
- 1. 概述
- 2. 緩沖區的設計
- 2.1 緩沖區頭部
- 2.2 緩沖區的結構
- 2.3 緩沖區的檢索演算法
- 2.3. 申請一個緩沖區演算法 getblk
- 2.3.2 釋放一個緩沖區演算法 brelse
- 2.3.3 讀一個磁盤塊 bread
- 2.3.4 讀一個磁盤并預讀另一個磁盤塊 breada
- 2.3.5 寫餐盤塊 bwrite
- 3. 總結
- Reference
1. 概述
作業系統對檔案系統的一切存取操作,內核都能通過每次直接從磁盤上讀或往磁盤上寫來實作,磁盤和 RAM 的速度之間差別很大,由于兩者速度的不匹配性,在作業系統實際運行的程序中可能會出現以下問題:
- 磁盤機械運動速度大大低于處理的運行速度;
- 多執行緒并發運行,少量的磁盤(通道),I/O 操作將會成為瓶頸所在;
- 資料訪問的隨機性,磁盤忙閑不均,
為了解決上面的問題,Unix 設計者在設計內核時,通過保持一個稱為資料緩沖區高速緩沖( buffer cache)(簡稱高速緩沖)的內部資料緩沖區池來試圖減小對磁盤的存取頻率,具體的解決辦法如下:
-
建立一個成為資料緩沖的高速緩沖的內部資料緩沖區池(buffer pool)來存放使用的資料;
-
寫資料時
把資料盡量長時間的保存在緩沖池中,延遲寫出到磁盤上,以備后續使用,
也就是說在寫資料時,并不是真正的把資料直接寫在磁盤上,而是先寫到緩沖池中,供后續行程使用,盡量少的減少與磁盤互動的頻率,
-
讀資料時
現在緩沖池中查找已有的資料,如果沒有,再從磁盤中讀取,并保存的緩沖池中,使用的時候再從緩沖池取,
從寫資料和讀資料的操作程序中我們可以看出,通過緩沖區的引入,使得行程更多的與緩沖區來進行交換資料,盡量少的減少磁盤的讀寫頻率,提高讀寫速度,
2. 緩沖區的設計
緩沖區池由若干緩沖區組成,每一個緩沖區由兩部分組成:一個含有磁盤上的資料的存盤器陣列及一個用來標識該緩沖區的緩沖頭部(buffer header),其示意圖如下所示:

但是,由于資料緩沖區的首部和存盤區之間有一一對應的關系,所以通常把兩者統稱為緩沖區,
注意:緩沖區是緩沖區池中資料存盤的基本單位,
2.1 緩沖區頭部
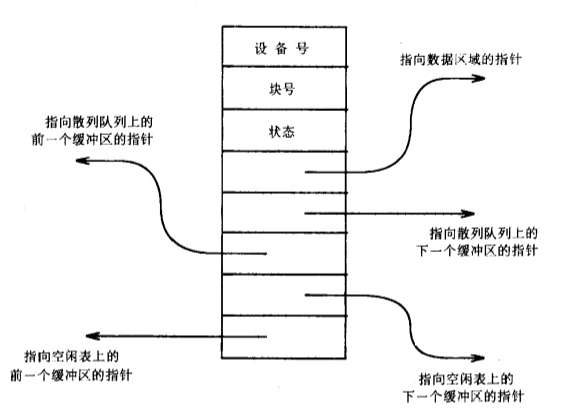
緩沖區的頭部定義如下:
struct buf{
緩沖區標注 //標識緩沖區的的狀態即是否被使用
緩沖區連接指標 //向前向后串成鏈表
空閑緩沖區鏈表指標 //用來鏈接空閑緩沖區
設備號 //用來標識緩沖區
塊號
union{ //緩沖區中的資料型別
資料塊
超級快
柱面塊
i節點塊
}b_un
其他控制資訊
}
為了便于理解我們用一個圖來表示其結構,
2.2 緩沖區的結構
在詳細說明緩沖區的結構之前我們有必要了解一下緩沖區在設計的程序中所遵循的原則:
- 存放有剛使用過的資料盡量長時間地保留在記憶體中,以便馬上還要使用時能在記憶體中找到;
- 需要騰出記憶體空間時,把很久都未使用過(即最近最少使用)的資料交換到磁盤上去,這些資料馬上還要使用的可能性最小,
緩沖區在實作的程序中,其核心維護了一個空閑緩沖區鏈表,它按照最近被使用的先后次序排列,空閑鏈表是一個以空閑緩沖區鏈表頭開始的“雙向回圈鏈表”,鏈表的開始和結束都以鏈表頭為標志,其具體結構如下圖所示:
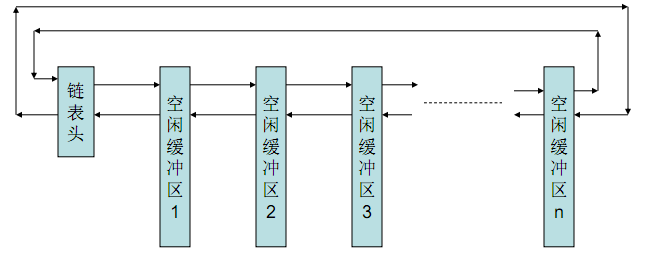
緩沖區操作的具體程序如下:
-
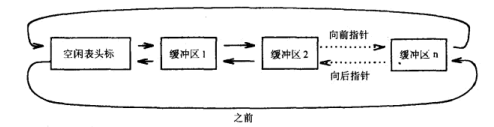
取用任意空閑緩沖區
從空閑緩沖區鏈表的表頭位置取下一個空閑緩沖區,后面的空閑緩沖區依次向前移動,以上圖為例,取空閑緩沖區時,會取走空閑緩沖區 1,然后空閑緩沖區 2-n,會一次向前移動,
-
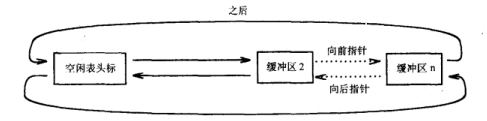
釋放一個空閑緩沖區
把這個裝有資料的空閑緩沖區附加到空閑鏈表的鏈尾,只有當該空閑緩沖區所裝資料出錯時才掛到鏈頭的后邊,
-
取用裝有指定內容的空閑緩沖區
從鏈表頭開始查找,找到后取下使用,用完后放到鏈尾,
當系統不斷從鏈頭取用空閑緩沖區,又把使用過的(裝有資料的)緩沖區掛到鏈尾,一個裝有有效資料的緩沖區就會逐漸向鏈表頭移動,在鏈表頭位置的就是“最近最少使用”的空閑緩沖區,
另一方面,為了提高緩沖區的使用效率,避免在取用緩沖區的時候逐個判斷緩沖區中的內容,緩沖區在設計的時候按照不同的用途將空閑緩沖區分為四類:
- 0#空閑緩沖區鏈表:存放系統檔案超級快
- 1#空閑緩沖區鏈表:存放通常使用的資料塊
- 2#空閑緩沖區鏈表:存放延遲寫、無效資料或者錯誤內容
- 3#空閑緩沖區鏈表:存放沒有對應存盤空間的緩沖區首部
空閑緩沖區按照不同的用途進行分類,這樣有一個最大的好處,程式在使用不同資料的時候只需要按照資料的型別到制定的某個空閑緩沖區鏈表中查找而不需要查找所有的空閑緩沖區鏈表,
另外可能某些讀者會有疑問,我們設計 3#緩沖區鏈表有什么用?按理來說緩沖區和外存的空間應該是一一對應的怎么會出現沒有對應存盤空間的緩沖區這應的情況發生哪?
為了回答這個問題,我們首先要知道,unix 在設計之初,系統的穩定性就是其重要的指標,我們設定這樣一個場景,某臺服務器在運行程序中與某個緩沖區對應的磁盤壞掉了,在這種情況下,為了保證系統的穩定性,我們不可能重啟服務器,重新實作緩沖區和磁盤空間的映射,因此我們設計出 3#空閑緩沖區鏈表,這樣,上邊沒有存盤空間的緩沖區都會被掛載到該空閑緩沖區鏈表中,當系統運維人員,更換完存盤空間后,系統再將該緩沖區從 3#空閑緩沖區中調出,從而保證系統運行的穩定性,
當核心需有一個空閑緩沖區時,它根據要裝入的資料型別,從相應的空閑緩沖區鏈表的表頭位置取下一個空閑緩沖區,裝入個磁盤資料塊;
根據該資料塊所對應的設備號和塊號資料對計算其 hashed(散列、雜湊)值,根據其 hashno 的值放入到相應 hash 鏈表的鏈頭,
其中 hashed 計算規則如下:
\[hashno =( (diskno + blkno) / RND) \% BUFHSZ \]- disko:設備號
- blkno:塊號
- BUFHSZ:最大 hash 值,通常為 63,
- RND:亂數,其值為:RND= MAXBSIZE/ DEV BSIZE MAXBSIZE:最大檔案系統塊的大小 DEV
- BSIZE:物理設備塊大小
經過前邊知識的鋪墊下邊我們就可以詳細了解下緩沖池的具體結構:
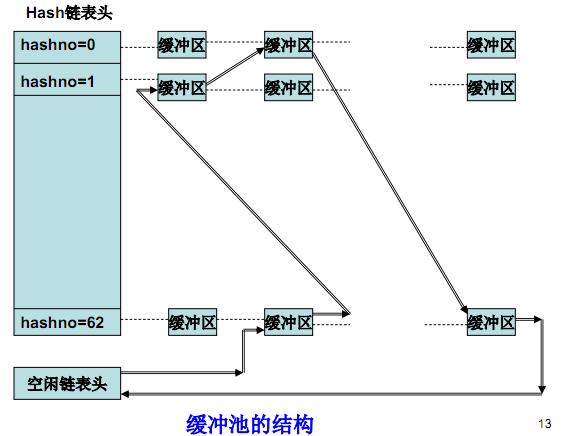
從圖中我們可以看到,一個緩沖區只有當它是空閑狀態時,它才同時處在 hash 鏈表和空閑鏈表中,如果不空閑,則它只能處在某一個 hash 鏈表中在空閑緩沖區鏈表中的緩沖區一定在某個 hash 鏈表中;在 hash 鏈表中的緩沖區不一定在空閑鏈中,不存在脫離 hash 鏈表的另一個空閑的緩沖區鏈表,
緩沖池中的緩沖區個數是固定不變的,每個緩沖區在不同時刻存放著不同的磁盤資料塊,具有不同的 hash 值,因此處在不同的 hash 鏈表中緩沖區中的資料與某個磁盤資料塊一一對應,這種對應有兩個特點:
①一個磁盤資料塊在緩沖池中最多只能有一個副本;
②緩沖區與資料塊的對應是動態的,LRU 資料塊將被釋放,
緩沖區的使用程序如下:
如果要找特定緩沖區,根據 has hno 從相應的 hash 鏈表的表頭處開始逐個向后查找;如果找到,則直接取用,并將其移動到 hash 鏈的鏈頭;如果未找到,則從相應的空閑緩沖區鏈表的表頭處取下一個空閑緩沖區,填入相應資料,重新計算其 hashed,并放到新的 hash 鏈表的表頭;
釋放緩沖區時,將該緩沖區仍保留在原 hash 佇列中,同時掛接到空閑緩沖區鏈表的表尾,(同時在兩個佇列中)
2.3 緩沖區的檢索演算法
在 UNX 檔案系統中的下層,即直接與邏輯存盤設備聯系的部分,包含如下基本演算法:
- gebk:申請一個緩沖區
- brelse:釋放一個緩沖區
- bread:讀一個磁盤塊
- bread:讀一個磁盤塊,預讀另一個磁盤塊
- bwrite:寫磁盤塊
2.3. 申請一個緩沖區演算法 getblk
根據緩沖池的結構,核心申請一個緩沖區分配個磁盤塊時,可能出現的五種典型狀況:
①該塊已在 hash 佇列中,并且緩沖區是空閑的;
②hash 佇列中找不到該塊,需從空閑鏈表中分配一個緩沖區;
③hash 佇列中找不到該塊,在從空閑鏈表中分配一個緩沖區時,發現該空閑緩沖區標記有“延遲寫”,核心必須寫出緩沖區內容到磁盤上,再重新分配一個空閑緩沖區
④hash 佇列中找不到該塊,并且空閑鏈表已空;
⑤該塊已在 hash 佇列中,但該緩沖區目前狀態為“忙”,
具體演算法的思路如下:
演算法 getblk
輸入:檔案系統號
塊號
輸出:現在能被磁盤塊使用的上了鎖的緩沖區
{
while(沒有找到緩沖區)
{
if(塊在散列佇列中)
{
if(空閑鏈表中無緩沖區) //第五種情況
{
sleep(等候“緩沖區變為空閑”事件);
continue;
}
為緩沖區標記上"忙"; //第一種情況
從空閑鏈表上摘下緩沖區;
return(緩沖區);
}
else //塊不在散列佇列中
{
if(空閑鏈表中無緩沖區) //第四種情況
{
sleep(等待“任何緩沖區為空閑”事件);
continue; //回到while回圈
}
//第二種情況找到一個空閑緩沖區
把舊散列佇列中摘下緩沖區;
把緩沖區投入到新的散列佇列中去;
return(緩沖區);
}
}
}
2.3.2 釋放一個緩沖區演算法 brelse
演算法 brelse
輸入:上鎖狀態的緩沖區
輸出:無
{
喚醒正在等待"無論哪個緩沖區變為空閑"這一事件的所有行程;
喚醒正在等待"這個緩沖區變為空閑"這一事件的所有行程;
提高處理機執行級別以封鎖中斷;
if(緩沖區內容有效且緩沖區非"舊")
將緩沖區送入空閑鏈表尾部;
else
將緩沖區送入空閑鏈表頭部;
降低處理機執行級別以允許中斷;
給緩沖區解鎖;
}
2.3.3 讀一個磁盤塊 bread
整個程序如下:
- 由 getblk 演算法申請一個可用的緩沖區
- 如果緩沖區中的內容有效,則直接回傳該緩沖區
- 如果緩沖區中的內容無效,則啟動磁盤去讀所需的資料塊
- 等待磁盤操作完成后回傳
演算法 bread
輸入:檔案系統號
輸出:含有資料的緩沖區
{
得到該塊的緩沖區(演算法 getblk);
if(緩沖區資料有效)
return(緩沖區);
啟動磁盤讀;
slep(等待"讀盤完成"事件);
return(緩沖區)
}
2.3.4 讀一個磁盤并預讀另一個磁盤塊 breada
預讀的前提:
程式是在一個有限的空間內運行,程式對資料的訪問是可預見的,
預讀的命中率:
不一定達到 100%,但良好的系統結構和演算法可使命中率達到較高的水平
預讀的結果:
放在緩沖池內,以免需要的時候再去啟動磁盤讀資料塊,
演算法 bread
輸入:(1)立即讀的檔案系統塊號
(2)異步讀的檔案系統塊號
輸出:含有立即讀的資料的緩沖區
{
if(第一塊不在高速緩沖中)
{
為第一塊獲得緩沖區(getblk);
if(緩沖區內容無效)
啟動磁盤度;
}
if(第二塊不在高速緩沖中)
{
為第二塊獲得緩沖區(getblk);
if(緩沖區資料有效)
釋放緩沖區(brelse);
else
啟動磁盤讀;
}
if(如果第一塊在高速緩沖中)
{
讀第一塊(bread);
return 緩沖區;
}
sleep(第一個緩沖區包含有效資料的事件);
return 緩沖區
}
2.3.5 寫餐盤塊 bwrite
寫操作分為兩種,一種是同步寫,另一種是異步寫,這兩種操作的根本區別在于本行程在進行寫操作時,是否等待磁盤驅動程式完成操作后所發出的中斷信號,如果等則是同步寫,否則為異步寫,
演算法 bwrite
輸入:緩沖區
輸出:無
{
啟動磁盤寫;
if(IO同步)
{
sleep(等待"O完成"事件);
釋放緩沖區( brelse);
}
else if(緩沖區標記著延遲寫)
{
為緩沖區做標記以放到空閑緩沖區鏈表頭部;
}
}
3. 總結
unix 作業系統引入高速緩沖之后帶來了極大的便利,但同時也有一些不足之處,下邊我們分別總結下告訴緩沖的優點以及其缺點,
優點:
- 提供了對磁盤塊的統一的存取方法
- 消除了用戶對用戶緩沖區中資料的特殊對齊需要
- 減少了磁盤訪問的次數,提高了系統的整體 MO 效率
- 有助于保持檔案系統的完整性
缺點:
- 資料未及時寫盤而帶來的風險
- 額外的資料拷貝程序,大量資料傳輸時影響性能
Reference
[1] unix 作業系統的設計
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/114342.html
標籤:Linux
下一篇:測驗會用到的linux命令