監控狀態
目錄- 監控狀態
- 兩種狀態
- 服務和主機檢查重試
- SOFT States
- During SOFT state
- HARD States
- 狀態變化分析示例
nagios監控的狀態比較特殊,它包含兩種狀態共通定義,所以單獨拎出來說
兩種狀態
- 服務或主機的狀態(即OK,WARNING,UP,DOWN等)
- 服務或主機所在的狀態型別
狀態型別有兩種:SOFT 和 HARD
這些狀態型別是監視邏輯的關鍵部分,因為它們用于確定何時執行事件處理程式以及何時最初發出通知,
本檔案介紹了SOFT和HARD狀態之間的差異,它們如何發生以及何時發生,
服務和主機檢查重試
為了防止因暫時性問題引起的誤報,Nagios Core允許您定義在服務或主機被視為“實際”問題之前應被(重新)檢查多少次,這由主機和服務定義中的max_check_attempts選項控制,了解主機和服務如何(重新)檢查以確定是否存在實際問題對于了解狀態型別的作業方式非常重要,
SOFT States
Soft states 發生在以下場景:
- 當一個服務或者主機檢測結果是是non-ok non-up state ,并且檢測至今還沒有達到max_check_attempts,這個就叫做SOFT state
- 當一個服務或者主機recovers從一個soft error, 這個就被認為是一個soft 恢復,
以下事情會發生,當主機或者服務經歷了SOFT state變化時:
- the SOFT state is logged
- event handlers are excuted to handle the SOFT state
僅當在主組態檔中啟用了log_service_retries或log_host_retries選項時,才會記錄SOFT狀態,
During SOFT state
當監控狀態處于SOFT狀態這段時間(畢竟有一個max_check_attempts)最最重要的是事情就是,event handlers的執行情況了,使用event handlers可能是特別有用,如果你想去嘗試或者主動去解決一個問題,在這個SOFT狀態變為HARD狀態之前,$HOSTSTATETYPE$ or $SERVICESSTATETYPE$ macros 將會是SOFT值當event handlers被執行時,這個時候就允許你的Event handler腳本知道這個時候應該做正確的action.
HARD States
以下場景將會發生HARD State:
- 相對于SOFT state,當host or serivce已經是non-OK non-UP且檢測次數已經達到max_check_attempts選項值(host or service中定義的),此時就是HARD error state
- 當一個host or service 從hard error state狀態遷移到另一個錯誤狀態時(如,WARNING to CRITICAL)
- 當一個service檢查狀態時non-ok并且它所在的host是DOWN or UNREACHABLE時
- 當一個host or service 從hard error state狀態恢復時,這個也叫做hard恢復,
- 當一個passive host check 接收到,被動host checks會被看做是HARD,除非passive_host_checks_are_soft 選項是開啟的
以下事情會發生,當主機或者服務經歷了HARD state變化時:
- The HARD state is logged.
- Event handlers are executed to handle the HARD state.
- Contacts are notified of the host or service problem or recovery
執行事件處理程式時,$ HOSTSTATETYPE $或$ SERVICESTATETYPE $宏的值將為'HARD',這使您的事件處理程式腳本知道何時應采取糾正措施,有關事件處理程式的更多資訊,請參見此處,
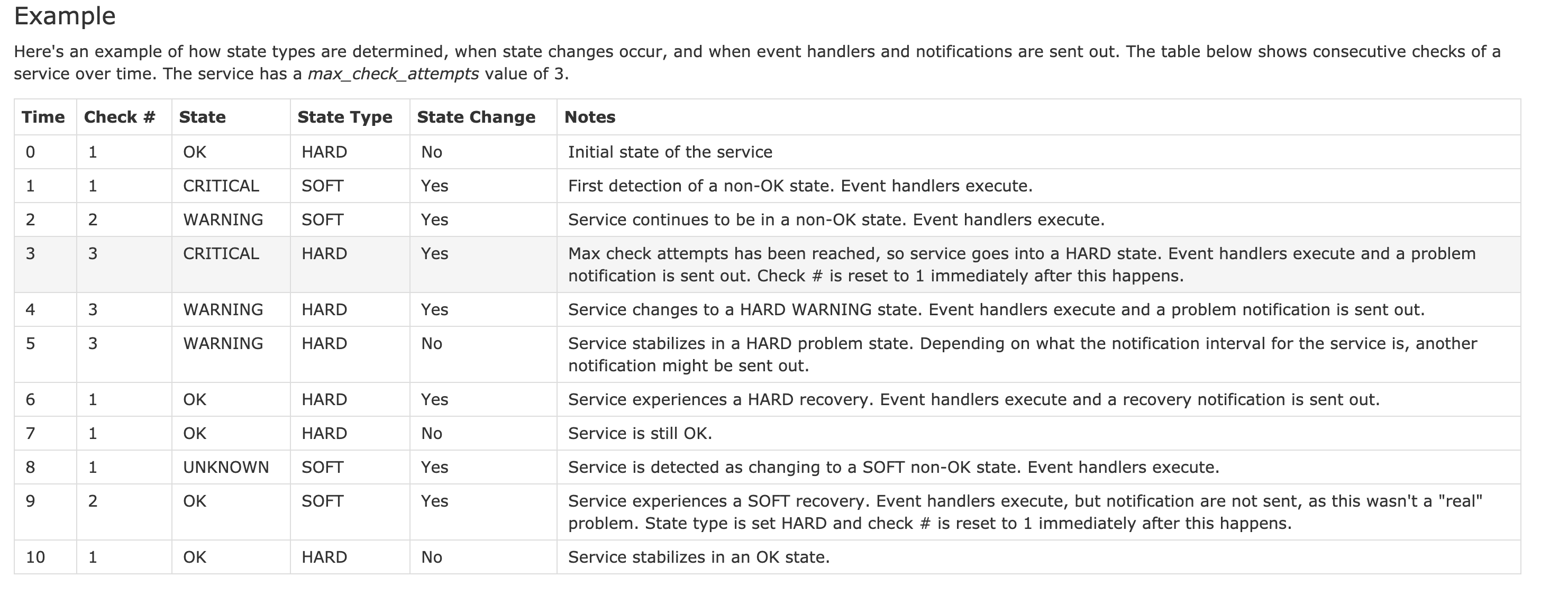
狀態變化分析示例
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/112785.html
標籤:其他