Nagios Host Check
目錄- Nagios Host Check
- 什么時候執行Check
- 快取host checks
- Dependencies and checks
- 主機的并發checks
- 主機的狀態
- 主機狀態變化
- Predictive Host Dependecy Check
- 預測性檢測作業原理
本篇主要講述主機監控的作業原理
什么時候執行Check
Check的調度配置是通過Nagios Core Deamon控制
- 定期性檢測,由主機定義中的check_interval和retry_interval選項
- 按需,當一個與主機關聯的服務狀態發生變化時
- 按需,作為主機可達邏輯的一部分,會進行check觸發
- 按需,作為predictive dependency checks的一部分,會觸發check.
定期性檢查:如果設定check_interval is zero 那么就不會進行定期檢查,
關聯服務觸發的檢查:該檢查被觸發,當一個主機關聯的服務改變了狀態,因為Nagios Core 需要知道是否主機已經在服務狀態改變之前已經改變了狀態,這個很好理解,因為通常一個服務狀態發生了變化,我們很大基礎上會去想知道,承載服務的基礎,host是否狀態已經發生變化,
作為主機可到邏輯的一部分所觸發的主機檢查:Nagios Core被設計用于盡可能快的發現網路斷電,區分Down和Unreachable兩種狀態,這是非常不同的兩種狀態,可以幫助管理員快速定位造成網路斷電的位置,這是一種parent/child關系,我們要保證這種邏輯鏈的健康,比如說網路ip可達,來檢測這種鏈路是健康的,不過一旦不可達了,那么就需要快速定位是鏈路中哪個或者哪些節點出了問題,通常我們會從哪里開始入手呢?這就是從nagios作為網路的根節點,然后依次是nagios通過網路設備達到各個host,當然網路設備也是host,如下圖,可以從nagios為root來構建的一個樹結構:
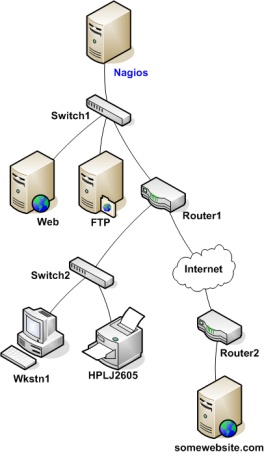
當其中一個或者幾個主機狀態發生變化,那么邏輯可達中的所有主機將進行一個并發的check,當收到每個節點的check結果后,nagios會判定這個節點的check路徑上的上峰節點的check狀態是否有不正常的,如果有,那么該節點狀態為Unreachable而不是down,如果上峰節點都是正常的,那么該節點狀態就是Down,因為上峰不可達后,那么依賴上峰的當前節點狀態是未知的,上峰節點阻塞了檢查,那么就該判定為Unreachable,
當然對于down和unreachable狀態監控還是都會通知到相關contact的,然后admin會根據網路拓撲圖,從nagios角度出發,來發現down的設備,
作為predictive host dependecy check 邏輯的一部分被觸發:
可預測的依賴檢查,單獨放在后面的Predictive Host Dependecy Check講,
快取host checks
通過實作快取檢查的使用,可以顯著提高按需主機檢查的性能,這使Nagios Core可以在確定相對較新的檢查結果的情況下放棄執行主機檢查,有關快取檢查的更多資訊,請參見此處,
也就是說,常規計劃性的檢查結果快取下來,可用于突發的按需檢查,避免了多次價差請求,已提高性能,
Dependencies and checks
您可以定義主機執行依賴性,以防止Nagios Core根據一個或多個其他主機的狀態來發起一個檢查當前主機的狀態,這個屬于高階知識點,有關依賴關系的更多資訊,請參見此處,
主機的并發checks
計劃的主機檢查是并行運行的,當Nagios Core需要運行計劃的主機檢查時,它將啟動主機檢查,然后回傳執行其他作業(運行服務檢查等),主機檢查在從主要Nagios Core守護程式進行fork()處理的子行程中運行,主機檢查完成后,子行程將把檢查結果通知主Nagios Core行程(其父行程),然后,主要的Nagios Core流程將處理檢查結果并采取適當的措施(運行事件處理程式,發送通知等),
如果需要,還可以并行運行按需主機檢查,如前所述,Nagios Core如果可以使用相對較新的主機檢查中的快取結果,則可以放棄按需主機檢查的實際執行,
當Nagios Core處理計劃的和按需的主機檢查結果時,它可能會啟動(輔助)其他主機的檢查,可以出于兩個原因啟動這些檢查:預測依賴性檢查和使用網路可達性邏輯確定主機的狀態,啟動的輔助檢查通常并行運行,但是,您應該意識到一個大例外,因為它可能會對性能產生負面影響...
將max_check_attempts值設定為1的主機可能會導致嚴重的性能問題,原因?如果Nagios Core需要使用網路可達性邏輯來確定其真實狀態(以查看它們是DOWN還是UNREACHABLE),則它將必須啟動對主機的所有直接父級的串行檢查,重申一下,這些檢查是串行運行的,而不是并行運行的,因此可能會嚴重影響性能,因此,我建議您始終在主機定義中為max_check_attempts指令使用大于1的值,
主機的狀態
- UP
- DOWN
- UNREACHABLE
主機狀態變化
如您所知,主機并非總是保持一種狀態, 事情中斷了,補丁被應用了,服務器需要重啟, 當Nagios Core檢查主機狀態時,它將能夠檢測到主機何時在UP,DOWN和UNREACHABLE狀態之間切換,并采取適當的措施, 這些狀態更改導致不同的狀態型別(HARD或SOFT),這可以觸發事件處理程式的運行和通知的發送, 檢測并處理狀態更改是Nagios Core的全部目的,
當主機更改狀態的頻率太高時,它們被視為“拍動”, 主機波動的一個很好的例子是服務器,一旦作業系統加載,該服務器就會自發重啟, 這總是很有趣的情況, Nagios可以檢測主機何時開始震蕩,并且可以抑制通知,直到震蕩停止并且主機的狀態穩定為止, 可以在此處找到有關襟翼檢測邏輯的更多資訊,
Predictive Host Dependecy Check
預測依賴性檢測
主機和服務的依賴可以被定義來允許你更好的控制,什么時候checks被執行和什么時候通知被發送,由于依賴關系用于控制監視程序的基本方面,因此至關重要的是,確保依賴關系邏輯中使用的狀態資訊盡可能最新,
Nagios Core 允許你進行預測性的依賴檢測,針對hosts和service用于去確定依賴邏輯有最新新的狀態資訊,當我們需要這些資訊去確定是否發送通知或允許觸發一次主機或服務檢測,
預測性檢測作業原理
白話說就是,當檢測到一個主機或者服務有問題時,會去預測性的發出它說依賴的依賴服務主機和有直接網路邏輯的父和子的進行一次check,
下圖顯示了Nagios Core監視的主機的基本示意圖,以及它們的父/子關系和依賴關系,
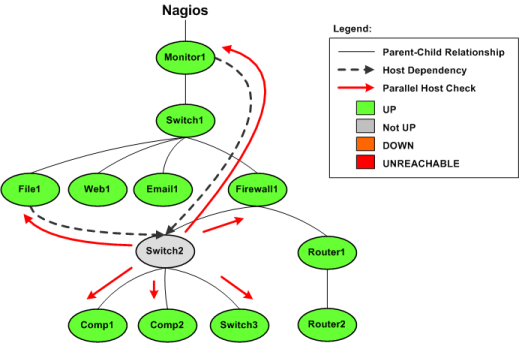
在此示例中,Switch2主機剛剛將狀態從UP狀態更改為問題狀態, Nagios Core需要確定主機是DOWN還是UNREACHABLE,因此它將啟動對Switch2的直接父代(Firewall1)和子代(Comp1,Comp2和Switch3)的并行檢查,這是主機可達性邏輯的正常功能,
您還將注意到,Switch2依賴于Monitor1和File1來進行通知或檢查執行(在此示例中,哪個不重要),如果啟用了預測性主機依賴性檢查,則Nagios Core將同時啟動Monitor1和File1的并行檢查,并啟動Switch2的直系父母和孩子的檢查, Nagios Core之所以這樣做是因為它知道在不久的將來(例如出于通知目的)必須測驗依賴關系邏輯,并且它想確保它具有參與依賴關系的主機的最新狀態資訊,
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/113493.html
標籤:Linux
下一篇:0x06 nagios監控狀態