小白剛剛學習scrapy,遇到個問題,想不明白,求助:
簡單寫了個爬蟲,訪問scrapy官方教程網頁,想提取首頁的全部作者,代碼如下:
import scrapy
class Quote_Spider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['http://quotes.toscrape.com/']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
content = response.xpath("//div[@class='col-md-8']")
print("8"*30)
print(content[0].extract())
print('*'*30)
print(content[0].xpath("//div//small/text()").extract())
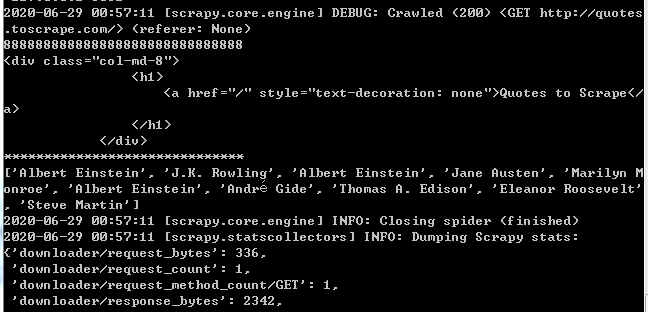
其中content list應該包含兩個selector,其中content[0]不包含要提取的作者元素,content[1]是包含的并能成功提取。那么為什么content[0]明明不包含作者元素,我一樣能篩選出來。。。。求解,抓狂中。。。 執行截圖如下:
uj5u.com熱心網友回復:
沒人么,問題解決了uj5u.com熱心網友回復:
沒人么,問題解決了轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/21002.html
標籤:專題技術討論區