Ceph理論
- Ceph 簡介
Ceph 是一個開源專案,它提供軟體定義的、統一的存盤解決方案 ,Ceph 是一個具有高性能、高度可伸縮性、可大規模擴展并且無單點故障的分布式存盤系統 ,
Ceph 是軟體定義存盤解決方案
Ceph 是統一存盤解決方案
Ceph 是云存盤解決方案
Ceph 官方檔案:http://docs.ceph.com/docs/mimic/
2. Ceph 的架構:分布式服務行程

2.1 Ceph Monitor(MON)
Ceph 監視器服務行程,簡稱 MON,負責監控集群的監控狀態,所有的集群節點都向 MON 節點報告狀態以及每個狀態變化的資訊,MON 通過收集這些資訊并維護一個 Cluster Map 來完成它的任務,Cluster Map 下屬包含每個組件的 Map,例如:MON Map、OSD Map、PG Map、CRUSH Map 和 MDS Map,一個典型的 Cepb 集群中通常存在多個 MON 節點,它們之間啟用了仲 裁(Quorum)這種分布式決策機制,應用 Paxos 演算法保持各節點 Cluster Map 的一致性,所以集群中 MON 節點數應該是一個奇數,開始仲裁操作時至少要保證有一半以上的 MON 處于可用狀態,這樣才可以防止傳統存盤系統中常見的腦裂問題,OSD 只有在一些特殊情況(e.g. 添加新的 OSD、OSD 發現自身或他人存在例外)才會上報自己的資訊,平常只會簡單的發送心跳,MON 在收到這些上報資訊時,則會更新 Cluster Map 并加以擴散,
MON Map:維護著 MON 節點間端到端的資訊,包括 Ceph Cluster ID、MON hostname、IP:Port 以及當前 MON Map 的創建版本和最后一次修改資訊,幫助確定集群應該遵循哪個版本,
OSD Map:維護著 Ceph Cluster ID、OSD 數目、狀態、權重、主機、以及 Pool 相關的資訊(e.g. Pool name、Pool ID、Pool Type、副本數、PG ID),以及存盤了 OSD map 創建版本和最后一次修改資訊,
PG Map :維護著 PG 的版本、時間戳、容量比例、最新的 OSD Map 版本、PG ID、物件數、OSD 的 Up Set、OSD 的 Acting Set、Clean 狀態等資訊,
CRUSH Map:維護著集群的存盤設備資訊、故障域層次結構以及在故障域中如何存盤資料的規則定義,
MDS Map:維護著元資料池 ID、MDS 數量、狀態、創建時間和當前的 MDS Map 版本等資訊,
2.2 Ceph Object Storage Device Daemon(OSD)
Ceph 物件存盤設備服務行程,簡稱 OSD,一個 OSD 守護行程與集群中的一個物理磁盤系結,OSD 負責將資料以 Object 的形式存盤在這些物理磁盤中,并在客戶端發起資料請求時提供相同的資料,一般來說,物理磁盤的 總數與 Ceph 集群中負責存盤用戶資料到每個物理磁盤的 OSD 守護行程數是相等的,OSD 同時還負責處理資料復制、資料恢復、資料再平衡以及通過心跳機制監測其它 OSD 狀況并報告給 MON,對于任何 R/W 操作,客戶端首先向 MON 請求集群的 Map,然后客戶端就可以直接與 OSD 進行 I/O 操作,正是因為客戶端能夠直接與 OSD 進行操作而不需要額外的資料處理層,才使得 Ceph 的資料事務處理速度如此的快,
2.3 Ceph Metadata Server(MDS)[可選]
Ceph 元資料服務器服務行程,簡稱 MDS,只有在啟用了 Ceph 檔案存盤(CephFS)的集群中才需要啟用 MDS,它負責跟蹤檔案層次結構,存盤和管理 CephFS 的元資料,MDS 的元資料也是以 Obejct 的形式存盤在 OSD 上,除此之外,MDS 提供了一個帶智能快取層的共享型連續檔案系統,可以大大減少 OSD 讀寫操作頻率,
3. Ceph 的架構:核心組件
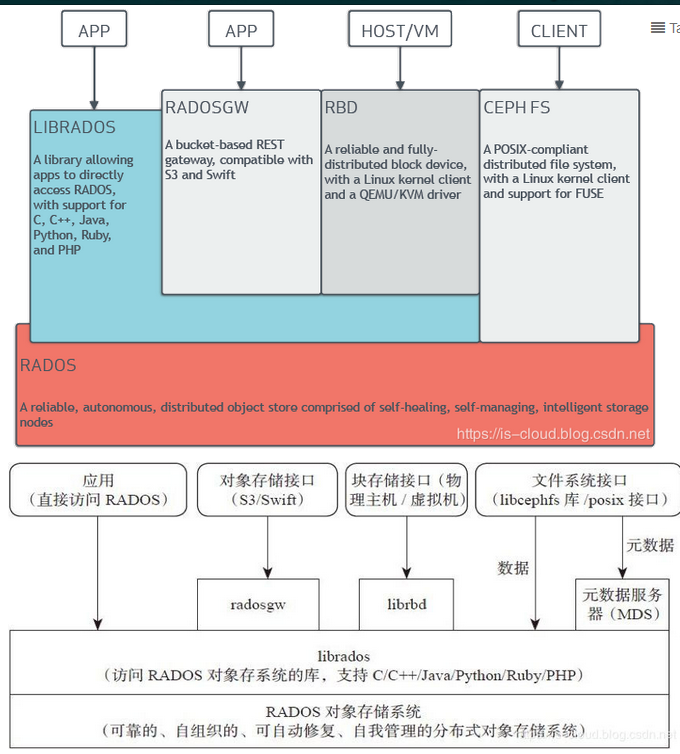
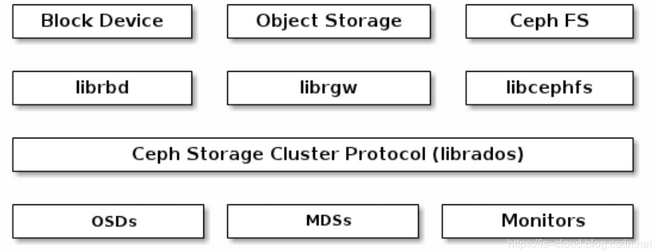
3.1 Ceph RADOS(Reliable, Autonomic, Distributed Object Store)
可靠、自動、分布式物件存盤系統,簡稱 Ceph 存盤集群,Ceph 的所有優秀特性都是由 RADOS 提供的,包括分布式物件存盤的資料一致性、高可用性、高可靠性、沒有單點故障、向我修復以及自我管理等,Ceph 的資料訪問方式(e.g. RBD, CephFS, RADOSGW 和 librados)都建立在 RADOS 之上,Cepb 中的一切都以物件的形式存盤,而 RADOS 就負責存盤這些物件,對于分布式存盤的資料一致性,RADOS 通過執行資料復制、故障檢測與恢復,還包括資料在集群節點間的遷移與再平衡來實作,
3.2 LIBRADOS
是一個 C 語言庫,簡稱 Ceph 基礎庫,對 RADOS 的功能進行了抽象和封裝,并提供北向 API,通過 librados,應用程式可以直接訪問 RADOS 原生功能,以此來提高了應用程式的性能、可靠性和效率,因為 RADOS 本質是一個物件存盤系統,所以 librados 提供的 API 都是面向物件存盤的,librados 原生介面的優點是它直接與應用代碼集成,操作非常方便,但也不會主動對上傳的資料進行分片,
librados 支持具有異步通信能力的物件存盤介面:
存盤池操作
快照
讀、寫物件
創建/洗掉
整個 Object 范圍或位元組范圍
追加或截斷
創建/設定/獲取/洗掉 XATTRs
創建/設定/獲取/洗掉 K/V 對
復合操作和雙重 ACK 語意
3.3 Ceph Reliable Block Storage(RBD)
Ceph 塊存盤,簡稱 RBD,是基于 librados 之上的塊存盤服務介面,RBD 的驅動程式已經被集成到 Linux 內核(2.6.39 或更高版本)中,也已經被 QEMU/KVM Hypervisor 支持,它們都能夠無縫地訪問 Ceph 塊設備,Linux 內核 RBD(KRBD)通過 librados 映射 Ceph 塊設備,然后 RADOS 將 Ceph 塊設備的資料物件以分布式的方式存盤在集群節點中,
3.4 Ceph RADOS Gateway(RGW)
Ceph 物件網關,簡稱 RGW,是基于 librados 之上的物件存盤服務介面,本質是一個代理,可以將 HTTP 請求轉交給 RADOS,同時也可以把 RADOS 請求轉換為 HTTP 請求,以此來提供 RESTful 物件存盤服務介面,并兼容 S3 和 Swift,
3.5 Ceph File System(CephFS)
Ceph 檔案系統,簡稱 CephFS,在 RADOS 層之上提供了一個任意大小且兼容 POSIX 的分布式檔案系統,CephFS 依賴 MDS 來管理其元資料(檔案層次結果),以此將元資料與原始資料分離,MDS 不直接向客戶端提供資料,因此可以避免單點故障,有助于降低軟體復雜性并提高可靠性,
- Ceph 的架構:內部構件
4.1 Ceph Client
Ceph 的客戶端是指使用 Ceph 存盤服務的一切物體物件,可能是一個 Client 軟體、一臺主機/虛擬機或者是一個 App,客戶端會根據 Ceph 提供的不同介面型別(服務介面、原生介面、C 庫)來連接并 Ceph 存盤服務器并使用相應的 Ceph 存盤服務,
4.1.1 客戶端的資料條帶化(分片)
當用戶使用 RBD、RGW、CephFS 型別客戶端介面來儲存資料時,會經歷一個透明的、將資料轉化為 RADOS 統一處理物件的程序,這個程序就稱之為資料條帶化或分片處理,
熟悉存盤系統的你不會對條帶化感到陌生,它是一種提升存盤性能和吞吐能力的手段,通過將有序的資料分割成多個區段并分別儲存到多個存盤設備上,最常見的條帶化就是 RAID0,而 Ceph 的條帶化處理就類似于 RAID0,如果想發揮 Ceph 的并行 I/O 處理能力,就應該充分利用客戶端的條帶化功能,需要注意的是,librados 原生介面并不具有條帶化功能,比如:使用 librados 介面上傳 1G 的檔案,那么落到存盤磁盤上的就是 1G 大小的檔案,存盤集群中的 Objects 也同樣不具備條帶化功能,實際上是由上述三種型別的客戶端將資料條帶化之后再儲存到集群 Objects 之中的,
條帶化處理程序:
將資料切分為條帶單元塊,
將條帶單元塊寫入到 Object 中,直到 Object 達到最大容量(默認為 4 M),
再為額外的條帶單元塊創建新的 Object 并繼續寫入資料,
回圈上述步驟知道資料完全寫入,
假設 Object 存盤上限為 4M,每一個條帶單元塊占 1M,此時我們儲存一個 8M 大小的檔案,那么前 4M 就儲存在 Object0 中,后 4M 就創建 Object1 來繼續儲存,
隨著儲存檔案 Size 的增加,可以通過將客戶端資料條帶化分割儲存到多個 Objects 中,同時由于 Object 映射到不同的 PG 上進而會映射到不同的 OSD 上,這樣就能夠充分利用每個 OSD 對應的物理磁盤設備的 IO 性能,以此實作每個并行的寫操作都以最大化的速率進行,隨著條帶數的增加對寫性能的提升也是相當可觀的,如下圖,資料被分割儲存到兩個 Object Set 中,條帶單元塊儲存的順序為 stripe unit 0~31,
Ceph 有 3 個重要引數會對條帶化產生影響:
order:表示 Object Size,例如:order=22 即為 2**22,即 4M 大小,Object 的大小應該足夠大以便與條帶單元塊相匹配,而且 Object 的大小應該是條帶單元塊大小的倍數,RedHat 建議的 Object 大小是 16MB,
stripe_unit:表示條帶單元塊寬度,客戶端將寫入 Object 的資料切分為寬度相同的條帶單元塊(最后走一塊的寬度未必一致),條帶寬度應該是 Object 大小的一個分數,比如:Object Size 為 4M,單元塊為 1M,那么一個 Object 就能包含 4 個單元塊,以便充分利用 Object 的空間,
stripe_count:表示條帶數量,根據條帶數量,客戶端將一批條帶單元塊寫入到 Object Set 中,
NOTE:由于客戶端會指定單個 Pool 進行寫入,所以條帶化到 Objects 中的所有資料都會被映射在同一個 Pool 包含的 PGs 內,
4.1.2 客戶端對 Object 的監視和通知
客戶端可以向 Object 注冊持久的監聽,并保持與 Primary OSD 的會話,這就是客戶端對 Object 的監視與通知性,該特性使得監聽同一個 Object 的客戶端之間可以使用 Object 來作為通信的渠道,
4.1.3 客戶端的獨占鎖(exclusive-lock)
客戶端的獨占鎖特性提供一種可以對 RBD 塊設備進行 “排它性的” 鎖定,這有助于解決多個客戶端對同一個 RBD 塊設備進行操作時,多個客戶端嘗試同時向同一個 Object 寫入資料導致的沖突,獨占鎖特性需要依賴客戶端對 Object 的監視與通知特性,在資料寫入時,如果一個客戶端首先在 Object 上放置了獨占鎖,則能夠被其它客戶端在寫入資料前檢查到,并放棄資料寫入,設定了這一特性的話,同一時刻只有一個客戶端能夠對 RBD 塊設備進行修改,常被應用到快照創建、快照洗掉這種改變塊設備內部結構的操作,強制的獨占鎖功能特性默認是不開啟的,需要在創建鏡象時顯式的通過選項 --image-features 啟用,
rbd -p mypool create myimage --size 102400 --image-features 5
# 5 = 4 +1
# 1:啟用分層特性
# 4:啟用獨占鎖特性??
4.1.4 客戶端的 Object 映射索引
客戶端可以在資料寫入到 RBD Image 時會跟蹤這些 Object(建立映射索引),從而讓客戶端可以在資料讀寫時就能知道相應的 Objects 是否存在,省去了遍歷 OSD 以確定 Objects 是否存在的開銷,Object 的映射索引保存在 librbd 客戶端的記憶體中,該特性對一些 RBD Image 操作比較有利:
縮容:僅洗掉存在的尾部 Objects,
匯出操作:僅匯出存在的 Objects,
復制操作:僅存在的 Objects,
扁平化:僅將存在的 Parent Objects 拷貝到 Clone Image,
洗掉:僅洗掉存在的 Objects,
讀取:僅讀取存在的 Objects,
Object 映射索引特性默認也是不開啟的,同樣需要在創建鏡象時顯式的通過選項 --image-features 啟用,
rbd -p mypool create myimage –size 102400 –image-features 13
# 13 = 1 + 4 + 8
# 1:啟用分層特性
# 4:啟用獨占鎖特性
# 8:啟用 Object 映射索引??
4.2 CRUSH(Controlled Replication Under Scalable Hashing)
可控的、可擴展的、分布式的副本資料放置演算法,本質是一種偽隨機資料分布演算法,類似一致性哈希,是 Ceph 的智能資料分發機制,管理著 PG 在整個 OSD 集群的分布,CRUSH 的目的很明確, 就是一個 PG 如何與 OSD 建立關系,它是 Ceph 皇冠上的寶石,
4.2.1 動態計算元資料
傳統物理存盤設備的存盤機制都涉及存盤原始資料及其元資料,元資料存盤了原始資料存盤在存盤節點和磁盤陣列的地址資訊,每一次有新資料寫入存盤系統時,元資料最先更新,更新的內容就是原始資料將會存放的物理地址,在此之后才是原始資料的寫入,Ceph 則拋棄了這種存盤機制,使用 CRUSH 演算法動態計算用于存盤 Object 的 PG,同時也用于計算出 PG 的 OSD Acting Set(Acting Set 即為活躍的 OSD 集合,集合中首編號的 OSD 即為 Primary OSD),CRUSH 按需計算元資料,而不是存盤元資料,所以 Ceph 消除了傳統的元資料存盤方法中的所有限制,具有更好的容量、高可用性和可擴展性,
4.2.2 基于 CRUSH bucke 的故障域/性能域劃分
除此之外,CRUSH 還具有獨特的基礎設施感知能力,可以識別整個基礎設施中的物理組件拓撲(故障域和性能域),包括磁盤、節點、機架(Rack)、行(Row)、開關 、電源電路、房間、資料中心以及存盤介質型別等多種 CRUSH bucke 型別,bucket 表明了設備的具體物理位置,這種感知能力使得 CRUSH 可以讓客戶端進行跨故障域寫入資料,以此來保證資料的安全性,CRUSH bucke 包含在 CRUSH Map 中,CRUSH Map 還保存了一系列可定義的規則(CRUSH Rules),告訴 CRUSH 如何為不同的 Pool 復制資料,CRUSH 使得 Ceph 能夠自我管理和自我療愈,當故障區域中的組件故障時,CRUSH 能夠感知哪個組件故障了,并自動執行相應的資料遷移、恢復等動作,使用 CRUSH,我們能夠設計一個沒有單點故障的高度可靠的存盤基礎設施,CRUSH 也可使客戶端能夠將資料寫入特定型別的存盤介質中,例如:SSD、SATA,CRUSH Rules 決定了故障域以及性能域的范圍,
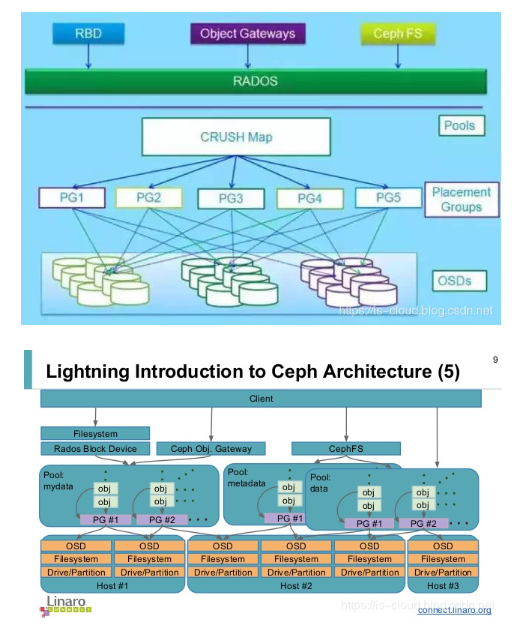
4.3 Object
物件,是 Ceph 的最小存盤單元,每個 Object 都包含了在集群范圍內唯一的標識、二進制資料、以及由一組鍵值對組成的元資料,系結在一起的原始資料與元資料,并且具有 RADOS 全域唯一的識別符號 OID,無論上層應用的是 RBD、CephFS 還是 RADOSGW,最終都會以 Object 的方式存盤在 OSD 上,當 RADOS 接收到來向客戶端的資料寫請求時,它將接收到的資料轉換為 Object,然后 OSD 守護行程將資料寫入 OSD 檔案系統上的一個檔案中,
4.4 Placement Group(PG)
歸置組,簡稱 PG,PG 是一組 Objects 的邏輯集合,一個 Ceph 存盤池可能會存盤數百萬或更多的資料物件,因為 Ceph 必須處理資料持久化(副本或糾刪碼資料塊)、清理校驗、復制、再平衡以及資料恢復,因此以 Object 作為管理物件就會出現擴展性和性能上的瓶頸,Ceph 通過引入 PG 層來解決這個問題,CRUSH 分配每個 Object 到指定的 PG 中,每個 PG 再映射到一組 OSD 中,PG 是保障 Ceph 可伸縮性和性能必不可少的部分,當資料要寫入 Ceph 時,首先會將將資料分解成一組 Objects,然后根據 Object 名稱、復制級別和系統中的總 PG 數等資訊執行散列操作并生成 PG ID,最后依據 PG ID 將 Objects 資料分散到各個 PG 中,沒有 PG,在成千上萬個 OSD 上管理和跟蹤數以百萬計的 Objects 的復制和傳播是相當困難的,將包含大量 Objects 的 PG 作為管理和復制的物件,可以有效縮減計算資源的損耗,每個 PG 都會消耗一定的計算資源(CPU、RAM),所以存盤管理員應該
精心計算集群中的 PG 數量,
4.4.1 計算 PG 數
上文中我們提到過,PG 數會在一定程度上影響存盤性能,一個 OSD 的 PG 數可以被動態修改,但建議在部署規劃時期就能夠對 PG 數有一定的把握,常見的,有以下幾種 PG 數計算方式:
計算集群 PG 總數
PG 總數 = (OSD 總數 x 100) / 最大副本數??
結果取最接近 2 的 N 次冪,比如:集群有 160 個 OSD 且副本數為 3,那么根據公式計算得到的 PG 總數是 5333.3,再舍入這個值到最接近的 2 的 N 次幕,最終結果為 8192 個 PG,
計算 Pool 下屬的 PG 總數
PG 總數= ((OSD 總數 x 100) / 最大副本數) / 池數??
結果同樣取最接近 2 的 N 次冪,
4.4.2 PG 與 PGP
PG - Placement Group
PGP - Placement Group for Placement purpose
pg_num - number of placement groups mapped to an OSD
When pgnum is increased for any pool, every PG of this pool splits into half, but they all remain mapped to their parent OSD.Until this time, Ceph does not start rebalancing. Now, when you increase the pgpnum value for the same pool, PGs start to migrate from the parent to some other OSD, and cluster rebalancing starts. This is how PGP plays an important role.
顧名思義,PGP 是為了實作定位而設定的 PG,PGP 的數量應該與 PG 總數保持一致,對于一個 Pool 而言,當你增加了 PG 的數量,這個 Pool 的 PG 同時還應該修改 PGP 的數量,讓兩者保持一致,這樣集群才能夠觸發再平衡動作,
pg_num 的增加會使舊 PGs 中的 Objects 再平衡到新建 PG 中,舊 PGs 之間不會發現 Object 遷移并且依舊保存原有的 OSD 映射關系,
pgp_num 的增加會使新 PGs 在平衡到 OSDs 中,而舊 PGs 依舊保存原有的 OSD 映射關系.
PGP 決定了 PG 的分布,
4.4.3 PG Peering 操作、Acting Set 與 Up Set
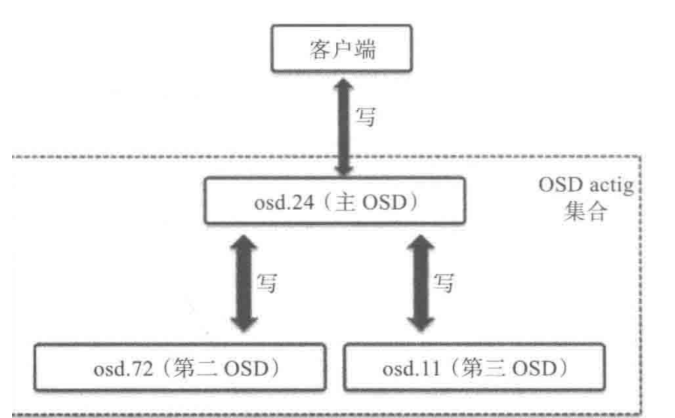
OSD 守護行程會為每個 PG 的副本執行 Peering 操作,確保 PG 對應的主從 OSDs 之間的 PG 副本是一致的,這些主從 OSDs 以 Acting Set 的形式組織起來,Acting Set 的第一個元素就是 Primary OSD,保存著 PG 的主副本,其余為 Replica OSDs 中保存的是 PG 的第二/第三副本(假設副本數為 3),Primary OSD 負責 Replica OSDs 之間的 PG 的 Peering 操作,當 Primary OSD 狀態為 down 時,首先會從 Up Set 中移除,然后由第二 OSD 晉升為 Primary OSD,故障 OSD 中的 PG 會以同步到其他 OSD 的方式還原,并將新的 OSD 加入到 Actin Set 和 Up Set 中,以確保整個集群的高可用性,
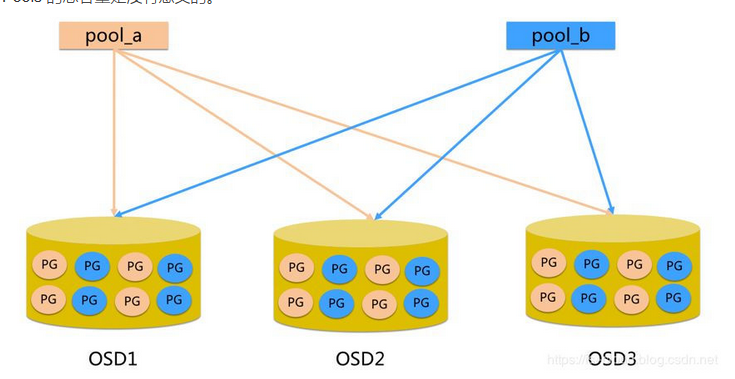
Pool
存盤池,是一個面向管理員的、用來隔離 PGs 和 Objects 的邏輯磁區,簡單來說,Pool 就是一個管理員自定義的命名空間,不同的 Pool 可以具有完全不同的資料處理方式,例如:Replica Szie(副本數)、PG Num、CRUSH Rules、快照、所屬者及其授權等,可以為特定型別的資料創建存盤池,比如:塊設備、物件網關,亦或僅僅是為了多用戶隔離而創建 Pool,
管理員可以為 Pool 設定所有者和訪問權限,還支持快照功能,當用戶通過 API 來存盤資料時,需要指定 Objects 要存盤到哪一個 Pool 中,管理員可以對不同的 Pool 設定相關的優化策略,比如 PG 副本數、資料清洗次數、資料塊及 Object 的 Size 等等,Pool 提供了一個有組織的存盤管理方式,每個 Pool 都會交叉分布在集群節點的 OSDs 上,這樣能夠提供足夠的彈性,除了 PG 副本數,也可以通過指定糾刪碼的規則集來提供與副本數同等級別的可靠性,而且只消耗更少的空間,
當把資料寫人到一個 Pool 時,首先會在 CRUSH Map 找到與 Pool 對應的規則集,這個規則集描述了 Pool 的副本數資訊,在部署 Ceph 集群時會創建一些默認的存盤池(e.g. data、metadata、rbd),
Pool 也存在容量的概念,但 Pool Size 只在限制最大容量或者 QoS 的場景中有用,并不是真實的容量,因為 Pools 與 OSDs 之間的隱射是交叉的,Pools 的總容量大于 Ceph Cluster GLOBAL Size,所以 Pools 的總容量是沒有意義的,
-
Ceph 的設計思想
此處不妨小結一下 Ceph 每個內部構件的設計含義及其存在的意義,以 Object 作為 Ceph 的最小存盤單元充分地展示了 Ceph 宏大的野心 —— 要成為新一代(或者成為云時代)的存盤架構,眾所周知,元資料是關于原始資料的資訊,它決定了原始資料將往哪里存盤,從哪里讀取,傳統的存盤系統通過維護一張集中式的查找表來跟蹤它們的元資料,這直接導致了傳統存盤系統查找性能低(容量有限)、單點故障(可靠性低)、資料一致性(可擴展性低)等問題,為了實作這一目標,Ceph 就必須打破傳統存盤系統的桎梏,采用更加智能的元資料管理方法,以離散的方式來存盤原始資料及其元資料,再以動態計算的方式來定位資料的所在,這就是 Object + CRUSH,在此基礎之上,RADOS 的引入就是為了解決分布式運行環境中的資料一致性、高可用性和自我管理等問題;PG 的引入就是為了縮小 RADOS 的管理物件以及 Objects 的遍歷尋址空間,進一步提升性能和降低內部實作復雜度,在進行資料遷移時,也是以 PG 作為遷移單位,有了 PG 之后 Ceph 會盡量避免直接操作 Objects;Pool 的引入就是為了抽象出更加友好的資源管理與操作模型,例如:PG 的數量以及 PG 的副本數都是以 Pool 為單位設定的,提供了良好的用戶操作體驗,在如此可靠、自動、分布式的物件存盤系統之上再構建 librados、RBD、RGW、CephFS 等多種更便于應用或客戶端使用的上層介面型別,真正實作了下層抽象統一、上層異構兼容的統一存盤解決方案,回頭再看,Ceph 成功的原因很簡單,其 SDS(軟體定義存盤)基因所帶來的 “可編程性” 不正是云時代所渴望的嗎? -
Ceph 的資料讀寫原理
6.1 資料儲存的三個映射程序
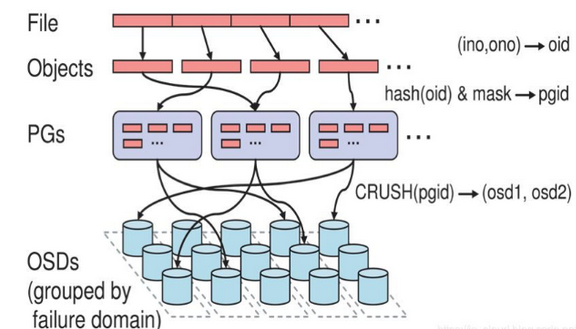
Ceph 存盤系統中,資料存盤分三個映射程序:
Step 1. 將要存盤的 File 資料映射(切分)為 RADOS 可以處理的 Objects(1:N):(ino, ono) -> oid
ino:File 的元資料,File 的唯一標識
ono:File 切分產生的某個 Object 時的分片編號,默認以 4M 大小切分
oid:Object 唯一標識,存盤了 Obejcts 與 File 的從屬關系
Step 2. 將 Objects 映射到 PG(N:1):hash(oid) & mask -> pgid,Ceph 指定一個靜態 HASH 函式將 oid 映射成一個近似均勻分布的偽隨機值,然后將這個值與 mask 按位相與,得到 PG ID,
mask:PG 總數 m - 1,m 為 2 的整數冪
Step 3. 將 PG 映射到 OSDs(N:M):CRUSH(pgid) -> (osd1,osd2,osd3),傳入 pgid 到 CRUSH 演算法計算得到一組 OSD 陣列(長度與 PG 副本數相同),
File 資料最終分散保存在這些 OSDs 中,
調度演算法的偽代碼:
locator = object_name
obj_hash = hash(locator)
pg = obj_hash % num_pg
osds_for_pg = crush(pg) # returns a list of osds
primary = osds_for_pg[0]
replicas = osds_for_pg[1:]??
6.2 客戶端的 I/O 定位
當客戶端讀寫資料時,首先需要與 MON 節點建立連接并下載最新的 Cluster Map,客戶端讀取 Cluster Map 中的 CRUSH Map(包含 CRUSH Rules、CRUSH bucke)和 OSD Map(包含所有 Pool 的狀態和所有 OSDs 的狀態),Crush Rules 就是資料映射的策略,決定了每個 Object 有多少個副本,這些副本應該如何存盤,當把資料寫入一個 Pool 時,可以通過 Pool name 匹配到一個 CRUSH Rules,客戶端通過這些資訊在本地執行 CRUSH 演算法獲得資料讀寫的 Primary OSD 的 IP:Port,然后就可以與 OSD 節點直接建立連接來傳輸資料了,CRUSH 動態計算的動作發生在客戶端,不需要有集中式的主節點用于尋址,客戶端分攤了這部分作業,進一步減輕了服務端的作業負載,
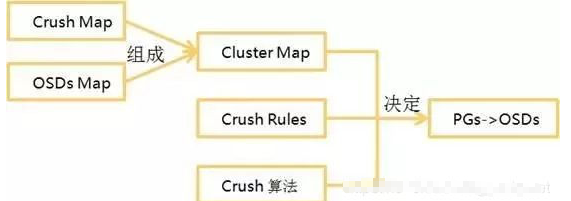
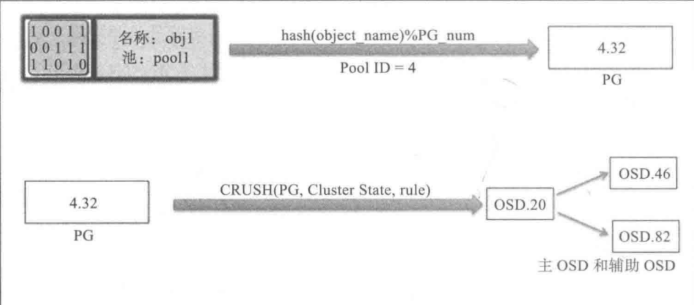
客戶端輸入 Pool name 以及 Object ID(例如:Pool=“pool1”, Object=”obj1”),
CRUSH 獲取 Object ID 后對其進行 HASH 編碼,
CRUSH 根據上一步的 HASH 編碼與 PG 總數求模后得到 PG ID,(e.g. HASH 編碼后為 186,而 PG 總數為 128,則求模得 58,所以這個 Object 會存盤在 PG_58 中),
CRUSH 計算對應 PG ID 的主 OSD,
客戶端根據 Pool name 稱得到 Pool ID(e.g. pool1=4),
客戶端將 PG ID 與 Pool ID拼接(e.g. 4.58)
客戶端直接與 Activtin Set 集合中的主 OSD 通信,來執行物件的 IO 操作,
6.3 主從 OSD 的副本 I/O
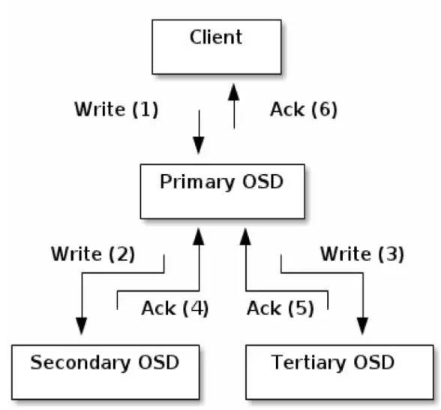
首先我們需要了解到 Ceph 的讀寫操作采用了主從模型,當客戶端讀寫資料時,都只能向 Object 對應的 Primary OSD 發起請求,同時 Ceph 還是一個 強一致性 分布式存盤,也就是說保證分布式資料的一致性同步程序并非異步操作,只有當所有的主從 OSD 都寫入資料之后才算是一次成功的寫入,客戶端使用 CRUSH 演算法計算 Object 映射的 PG ID 以及 Acting Set 串列,Acting Set 的首元素就是 Primary OSD,剩下的為 Replica OSD,
6.4 提升性能的日志 I/O
強一致性的資料同步方式在帶來了高度的資料一致性的同時也存在一些缺點,比如:寫性能低,為了提高寫性能,Ceph 采用了一種普遍的應對方式 —— 日志快取的機制,
當有突發的寫入峰值時,Ceph 會先把一些零散的、隨機的 IO 請求保存到快取中進行合并,然后再統一向內核發起 IO 請求,這種方式有效提升了執行效率,但一旦 OSD 節點崩潰,快取中的資料也會隨之丟失,所以,Ceph OSD 包含兩個不同的部分:OSD 日志部分(journal 檔案)和 OSD 資料部分,每一個寫操作都包含兩個步驟:首先將 Object 寫入日志部分,然后再將同一個 Object 從日志部分寫人資料部分,當 OSD 崩潰后重新啟動時,會自動嘗試從 journal 恢復因崩潰而丟失的快取資料,因此,journal 的 IO 是非常密集的,而且由于一個資料要 IO 兩次,很大程度上也損耗了硬體的性能,從性能的角度來看,在生產環節中建以使用 SSD 存盤來日志,使用 SSD 可以通過減少訪問時間和讀取延遲實作吞吐量的顯著提升,
如果使用 SSD 來存盤日志,我們可以在每一個物理 SSD 磁盤上創建一個邏輯磁區來作為日志磁區,這樣每個 SSD 的日志磁區就可以映射到一個 OSD 的資料磁區,journal 檔案的大小默認為 5G,在這種部署方案中,切記不要在同一個 SSD 上存盤過多的日志以避免超出它的上限而影響到整體性能,建議在每一個 SSD 磁盤上不應該存盤超過 4 個 OSD 的日志,但需要注意的是,使用單一 SSD 磁盤來存盤多個日志的另一個壞處是容易發生單點故障,所以也建議使用 RAID1 來避免這種情況,
6.5 資料寫入 OSD 的 UML 流程
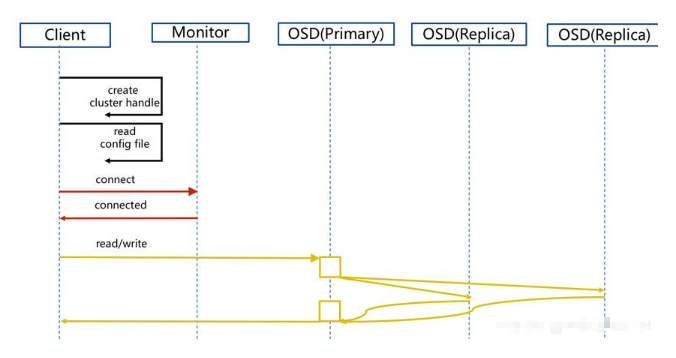
Client 創建 Cluster Handler,
Client 讀取組態檔,
Client 連接上 MON,獲取 Cluster Map 的副本,
根據 CRUSH Map 記錄的故障域以及資料分發規則資訊,找到 Client 讀寫 I/O 的目的 Primary OSD(主 OSD),
根據 OSD Map 記錄的 Pool 副本數(這里假設副本數為 3),首先將資料寫入 Primary OSD,Primary OSD 再復制相同的資料到兩個 Replica OSD 中,并等待它們確認寫入完成,
Replica OSD 完成資料寫人,它們就會發送一個應答信號給 Primary OSD,
最后,Primary OSD 再返問一個應答信號給客戶端,以確認完成整個寫人操作 ,
6.6 資料寫入新 Primary OSD 的 UML 流程
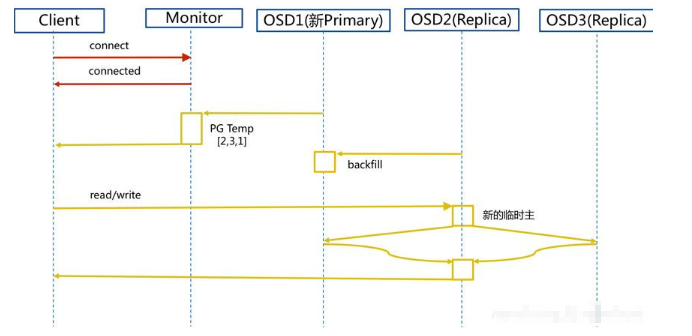
Client 連接 MON,獲取 Cluster Map 的副本,
新 Primary OSD 由于不存在任何 PG,所以主動上報 MON 暫時由 Primary OSD 2 升級為臨時 Primary OSD,
臨時 Primary OSD 把 PG 全量同步給新 Primary OSD,
Client I/O 直接連接臨時 Primary OSD,
臨時 Primary OSD 接收到資料后同時復制另外兩個 OSD,并等待它們確認寫入完成,
三個 OSD 都同步寫入資料后返問一個應答信號給客戶端,以確認完成整個寫人操作 ,
如果臨時 Primary OSD 與新 Primary OSD 的全量資料完成,則臨時 Primary OSD 再次降級為 Replica OSD,
- Ceph 的自管理
7.1 OSD 的心跳機制
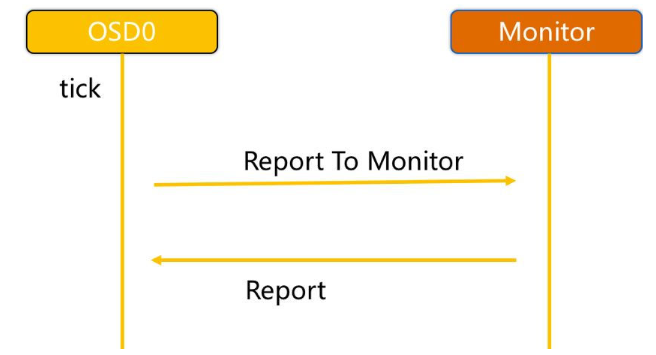
心跳機制是最常見的故障檢測機制,Ceph 使用心跳機制來檢測 OSD 是否正常運行,以便及時發現故障節點并進入相應的故障處理流程,OSD 的狀態(Up/Down)反映了其健康與否,OSD 加入到集群后會定期的上報心跳到 MON,但假如 OSD 已然故障的話就不會在繼續上報自己為 Down 的狀態了,所以具有關聯關系的 OSDs 之間也會互相評判對方的狀態,如果發現對方 Down 掉了,則會協助上報到 MON,當然了,MON 也會定期的 Ping 這些 OSD 以此來確定它們的運行情況,Ceph 通過伙伴 OSD 匯報失效節點以及 MON 統計來自 OSD 的心跳檢測兩種方式判定 OSD 節點是否失效,
OSD 服務行程會監聽 Public、Cluster、Front 和 Back 四個埠:
Public 埠:監聽來自 MON 和 Client 的連接,
Cluster 埠:監聽來自 OSD Peer 的連接,
Front 埠:監聽供客戶端連接到集群所使用的網卡,
Back 埠:監聽供集群內部使用的網卡,
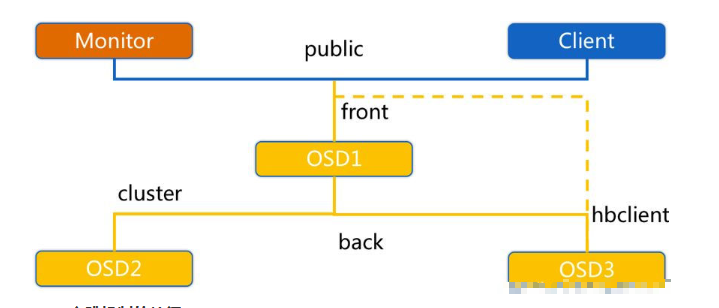
OSD 心跳機制的特征:
及時:伙伴 OSD 可以在秒級發現失效節點匯報至 MON,并在幾分鐘內由 MON 將失效 OSD 下線,
適當的壓力:由于有伙伴 OSD 協同匯報,MON 與 OSD 之間的心跳檢測更像是一種保險措施,因此 OSD 向 MON 發送心跳的間隔可以長達 600 秒,MON 的檢測閾值也可以長達 900 秒,Ceph 將故障檢測程序中中心節點的壓力分散到所有的 OSD 上,以此提高了中心節點 MON 的可靠性,進而提高整個集群的可擴展性,
容忍網路抖動:MON 收到 OSD 對其伙伴 OSD 的匯報后,并沒有馬上將目標 OSD 下線,而是周期性的等待一下幾個條件:
目標 OSD 的失效時間大于通過固定量 osd_heartbeat_grace 和歷史網路條件動態確定的閾值,
來自不同主機的匯報達到 mon_osd_min_down_reporters,
滿足前兩個條件前失效匯報沒有被源 OSD 取消,
擴散:作為中心節點的 MON 并沒有在更新 OSD Map 后嘗試廣播通知所有的 OSD 和 Client,而是惰性的等待 OSD 和 Client 來獲取,以此來減少 MON 的壓力并簡化互動邏輯,
7.2 OSD 之間相互的心跳檢測
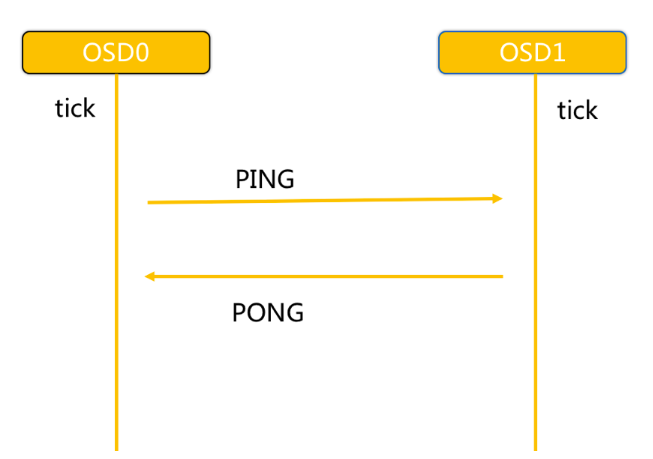
同一個 PG 內 OSDs 之間互相發送 PING/PONG 資訊,
每隔 6s 檢測一次,
20s 沒有檢測到心跳回復,將對方加入 Failure 佇列,
7.3 OSD 與 MON 間的心跳機制
7.4 OSD 擴容時的 PG 遷移與再平衡
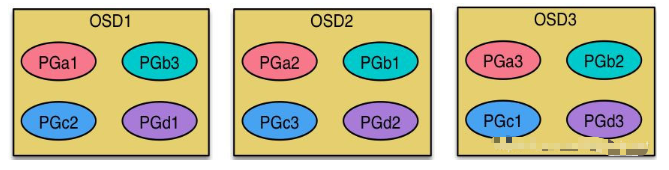
將一個新的 OSD 添加到 Ceph 集群時,Cluster Map 也會更新,這一變化會改變 CRUSH 計算時輸入的引數,也就間接的改變了 Object 放置的位置,CRUSH 演算法是偽隨機的,但會均勻的放置資料,所以 CRUSH 會開始執行再平衡操作,并且會讓盡量少的資料發生遷移,一般遷移的資料量是集群總資料量與 OSD 數量的比值,例如:在有 50 個 OSD 的集群中,當新增加一個 OSD 時,就只會有 1/50(2%)的資料會被遷移,并且所有舊 OSD 會并行地移動資料,使其能夠迅速的完成,在生產環境中對于利用率高(刷寫量大速快)的 Ceph 集群,建議先將新的 OSD 權重設為 0,再逐漸增加權重,通過這種方式,能夠減少再平衡操作對 Ceph 集群性能有較大的影響,再平衡機制保證了所有磁盤能能夠被均勻的使用,以此提升集群性能和保持集群健康,
擴容前:
擴容后:

上圖可見,虛線的 PGs 會自動遷移到新的 OSD 上,
7.5 資料擦除(Clean)
資料擦除是 Ceph 維護資料一致性以及整潔性的手段,OSD 守護行程會完成 PG 內的 Object 清理作業,它會比較副本間 PGs 內的 Object 元資料資訊,捕獲例外或檔案系統的一些錯誤,這類 Clean 是 Day 級別的調度策略,OSD 還只會更深層次的比較,對資料本身進行按位比較,這種深層次的比較可以發現驅動盤上壞的扇區,一般是 Week 級別的調度策略,
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/137649.html
標籤:Linux
上一篇:linux中vim使用技巧