這里寫目錄標題
- 查找的定義
- 陣列和索引
- 二分查找
- 窮舉搜索
- 并行搜索
查找的定義
- 查找:又稱檢索或查詢,是指在查找表中找出滿足一定條件的結點或記錄對應的操作,
- 查找表:在計算機中,是指被查找的資料物件是由同一型別的記錄構成的集合,如順序表, 鏈表、二叉樹和哈希表等
- 查找效率: 查找演算法中的基本運算是通過記錄的關鍵字與給定值進行比較,所以查找的效率 同常取決于比較所花的時間,而時間取決于比較的次數,通常以關鍵字與給定值進行比較的記錄個數的平均值來計算,
查找操作及分類
操作
- 查找某個“特定的”資料元素是否存在在查找表中
- 某個“特定的”資料元素的各種屬性
- 在查找表中插入一個資料元素
- 從查找表中洗掉某個資料元素
分類:
- 若對查找表只進行(1) 或(2)兩種操作,則稱此類查找表為靜態查找表,
- 若在查找程序中同時插入查找表中存在的資料元素,或者從查找表中洗掉已存在的 某個資料元素,則稱此類查找表為動態查找表,
陣列和索引
“電話號碼簿”和“字典”都可 看作一張查找表, 而按“姓”或者“字母”查詢則是按索引查詢!
- 索引把線性表分成若干塊,每一塊中的元素存盤順序是任意的,但是塊與塊間必須按關鍵字大小按順序排列,即前一塊中的最大關鍵字值小于后一塊中的最小關鍵字值,
- 分塊以后,為了快速定義塊,還需要建立一個索引表,索引表中的一項對應于線性表中的一 塊,索引項由鍵域和鏈域組成,鍵域存放相應關鍵字的鍵值,鏈域存放指向本塊第一個節點和最后一個節點的指標,索引表按關鍵字由小到大的順序排列!

哈希表是非常經典的塊索引!
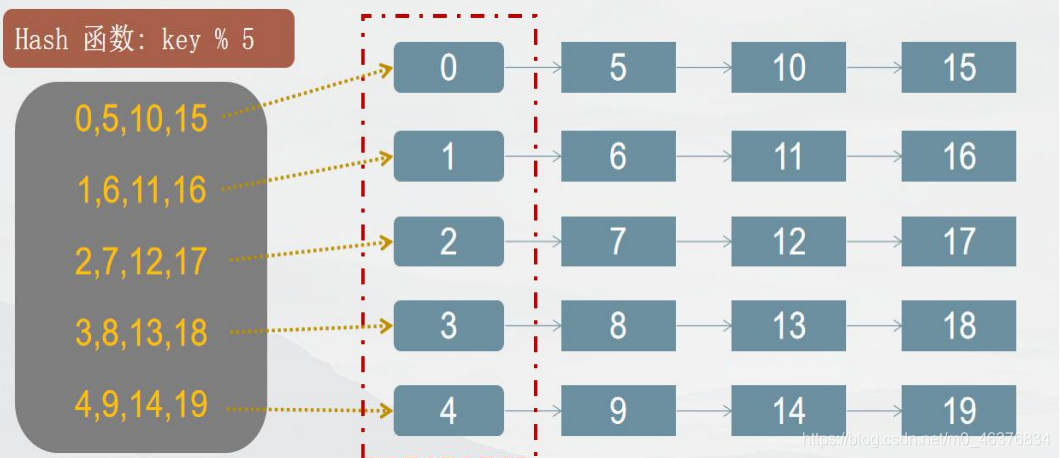
分塊查找的演算法分兩步進行,首先確定所查找的節點屬于哪一塊,即在索引表中查找其所在的塊, 然后在塊內查找待查詢的資料,由于索引表是遞增有序的,可采用二分查找,而塊內元素是無序 的,只能采用順序查找,(塊內元素較少,則不會對執行速度有太大的影響)
二分查找
二分查找法實質上是不斷地將有序資料集進行對半分割,并檢查每個磁區的中間元素,再重 復根據中間數確定目標范圍并遞回實行對半分割,直到中間數等于待查找的值或是目標數不在搜 索范圍之內!
測驗原始碼原始碼:
#include <stdlib.h>
#include <stdio.h>
int int_compare(const void *key1, const void *key2){
const int *ch1 = (const int *)key1;
const int *ch2 = (const int *)key2;
return (*ch1-*ch2);
}
int char_compare(const void *key1, const void *key2){
const char *ch1 = (const char *)key1;
const char *ch2 = (const char *)key2;
return (*ch1-*ch2);
}
int BinarySearch(void *sorted, int len, int elemSize, void *search, int (*compare)(const void *key1, const void *key2))
{
int left = 0, right = 0, middle = 0;
/*初始化 left 和 right 為邊界值*/
left = 0;
right = len - 1;
/* 回圈查找,直到左右兩個邊界重合*/
while(left <= right){
int ret = 0;
middle = (left + right) /2 ;
ret = compare((char *)sorted+(elemSize*middle), search);
if(ret == 0){ /*middle 等于目標值*/
/*回傳目標的索引值 middle*/
return middle;
}else if( ret > 0){
/*middle 大于目標值*/
/*移動到 middle 的左半區查找*/
right = middle - 1;
}else {
/*middle 小于目標值*/
/*移動到 middle 的右半區查找*/
left = middle + 1;
}
}
return -1;
}
int main(void){
int arr[]={1, 3, 7, 9, 11};
int search[] = {-1, 0, 1, 7 , 2, 11, 12};
printf("整數查找測驗開始,,,\n");
for(int i=0; i<sizeof(search)/sizeof(search[0]); i++){
int index = BinarySearch(arr, sizeof(arr)/sizeof(arr[0]), sizeof(int), &search[i], int_compare);
printf("searching %d, index: %d\n",search[i], index);
}
char arr1[]={'a','c','d','f','j'};
char search1[] = {'0', 'a', 'e', 'j' , 'z'};
printf("\n 字符查找測驗開始,,,\n");
for(int i=0; i<sizeof(search1)/sizeof(search1[0]); i++){
int index = BinarySearch(arr1, sizeof(arr1)/sizeof(arr1[0]), sizeof(char), &search1[i], char_compare);
printf("searching %c, index: %d\n",search1[i], index);
}
system("pause");
return 0;
}
窮舉搜索
- 窮舉法(列舉法)的基本思想是:列舉出所有可能的情況,逐個判斷有哪些是符合問題所要求 的條件,從而得到問題的全部解答,
- 它利用計算機運算速度快、精確度高的特點,對要解決問題的所有可能情況,一個不漏地進行檢 查,從中找出符合要求的答案,
用窮舉演算法解決問題,通常可以從兩個方面進行分析:
- 問題所涉及的情況:問題所涉及的情況有哪些,情況的種數必須可以確定,
- 把它描述 出來,應用窮舉時對問題所涉及的有限種情形必須一一列舉,既不能重復,也不能遺漏,重復列 舉直接引發增解,影響解的準確性;而列舉的遺漏可能導致問題解的遺漏,
- 答案需要滿足的條件:分析出來的這些情況,需要滿足什么條件,才成為問題的答案, 把這些條件描述出來,
并行搜索

并發的基本概念:
- 所謂并發是在同一物體上的多個事件同時發生,并發編程是指在在同一臺計算機上“同時” 處理多個任務,
- 計算機就像一座工廠,時刻在運行,為人類服務,它的核心是 CPU,它承擔了所有的計算任 務,就像工廠的一個現場指揮官,
- 行程就像工廠里的車間,承擔“工廠”里的各項具體的“生產任務”,通常每個行程對應一 個在運行中的執行程式,比如,QQ 和微信運行的時候,他們分別是不同的行程,
- 任一時刻,單個 CPU 一次只能運行一個行程,此時其他行程處于非運行狀態,
- 一個行程可以擁有多個執行緒,每個執行緒可以可以獨立并行執行,多個執行緒共 享同一行程的資源,受行程管理,

假設我們要從很大的一個無序的資料集中進行搜索,假設我們的機器可以一次性容納這么多 資料,從理論上講,對于無序資料,如果不考慮排序,已經很難從演算法層面優化了,而利用 上面我們提到的并行處理思想,我們可以很輕松地將檢索效率提升多倍,
具體實作思路如下: 將資料分成 N 個塊,每個塊由一個 執行緒來并行搜索,
執行緒演示代碼:
#include <Windows.h>
#include <stdio.h>
#include <iostream>
#include <time.h>
#define TEST_SIZE (1024*1024*200)
#define NUMBER 20
DWORD WINAPI ThreadProc(void* lpParam) {
for (int i = 0; i < 5; i++) {
printf("行程,我來了!\n");
Sleep(1000);
}
return 0;
}
int main(void) {
DWORD threadID1;//執行緒 1 的身份證
HANDLE hThread1;//執行緒 1 的句柄
DWORD threadID2;//執行緒 2 的身份證
HANDLE hThread2;//執行緒 2 的句柄
printf("創建執行緒... ... \n");
//創建執行緒 1
hThread1 = CreateThread(NULL, 0, ThreadProc, NULL, 0, &threadID1);
//創建執行緒 2
hThread2 = CreateThread(NULL, 0, ThreadProc, NULL, 0, &threadID2);
WaitForSingleObject(hThread1, INFINITE);
WaitForSingleObject(hThread2, INFINITE);
printf("行程歡迎執行緒歸來!\n");
system("pause");
return 0;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/281682.html
標籤:其他