斷是否處于中斷背景關系:
if(unlikely(in_interrupt()))
BUG();
?因此,強行呼叫schedule()的結果就是內核BUG,但看2.6.18的內核schedule()的實作卻沒有這句,改掉了,
-
中斷handler會使用被中斷的行程內核堆疊,但不會對它有任何影響,因為handler使用完后會完全清除它使用的那部分堆疊,恢復被中斷前的原貌,
-
處于中斷背景關系時候,內核是不可搶占的,因此,如果休眠,則內核一定掛起,
中斷的回應執行流程是什么?
中斷的回應流程:cpu接受中斷->保存中斷背景關系跳轉到中斷處理歷程->執行中斷上半部->執行中斷下半部->恢復中斷背景關系,
當一個例外出現以后,ARM微處理器會執行哪幾步操作?
- 將下一條指令的地址存入相應連接暫存器LR,以便程式在處理例外回傳時能從正確的位置重新開始執行,若例外是從ARM狀態進入,則LR暫存器中保存的是下一條指令的地址(當前PC+4或PC+8,與例外的型別有關);若例外是從Thumb狀態進入,則在LR暫存器中保存當前PC的偏移量,這樣,例外處理程式就不需要確定例外是從何種狀態進入的,例如:在軟體中斷例外SWI,指令 MOV PC,R14_svc總是回傳到下一條指令,不管SWI是在ARM狀態執行,還是在Thumb狀態執行,
- 將CPSR復制到相應的SPSR中,
- 根據例外型別,強制設定CPSR的運行模式位,
- 強制PC從相關的例外向量地址取下一條指令執行,從而跳轉到相應的例外處理程式處,
寫一個中斷服務需要注意哪些?如果中斷產生之后要做比較多的事情你是怎么做的?
-
寫一個中斷服務程式要注意快進快出,在中斷服務程式里面盡量快速采集資訊,包括硬體資訊,然后退出中斷,要做其它事情可以使用作業佇列或者tasklet方式,也就是中斷上半部和下半部,
-
中斷服務程式中不能有阻塞操作,應為中斷期間是完全占用CPU的(即不存在內核調度),中斷被阻塞住,其他行程將無法操作,
-
中斷服務程式注意回傳值,要用作業系統定義的宏做為回傳值,而不是自己定義的,
-
如果要做的事情較多,應將這些任務放在后半段(tasklet,等待佇列等)處理,
為什么FIQ比IRQ要快?
-
ARM的FIQ模式提供了更多的banked暫存器,r8到r14還有SPSR,而IRQ模式就沒有那么多,R8,R9,R10,R11,R12對應的banked的暫存器就沒有,這就意味著在ARM的IRQ模式下,中斷處理程式自己要保存R8到R12這幾個暫存器,然后退出中斷處理時程式要恢復這幾個暫存器,而FIQ模式由于這幾個暫存器都有banked暫存器,模式切換時CPU自動保存這些值到banked暫存器,退出FIQ模式時自動恢復,所以這個程序FIQ比IRQ快.不要小看這幾個暫存器,ARM在編譯的時候,如果你FIQ中斷處理程式足夠用這幾個獨立的暫存器來運作,它就不會進行通用暫存器的壓堆疊,這樣也省了一些時間,
-
FIQ比IRQ有更高優先級,如果FIQ和IRQ同時產生,那么FIQ先處理,
-
在symbian系統里,當CPU處于FIQ模式處理FIQ中斷的程序中,預取指令例外,未定義指令例外,軟體中斷全被禁止,所有的中斷被屏蔽,所以FIQ就會很快執行,不會被其他例外或者中斷打斷,所以它又比IRQ快了,而IRQ不一樣,當ARM處理IRQ模式處理IRQ中斷時,如果來了一個FIQ中斷請求,那正在執行的IRQ中斷處理程式會被搶斷,ARM切換到FIQ模式去執行這個FIQ,所以FIQ比IRQ快多了,
-
另外FIQ的入口地址是0x1c,IRQ的入口地址是0x18,寫過完整匯編系統的都比較明白這點的差別,18只能放一條指令,為了不與1C處的FIQ沖突,這個地方只能跳轉,而FIQ不一樣,1C以后沒有任何中斷向量表了,這樣可以直接在1C處放FIQ的中斷處理程式,由于跳轉的范圍限制,至少少了一條跳轉指令,
中斷和輪詢哪個效率高?怎樣決定是采用中斷方式還是采用輪詢方式去實作驅動?
中斷是CPU處于被動狀態下來接受設備的信號,而輪詢是CPU主動去查詢該設備是否有請求,
凡事都是兩面性,所以,看效率不能簡單的說那個效率高,如果是請求設備是一個頻繁請求cpu的設備,或者有大量資料請求的網路設備,那么輪詢的效率是比中斷高,如果是一般設備,并且該設備請求cpu的頻率比較低,則用中斷效率要高一些,主要是看請求頻率,
通信協議
什么是異步傳輸和同步傳輸?
異步傳輸:是一種典型的基于位元組的輸入輸出,資料按每次一個位元組進行傳輸,其傳輸速度低,
同步傳輸:需要外界的時鐘信號進行通信,是把資料位元組組合起來一起發送,這種組合稱之為幀,其傳輸速度比異步傳輸快,
RS232和RS485通訊介面有什么區別?
-
傳輸方式不同, RS232采取不平衡傳輸方式,即所謂單端通訊, 而RS485則采用平衡傳輸,即差分傳輸方式,
-
傳輸距離不同,RS232適合本地設備之間的通信,傳輸距離一般不超過20m,而RS485的傳輸距離為幾十米到上千米,
-
設備數量,RS232 只允許一對一通信,而RS485 介面在總線上是允許連接多達128個收發器,
-
連接方式,RS232,規定用電平表示資料,因此線路就是單線路的,用兩根線才能達到全雙工的目的;而RS485, 使用差分電平表示資料,因此,必須用兩根線才能達到傳輸資料的基本要求,要實作全雙工,必需用4根線,
?總結:從某種意義上,可以說,線路上存在的僅僅是電流,RS232/RS485規定了這些電流在什么樣的線路上流動和流動的樣式,
SPI協議
SPI的應用
SPI(Serial Peripheral Interface)協議是由摩托羅拉公司提出的通訊協議,即串行外圍設備介面,是一種高速全雙工的通信總線,SPI總線系統是一種同步串行外設介面,它可以使MCU與各種外圍設備以串行方式進行通信以交換資訊,SPI總線可直接與各個廠家生產的多種標準外圍器件相連,包括FLASH、RAM、網路控制器、LCD顯示驅動器、A/D轉換器和MCU等,
介面
-
MOSI (Master Output, Slave Input)
主設備輸出/從設備輸入引腳,主機的資料從這條信號線輸出,從機由這條信號線讀入主機發送的資料,即這條線上資料的方向為主機到從機,
-
MISO(Master Input,, Slave Output)
主設備輸入/從設備輸出引腳,主機從這條信號線讀入資料,從機的資料由這條信號線輸出到主機,即在這條線上資料的方向為從機到主機,
-
SCLK (Serial Clock)
時鐘信號線,用于通訊資料同步,它由通訊主機產生,決定了通訊的速率,不同的設備支持的最高時鐘頻率不一樣,如 STM32 的 SPI 時鐘頻率最大為fpclk/2,兩個設備之間通訊時,通訊速率受限于低速設備,
-
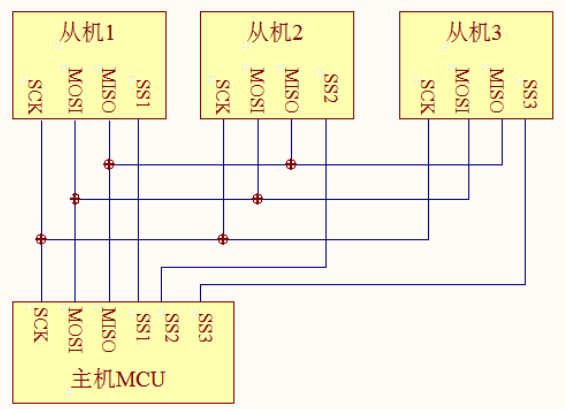
SS( Slave Select)
從設備選擇信號線,常稱為片選信號線,也稱為 NSS、 CS,以下用 NSS 表示, 當有多個 SPI 從設備與 SPI 主機相連時,設備的其它信號線 SCK、MOSI 及 MISO 同時并聯到相同的 SPI 總線上,即無論有多少個從設備,都共同只使用這 3 條總線;而每個從設備都有獨立的這一條 NSS 信號線,本信號線獨占主機的一個引腳,即有多少個從設備,就有多少條片選信號線,
I2C 協議中通過設備地址來尋址、選中總線上的某個設備并與其進行通訊;而 SPI 協議中沒有設備地址,它使用 NSS 信號線來尋址,當主機要選擇從設備時,把該從設備的 NSS 信號線設定為低電平,該從設備即被選中,即片選有效,接著主機開始與被選中的從設備進行 SPI 通訊,所以SPI 通訊以 NSS 線置低電平為開始信號,以 NSS 線被拉高作為結束信號,
協議層
SPI 通訊設備之間的常用連接方式見下圖:
SPI 通訊的通訊時序,見下圖:
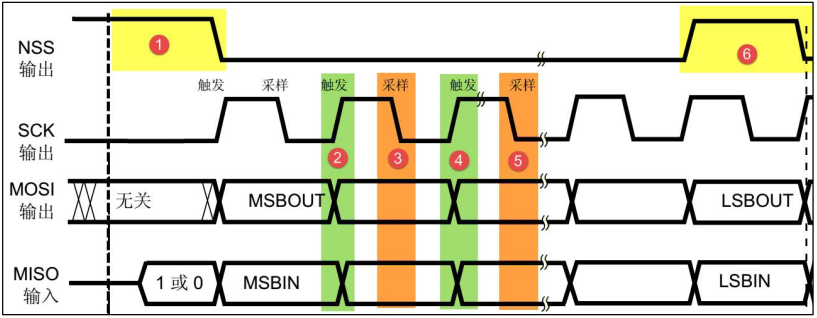
-
通訊的起始和停止信號
在圖中的標號1處,NSS 信號線由高變低,是 SPI 通訊的起始信號, NSS 是每個從機各自獨占的信號線,當從機檢在自己的 NSS 線檢測到起始信號后,就知道自己被主機選中了,開始準備與主機通訊,在圖中的標號?處, NSS 信號由低變高,是 SPI 通訊的停止信號,表示本次通訊結束,從機的選中狀態被取消,
-
資料有效性
SPI 使用 MOSI 及 MISO 信號線來傳輸資料,使用 SCK 信號線進行資料同步, MOSI及 MISO 資料線在 SCK 的每個時鐘周期傳輸一位資料,且資料輸入輸出是同時進行的,資料傳輸時, MSB 先行(高位先行)或 LSB(低位先行)先行并沒有作硬性規定,但要保證兩個 SPI 通訊設備之間使用同樣的協定,一般都會采用上圖中的 MSB 先行(高位先行)模式,
觀察圖中的2345標號處, MOSI 及 MISO 的資料在 SCK 的上升沿期間變化輸出,在 SCK 的下降沿時被采樣,即在 SCK 的下降沿時刻, MOSI 及 MISO 的資料有效,高電平時表示資料“1”,為低電平時表示資料“0”,在其它時刻,資料無效, MOSI 及 MISO為下一次表示資料做準備,
SPI 每次資料傳輸可以 8 位或 16 位為單位,每次傳輸的單位數不受限制,
-
CPOL(時鐘極性)/CPHA(時鐘相位)及通訊模式
上面講述的圖中的時序只是 SPI 中的其中一種通訊模式, SPI 一共有四種通訊模式,它們的主要區別是:總線空閑時 SCK 的時鐘狀態以及資料采樣時刻,為方便說明,在此引入“時鐘極性CPOL”和“時鐘相位 CPHA”的概念,
時鐘極性 CPOL 是指 SPI 通訊設備處于空閑狀態時, SCK 信號線的電平信號(即 SPI 通訊開始前、 NSS 線為高電平時 SCK 的狀態), CPOL=0 時, SCK 在空閑狀態時為低電平,CPOL=1 時,則相反,
時鐘相位 CPHA 是指資料的采樣的時刻,當 CPHA=0 時, MOSI 或 MISO 資料線上的信號將會在 SCK 時鐘線的“奇數邊沿” 被采樣,當 CPHA=1 時,資料線在 SCK 的“偶數邊沿” 采樣,
IIC協議
簡介
IIC協議是由資料線SDA和時鐘SCL構成的串行總線,可發送和接收資料,是一個多主機的半雙工通信方式
每個掛接在總線上的器件都有個唯一的地址,位速在標準模式下可達 100kbit/s,在快速模式下可達400kbit/s,在高速模式下可待3.4Mbit/s,
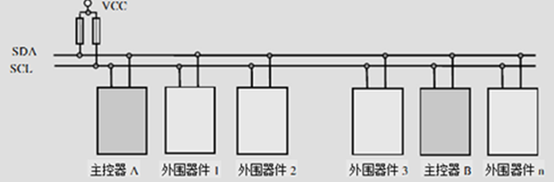
I2C總線系統結構,如下所示:
I2C時序介紹
1. 空閑狀態
當總線上的SDA和SCL兩條信號線同時處于高電平,便是空閑狀態,如上面的硬體圖所示,當我們不傳輸資料時, SDA和SCL被上拉電阻拉高,即進入空閑狀態
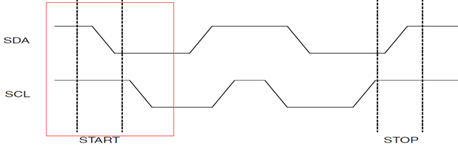
2. 起始信號
當SCL為高期間,SDA由高到低的跳變;便是總線的啟動信號,只能由主機發起,且在空閑狀態下才能啟動該信號,如下圖所示:
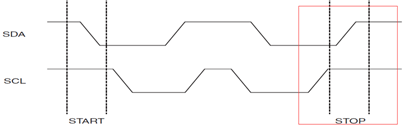
3. 停止信號
當SCL為高期間,SDA由低到高的跳變;便是總線的**停止信號,**表示資料已傳輸完成,如下圖所示:
4. 傳輸資料格式
當發了起始信號后,就開始傳輸資料,傳輸的資料格式如下圖所示:
當SCL為高電平時,便會獲取SDA資料值,其中SDA資料必須是穩定的(若SDA不穩定就會變成起始/停止信號),
當SCL為低電平時,便是SDA的電平變化狀態,
若主從機在傳輸資料期間,需要完成其它功能(例如一個中斷),可以主動拉低SCL,使I2C進入等待狀態,直到處理結束再釋放SCL,資料傳輸會繼續
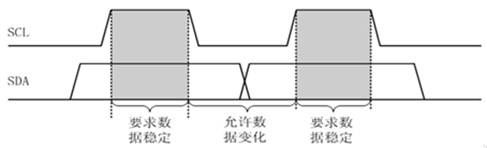
5. 應答信號ACK
I2C總線上的資料都是以8位資料(位元組)進行的,當發送了8個資料后,發送方會在第9個時鐘脈沖期間釋放SDA資料,當接收方接收該位元組成功,便會輸出一個ACK應答信號,當SDA為高電平,表示為非應答信號NACK,當SDA為低電平,表示為有效應答信號ACK
PS:當主機為接收方時,收到最后一個位元組后,主機可以不發送ACK,直接發送停止信號來結束傳輸,
當從機為接收方時,沒有發送ACK,則表示從機可能在忙其它事、或者不匹配地址信號和不支持多主機發送,主機可以發送停止信號,再次發送起始信號啟動新的傳輸,
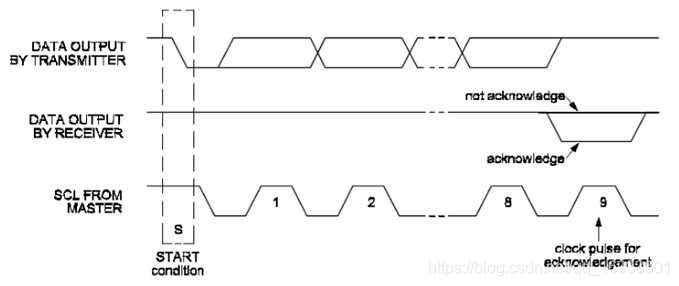
6. 完整的資料傳輸
如下圖所示, 發送起始信號后,便發送一個8位的設備地址,其中第8位是對設備的讀寫標志,后面緊跟著的就是資料了,直到發送停止信號終止,
PS:當我們第一次是讀操作,然后想換成寫操作時,可以再次發送一個起始信號,然后發送讀的設備地址,不需要停止信號便能實作不同的地址轉換,
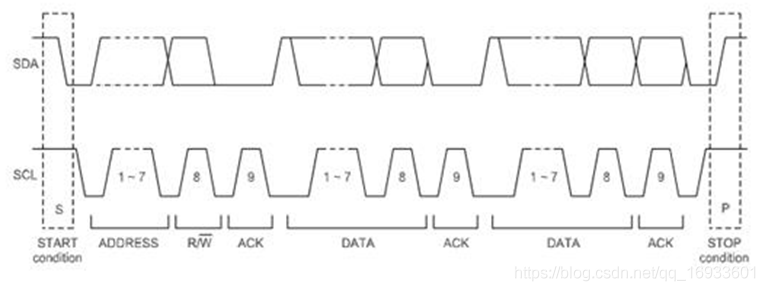
IIC傳輸資料的格式
1.寫操作
剛開始主芯片要發出一個start信號,然后發出一個(用來確定是往哪一個芯片寫資料),方向(讀/寫,0表示寫,1表示讀),回應(用來確定這個設備是否存在),然后就可以傳輸資料,傳輸資料之后,要有一個回應信號(確定資料是否接受完成),然后再傳輸下一個資料,每傳輸一個資料,接受方都會有一個回應信號,資料發送完之后,主芯片就會發送一個停止信號,
白色背景:主→從,灰色背景:從→主,

2.讀操作
剛開始主芯片要發出一個start信號,然后發出一個設備地址(用來確定是從哪一個芯片讀取資料),方向(讀/寫,0表示寫,1表示讀),回應(用來確定這個設備是否存在),然后就可以傳輸資料,傳輸資料之后,要有一個回應信號(確定資料是否接受完成),然后在傳輸下一個資料,每傳輸一個資料,接受方都會有一個回應信號,資料發送完之后,主芯片就會發送一個停止信號,
白色背景:主→從,灰色背景:從→主

編程
嵌人式編程中,什么是大端?什么是小端?
大端模式:低位位元組存在高地址上,高位位元組存在低地址上,
小端模式:高位位元組存在高地址上,低位位元組存在低地址上,
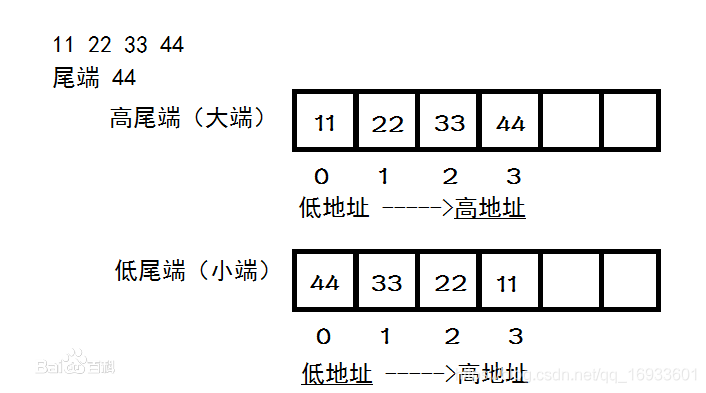
STM32屬于小端模式,簡單的說,比如u32 temp=0X12345678;假設temp地址在0X2000 0010,那么在記憶體里面,存放就變成了:
地址 | HEX |
0X2000 0010 | 78 56 43 12 |
因為是16進制的,一個數為0.5位元組,所以 12 代表一個位元組 34 代表一個位元組,
釆用小端模式的CPU對運算元的存放方式是從低位元組到高位元組,而大端模式對運算元的存放方式是從高位元組到低位元組,例如,16位寬的數0x1234在小端模式CPU記憶體中的存放方式(假設從地址0x4000開始存放)見表1,而在大端模式CPU記憶體中的存放方式見表2,
??????????????????????表1?0x1234在小端CPU記憶體中的存放方式
| 記憶體地址 | 存放內容 |
|---|---|
| 0x4000 | 0x34 |
| 0x4001 | 0x12 |
??????????????????????表2?0x1234在大端CPU記憶體中的存放方式
| 記憶體地址 | 存放內容 |
|---|---|
| 0x4000 | 0x12 |
| 0x4001 | 0x34 |
??32位寬的數0x12345678在小端模式CPU記憶體中的存放方式(假設從地址0x4000開始存放)見表3,而在大端模式CPU記憶體中的存放方式見表4,
??????????????????????表3?0x12345678在小端CPU記憶體中的存放方式
| 記憶體地址 | 存放內容 |
|---|---|
| 0x4000 | 0x78 |
| 0x4001 | 0x56 |
| 0x4002 | 0x34 |
| 0x4003 | 0x12 |
??????????????????????表4?0x12345678在大端CPU記憶體中的存放方式
| 記憶體地址 | 存放內容 |
|---|---|
| 0x4000 | 0x12 |
| 0x4001 | 0x34 |
| 0x4002 | 0x56 |
| 0x4003 | 0x78 |
以下程式為例:
#include <stdio.h>
struct mybitfields
{
unsigned short a:4;
unsigned short b:5;
unsigned short c:7;
}test;
int main()
{
int i;
test.a = 2;
test.b = 3;
test.c = 0;
i =*((short*)&test);
printf("%d\n",i);
return 0;
}
程式的輸出結果為 50,
上例中, sizeof( test)=2,上例的宣告方式是把一個 short(也就是一塊16位記憶體)分成3部分,各部分的大小分別是4位、5位、7位,賦值陳述句i*( short*)&test)就是把上面的16位記憶體轉換成 short型別進行解釋,
變數a的二進制表示為0000000000000010,取其低四位是0010.變數b的二進制表示為0000000000000011,取其低五位是00011,變數c的二進制表示為0000000000000000,取其低七位是0000000,
80x86機是小端(修改磁區表時要注意)模式,單片機一般為大端模式,小端一般是低位位元組在高位位元組的前面,也就是低位在記憶體地址低的一端,可以這樣記(小端→低位→在前→與正常邏輯順序相反),所以合成后得到0000000000110010,即十進制的50,
下面給出另外一個例子
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main()
{
unsigned int uiVal_1 = 0x12345678;
unsigned int uiVal_2 = 0;
unsigned char aucVal[4] = {0x12,0x34,0x56,0x78};
unsigned short usVal_1 = 0;
unsigned short usVal_2 = 0;
memcpy(&uiVal_2,aucVal,sizeof(uiVal_2));
usVal_1 = (unsigned short)uiVal_1;//在這里截斷,都取得的是低位
usVal_2 = (unsigned short)uiVal_2;//在這里截斷
printf("usVal_1:%x\n",usVal_1);//在這里又轉化回來
printf("usVal_2:%x\n",usVal_2);//在這里又轉化回來
return 0;
}
??小端模式是低地址存放低位元組,高地址存放高位元組,結構如下所示
78//低地址
56
34
12//高地址
??在記憶體里面測驗機是小端,地址由小到大,
val1:78563412
riVal2:12345678
??結果如下:
5678
3412
如何判斷計算機處理器是大端,還是小端?
#include <stdio.h>
int checkCPU()
{
{
union w
{
int a;
char b;
}c;
c.a =1;
return(c.b == 1);
}
}
int main()
{
if(checkCPU())
printf("小端\n");
else
printf("大端\n");
return 0;
}
編者的處理器為ntel處理器,因為 Intel處理器一般都是小端模式,所以此時程式的輸出結果為:小端
上述代碼中,如果處理器是大端,則回傳0;如果處理器是小端,則回傳1.聯合體 union的存放順序是所有成員都從低地址開始存放,如果能夠通過改代碼知道CPU對記憶體是采用小端模式讀寫,還是采用大端模式讀寫,一定會令面試官刮目相看,
還可以通過指標地址來判斷,由于在32位計算機系統中, short占兩個位元組,char占1個位元組,所以可以采用如下做法實作該判斷,
#include <stdio.h>
int checkCPU()
{
unsigned short usData = 0x1122;
unsigned char*pucData = (unsigned char*)&usData;
return (*pucData == 0x22);
}
int main()
{
if(checkCPU())
printf("小端\n");
else
printf("大端\n");
return 0;
}
程式輸出的結果為:小端
如何進行大小端的轉換?
int swapInt32(int intValue){
int temp = 0;
temp = ((intValue & 0x000000FF) <<24)|
((intValue & 0x0000FF00) <<8) |
((intValue & 0x00FF0000) >>8) |
((intValue & 0xFF000000) >>24);
return temp;
}
/*short型:*/
unsigned short swapShort16(unsigned short shortValue){
return ((shortValue & 0x00FF ) <<8) | ((shortValue & 0xFF00)>>8);
}
/*float型:*/
float swapFloat32(float floatValue){
typedef union SWAP_UNION{
float unionFloat;
int unionInt;
}SWAP_UNION;
SWAP_UNION swapUnion;
swapUnion.unionFloat = floatValue;
swapUnion.unionInt = swapInt32( swapUnion.unionInt);
return swapUnion.unionFloat;
}
/*double型換一種寫法,用一下指標,不然移位移死了……*/
void swapDouble64(unsigned char *pIn, unsigned char *pOut){
for( int i=0;i<8;i++)
pOut[7-i] = pIn[i];
}
int main()
{
int x = 0x12345678;
int y = swapInt32(x);
printf("%x\r\n",y);
return 0;
}
如何對絕對地址0x100000賦值?
*(unsigned int*)0x100000 = 1234;
那么要是想讓程式跳轉到絕對地址是0x100000去執行,應該怎么做?
*((void (*)( ))0x100000 ) ( );
首先要將0x100000強制轉換成函式指標,即:
(void (*)())0x100000
然后再呼叫它:
*((void (*)())0x100000)();·
用typedef可以看得更直觀些:
typedef void(*)() voidFuncPtr;
*((voidFuncPtr)0x100000)();
聯系作者
關于作者
作者在準備秋招的程序中,憑借這份資料,最后順利拿到了oppo,小米,兆易創新,全志科技,海康威視等十余家家公司的offer,現將這部分資料分享出來,希望能對大家有幫助!
如果大家在網上看到了不錯的資料,或者在筆試面試中遇到了資料中沒有的知識點,大家可以關注我的公眾號聯系我,我替大家整理,
資料如有錯誤或者不合適的地方,可以在github向我提交issues,由于精力有限,所以只會用心維護好github和公眾號兩個平臺,資料中的勘誤也會同步更新在github中,
github倉庫
這份資料總共有七個部分,分別為:C/C++,資料結構與演算法分析,Arm體系與架構,Linux驅動開發,作業系統,網路編程,名企筆試真題,所有內容均會同步更新到github倉庫中,PDF版本獲取方式也放在了github中,
點擊跳轉
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/281681.html
標籤:其他
上一篇:設計回圈佇列--C語言