本文目錄:
1.安裝mycat
2.mycat全域表
3.mycat讀寫分離
4.mycat分片規則
5.E-R表
6.HAProxy
7.mycat負載均衡集群
8.Keepalived
1.安裝mycat
1.解壓
tar -zxvf Mycat-server-1.6.7.3-release-20190828135747-linux.tar.gz
2. 為了更好的看目錄結構,安裝tree
yum -y install tree
# 查詢mycat的目錄結構,我的mycat是安裝在study下的
tree /study/mycat
3. 設定MYCAT_HOME的變數(如果沒有安裝jdk,還需要安裝jdk):
vi /etc/profile
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
export MYCAT_HOME=/study/mycat
4.重繪使變數生效:
source /etc/profile
5.設定 wrapper.java.command 的java 路徑(mycat的conf目錄下):
vi wrapper.conf
wrapper.java.command=%JAVA_HOME%/bin/java
6.修改server.xml(開啟實時統計,便于后期安裝mycat-eye的監測):
<!-- 1為開啟實時統計、0為關閉 -->
<property name="useSqlStat">1</property>
7.修改schema.xml:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<!--schema表示當前mycat維護的一個邏輯庫相關配置,邏輯庫中可以包含多個邏輯庫-->
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--邏輯庫:客戶端連接mycat,可以看到的所有庫并不是真實的資料庫資源而是mycat經過資源整合之后
允許客戶端查看到的schema邏輯庫,用戶是否有權限查看到邏輯庫,取決于server.xml中的配置的用戶屬性schemas,
對應的就是這個schema標簽的name-->
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3"
rule="mod-long" />
<table name="employee" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"
parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
<!--測驗配置一個邏輯表-->
<table name="test_table" primaryKey="id" dataNode="dn1"></table>
</schema>
<!--配置mycat的分片節點-->
<dataNode name="dn1" dataHost="localhost1" database="test" />
<dataNode name="dn2" dataHost="localhost1" database="test_mycat" />
<dataNode name="dn3" dataHost="localhost1" database="test" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts,這里的密碼對應資料庫的密碼 -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="****">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="localhost:3306" user="root" password="****" />
</writeHost>
</dataHost>
</mycat:schema>
7.配置完成后,可以運行./mycat console 查詢配置是否出錯(mycat的bin目錄下)
8.啟動mycat:
./mycat start
9.啟動mysql,下面的-h后面的ip替換成自己的,密碼是在server.xml里面配置的root的密碼:
mysql -uroot -p -P8066 -h192.168.189.150 -DTESTDB --default_auth=mysql_native_password
測驗
我這里使用的test_table表,在mycat里面插入一條資料:
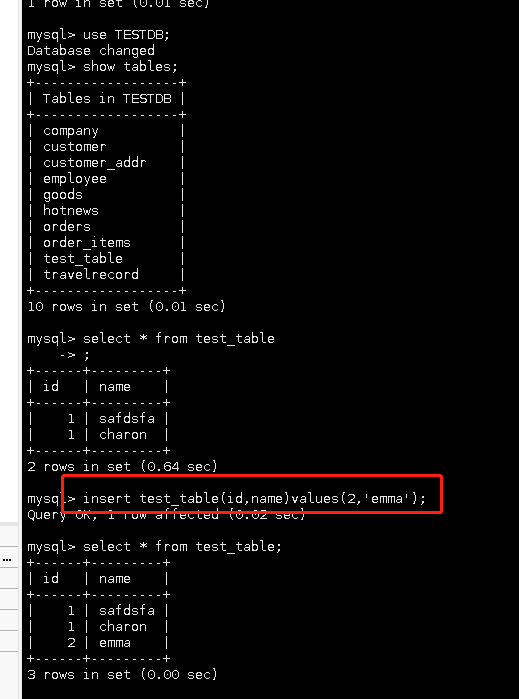
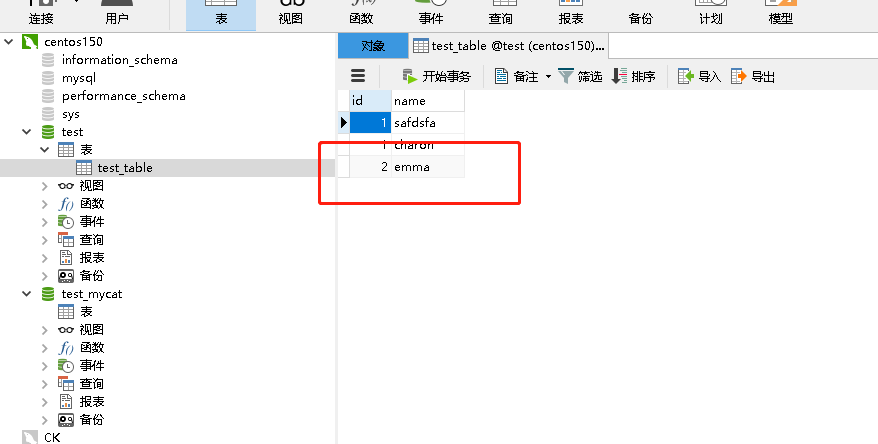
然后使用navicat打開我的資料庫,可以看到剛剛insert的資料已經插入進去了:
2.mycat全域表
1.全域表的概念
在專案中,總會一部分字典項等資料,這種資料一般資料量不會很大,而且改動也比較少,在mycat中將這種表稱之為全域表,通常這種表可以不需要進行拆分,每個分片都創建一張相同的表,在所有的分片上都保存一份資料,在進行插入、更新、洗掉的時候,會將sql陳述句發送到所有的分片上執行,在進行查詢時,也會把sql發送到各個分片上,這樣避免了跨庫的關聯操作,直接與本分片上的全域表進行聚合操作,
2.全域表的特征
- 插入、更新操作會實時在所有的節點上執行,保持各分片的資料一致性
- 查詢時,只從一個節點獲取
- 可以跟任何一個表進行jion操作
3.全域表測驗
1.打開資料庫主從并在主庫中創建資料庫/表
create database test_global01;
use test_global01;
CREATE TABLE `order_status` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`status_name` varchar(20) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
create database test_global02;
use test_global02;
CREATE TABLE `order_status` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`status_name` varchar(20) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
create database test_global03;
use test_global03;
CREATE TABLE `order_status` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`status_name` varchar(20) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.配置schema.xml,配置上一步創建的表
? 在schema.xml里配置一個表,和真實資料庫表要對應,要將三個分片都包含進去, type="global"這個表示全域表,必填,注意分片節點最好設定不一樣,如果分片節點設定相同的,可能會出現在mycat上插入了一次,但在sql上卻執行了幾次的情況,即在資料庫中多條記錄,
<table name="order_status" dataNode="dn$1-3" primaryKey="id" type="global"></table>
<!--配置mycat的分片節點-->
<dataNode name="dn1" dataHost="localhost1" database="test_global01" />
<dataNode name="dn2" dataHost="localhost1" database="test_global02" />
<dataNode name="dn3" dataHost="localhost1" database="test_global03" />
3.將schema.xml并上傳到服務器中,并查看沒有問題
4.啟動mycat并插入測驗資料
insert into order_status(status_name) values ('ORDER_NOT_PAY');
insert into order_status(status_name) values ('ORDER_PAY');
insert into order_status(status_name) values ('ORDER_FINISH');
使用explain查看mycat的插入可以看到,對三個分片都進行了執行
mysql> explain insert into order_status(status_name) values ('ORDER_PAY');
+-----------+------------------------------------------------------------+
| DATA_NODE | SQL |
+-----------+------------------------------------------------------------+
| dn1 | insert into order_status(status_name) values ('ORDER_PAY') |
| dn2 | insert into order_status(status_name) values ('ORDER_PAY') |
| dn3 | insert into order_status(status_name) values ('ORDER_PAY') |
+-----------+------------------------------------------------------------+
3 rows in set (0.00 sec)
在從庫的mysql上查看test_gloabl02的資料:
mysql> use test_global02;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from order_status;
+----+---------------+
| id | status_name |
+----+---------------+
| 1 | ORDER_NOT_PAY |
| 2 | ORDER_PAY |
| 3 | ORDER_FINISH |
+----+---------------+
3 rows in set (0.00 sec)
執行查詢可以看出,查詢時在隨機節點上執行,插入,更新時會把sql陳述句發送到所有分片節點上執行,
mysql> explain select * from order_status;
+-----------+--------------------------------------+
| DATA_NODE | SQL |
+-----------+--------------------------------------+
| dn2 | SELECT * FROM order_status LIMIT 100 |
+-----------+--------------------------------------+
1 row in set (0.00 sec)
mysql> explain select * from order_status;
+-----------+--------------------------------------+
| DATA_NODE | SQL |
+-----------+--------------------------------------+
| dn3 | SELECT * FROM order_status LIMIT 100 |
+-----------+--------------------------------------+
1 row in set (0.00 sec)
mysql> explain select * from order_status;
+-----------+--------------------------------------+
| DATA_NODE | SQL |
+-----------+--------------------------------------+
| dn1 | SELECT * FROM order_status LIMIT 100 |
+-----------+--------------------------------------+
1 row in set (0.01 sec)
3.mycat讀寫分離
1.writeType標簽:有兩個值(0/1),取值決定于 寫/讀寫 的邏輯
? 0:表示當前dataHost接受到分片的讀寫操作中,寫操作,只在第一個writeHost;
? 1:表示隨機的讀寫所有的writeHost和readHost中實作,覆寫balance的邏輯
2.balance標簽:控制一個dataHost中所有的邏輯,一旦writeType=1,就無效了,
? 0:不開啟讀寫分離,直在第一個writeHost執行,其他的readHost,writeHost都不進行讀的操作
? 1:除了第一個writeHost以外的所有writeHost和readHost進行隨機讀取,在高并發時,如果其他節點都高負荷的運轉進行讀操作,也有一部分的讀被分配到第一個writeHost上
? 2:隨機的在所有節點進行讀取
? 3:到所有的readHost當中讀取資料,如果分片中不存在readHost,只會到第一個writeHost上讀取
讀寫分離的測驗,還是在schema.xml里配置,下面是筆者的配置(150是主庫,151、152是從庫):
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts,這里的密碼對應資料庫的密碼 -->
<writeHost host="hostM1" url="192.168.189.150:3306" user="root" password="zj005200..">
<readHost host="hostS2" url="192.168.189.151:3306" user="root" password="zj005200.." />
<readHost host="hostS3" url="192.168.189.152:3306" user="root" password="zj005200.." />
</writeHost>
</dataHost>
執行可以看到,查詢是隨機在兩臺從庫上執行:
mysql> show variables like 'server_id';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 2 |
+---------------+-------+
1 row in set (0.01 sec)
mysql> show variables like 'server_id';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 3 |
+---------------+-------+
1 row in set (0.01 sec)
4.mycat分片規則
? rule屬性:對于一個指定了分片的表格,可以配置rule屬性,根據名稱定義分片的計算規則,
如:schema.xml檔案里配置的:
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
在rule.xml檔案中的:
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>//當前的演算法使用的欄位名稱,如果是不同的,可以在標簽中修改
<algorithm>rang-long</algorithm>//演算法名稱,rang-long指向了函式function標簽
</rule>
</tableRule>
<function name="rang-long" >//class代表執行代碼類
<property name="mapFile">autopartition-long.txt</property>//計算輔助檔案,在conf下有這個檔案
</function>
下面是檔案的內容:
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0 --表示如果資料在0~500萬之間,會插入到第一個分片中(含頭不含尾)
500M-1000M=1 --表示如果資料在500~1000萬之間,會插入到第二個分片中(含頭不含尾)
1000M-1500M=2
自定義分片規則(以城市分片):
schema.xml添加表:
<!--測驗分片規則的表-->
<table name="t_city" dataNode="dn$1-3" rule="sharding-by-intfile-test"/>
rule.xml自定義tableRule:
<!--自定義分片規則-->
<tableRule name="sharding-by-intfile-test">
<rule>
<columns>city</columns>
<algorithm>hash-int-test</algorithm>
</rule>
</tableRule>
<function name="hash-int-test" >
<property name="mapFile">partition-hash-int-test.txt</property>
<!--0:integer 非0表示string-->
<property name="type">1</property>
<!--設定默認節點,默認節點的作用:列舉分片時,如果碰到不識別的列舉值,就讓他進入默認節點,不配置可能會報錯,小于 0 表示不設定默認節點,大于等于 0 設定默認節點-->
<property name="defaultNode">0</property>
</function>
添加一個partition-hash-int-test.txt:
hubei=0
guangdong=1
chongqing=2
DEFAULT_NODE=0
在mysql中創建表:
use test_global01;
CREATE TABLE `t_city` (`id` varchar(20) NOT NULL,`city` varchar(20) NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
use test_global02;
CREATE TABLE `t_city` (`id` varchar(20) NOT NULL,`city` varchar(20) NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
use test_global03;
CREATE TABLE `t_city` (`id` varchar(20) NOT NULL,`city` varchar(20) NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
啟動mycat,并插入資料:
mysql> insert into t_city(id,city) values (database(),'hubei');
Query OK, 1 row affected (0.03 sec)
mysql> insert into t_city(id,city) values (database(),'guangdong');
Query OK, 1 row affected (0.02 sec)
mysql> insert into t_city(id,city) values (database(),'chongqing');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t_city(id,city) values (database(),'hainan');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t_city;
+---------------+-----------+
| id | city |
+---------------+-----------+
| test_global01 | hubei |
| test_global02 | guangdong |
| test_global03 | chongqing |
| test_global01 | hainan |
+---------------+-----------+
4 rows in set (0.00 sec)
如圖所示:上面的插入,將hubei插入第一個分片,guangdong插入第二個分片,chongqing插入第三個分片,同時,hainan則插入到默認節點里,
5.E-R表
由于mycat底層不支持跨分片操作,如果需求中有多個相關的分片表進行關聯操作時,就需要如E-R分片的配置邏輯, 基于E-R關系進行分片,子表的記錄與其父表的記錄保存在同一個分片上,這樣關聯就不需要跨庫進行查詢了,
1.E-R表配置
在schema.xml組態檔中schema標簽中配置customer table 的分庫策略
<!-- ER表配置示例-->
<table name="customer" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id">
<childTable name="order_items" joinKey="order_id" parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id" parentKey="id" />
</table>
<!--如果需要配置多個分片,則需要修改rule.xml中,設定count 多少個分片
<function name="hash-int" >
<property name="mapFile">partition-hash-int.txt</property>
<property name="count">3</property>
</function>-->
配置說明: table標簽表明這是配置表資訊; name = "customer" 說明這張表的名稱叫customer, id 是 主鍵, 表分布在dn1,dn2,dn3這三個資料庫中, 表的分片策略是sharding-by-intfile.
childTable表明子表資訊, 此示例中說明customer關聯了兩張子表,分別是orders,customer_addr;我們以orders表為例說明.
orders表的主鍵是id,它通過joinKey關聯父表的parentKey.本例中orders表就是以customer_id去關聯customer表的id.也就是說,當customer表中id = 1 在dn1時,那么orders表中customer_id = 1這條資料也會在dn1這個資料庫. 這樣設定就避免了跨庫join,提高了查詢效率.
同樣的,order_items表關聯的父表是orders. 原理一樣.
2.E-R表插入資料
# 啟動后,創建表
create table customer(id int not null primary key,name varchar(100),company_id int not null,sharding_id int not null);
create table orders (id int not null primary key ,customer_id int not null,sataus int ,note varchar(100) );
create table order_items (id int not null primary key ,order_id int not null,remark varchar(100) );
# 插入資料
insert into customer (id,name,company_id,sharding_id )values(1,'wang',1,10000);
insert into customer (id,name,company_id,sharding_id )values(2,'xue',2,10010);
insert into customer (id,name,company_id,sharding_id )values(3,'feng',3,10000);
insert into customer (id,name,company_id,sharding_id )values(4,'test',4,10010);
insert into customer (id,name,company_id,sharding_id )values(5,'admin',5,10010);
insert into orders(id,customer_id) values(1,1);
insert into orders(id,customer_id) values(2,2);
insert into orders(id,customer_id,sataus,note) values(3,4,2,'xxxx');
insert into orders(id,customer_id,sataus,note) values(4,5,2,'xxxx');
insert into order_items(id,order_id,remark) VALUES (1,1,'1mark');
insert into order_items(id,order_id,remark) VALUES (2,2,'2mark');
insert into order_items(id,order_id,remark) VALUES (3,3,'3mark');
insert into order_items(id,order_id,remark) VALUES (4,4,'4mark');
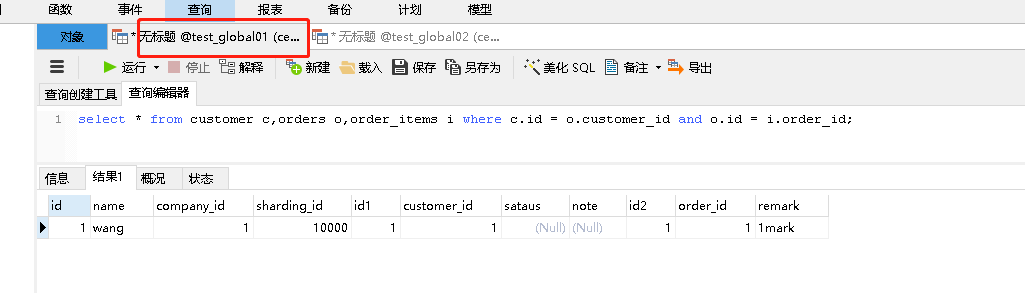
3.E-R表測驗
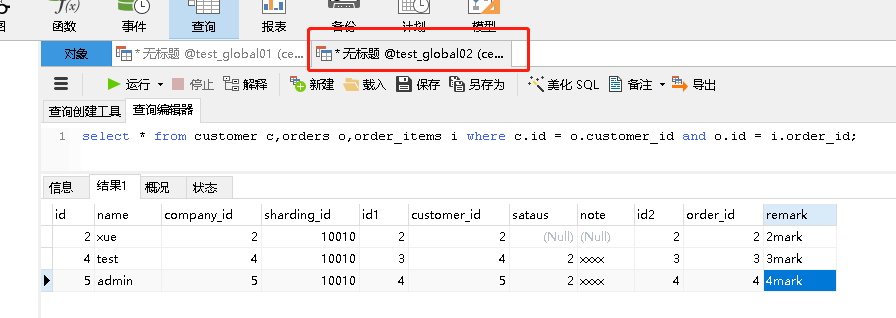
如下圖所示:使用navicat查詢, 基于E-R關系進行分片,子表的記錄與其父表的記錄保存在同一個分片上,這樣關聯就不需要跨庫進行查詢了,
6.HAProxy
筆者使用的環境:
| 服務器名稱 | ip | 作業系統 | 安裝軟體 |
|---|---|---|---|
| mysql-master | 192.168.189.150 | CentOS7.1 | mysql.mycat,keepalived |
| mysql-slave1 | 192.168.189.151 | CentOS7.1 | mysql.mycat,haproxy,keepalived |
| mysql-slave2 | 192.168.189.152 | CentOS7.1 | mysql.mycat,keepalived |
1.HAProxy介紹
- HAProxy 是一款提供高可用性、負載均衡以及基于TCP和HTTP應用的代理軟體,支持虛擬主機,它是免費、快速并且可靠的一種解決方案,
- HAProxy 實作了一種事件驅動、單一行程模型,此模型支持非常大的并發連接數,
- HAProxy支持連接拒絕 : 因為維護一個連接的打開的開銷是很低的,有時我們很需要限制攻擊爬蟲,也就是說限制它們的連接打開從而限制它們的危害,
- HAProxy 支持全透明代理:可以用客戶端IP地址或者任何其他地址來連接后端服務器,這個特性僅在Linux 2.4/2.6內核打了cttproxy補丁后才可以使用.
2. HAProxy特性
- 可靠性與穩定性都非常出色,可與硬體級設備媲美
- 支持連接拒絕,可以用于防止DoS攻擊
- 支持長連接、短連接和日志功能,可根據需要靈活配置
- 路由 HTTP 請求到后端服務器,基于cookie作會話系結;同時支持通過獲取指定的 url 來檢測后端服務器的狀態
- HAProxy 還擁有功能強大的 ACL 支持,可靈活配置路由功能,實作動靜分離,在架構設計與實作上帶來很大方便
- 可支持四層和七層負載均衡,幾乎能為所有服務常見的提供負載均衡功能
- 擁有功能強大的后端服務器的狀態監控 web 頁面,可以實時了解設備的運行狀態 ,還可實作設備上下線等簡單操作,
- 支持多種負載均衡調度演算法,并且也支持 session 保持,
- Haproxy 七層負載均衡模式下,負載均衡與客戶端及后端的服務器會分別建立一次TCP連接,而在四層負載均衡模式下(DR),僅建立一次 TCP 連接;七層負載均衡對負載均衡設備的要求更高,處理能力也低于四層負載均衡
3.HAProxy安裝
? HAProxy的安裝非常簡單:yum install -y haproxy
? 查看安裝的haproxy: rpm -qi haproxy
? 安裝完成后的目錄:cd /usr/sbin
? 組態檔的目錄:cd /etc/haproxy/
4.HAProxy組態檔
? 1.HAProxy的組態檔由兩部分構成:
? 全域設定(global settings):主要用于定義HAProxy行程管理安全及性能相關的引數
? 對代理的設定(proxies):共分為4段(defaults,frontend,backend,listen)
? defaults:為除了global以外的其他配置段提供默認引數,默認配置引數可由下一個defaults重新設定
frontend:定義一系列監聽的套接字,這些套接字可接受客戶端請求并與之建立連接
backend:定義“后端”服務器,前端代理服務器將會把客戶端的請求調度至這些服務器
listen:定義監聽的套接字和后端的服務器,類似于將frontend和backend段放在一起,通常只對TCP流量有用, 所有代理的名稱只能使用大寫字母、小寫字母、數字、-(中線)、_(下劃線)、.(點號)、:(冒號),并且ACL區分字母大小寫
配置haproxy組態檔,目錄:/etc/haproxy/haproxy.cfg
這里筆者把自己已經配置好的的組態檔貼出來:
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode tcp
log global
option tcplog
option dontlognull
option http-server-close
#option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend mycat
bind 0.0.0.0:8066
mode tcp
log global
default_backend mycat_server
#---------------------------------------------------------------------
# static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
backend mycat_server
balance roundrobin
server mycat1 192.168.189.151:8066 check inter 5s rise 2 fall 3
server mycat2 192.168.189.152:8066 check inter 5s rise 2 fall 3
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
listen stats
mode http
bind 0.0.0.0:1080
stats enable
stats hide-version
stats uri /Haproxyadmin?stats
stats realm Haproxy\ Statistics
stats auth admin:admin
stats admin if TRUE
在這里解釋一下三個配置:
#option forwardfor except 127.0.0.0/8 --如果后端服務器需要獲取真實ip,就需要配置的引數
balance roundrobin --負載方式:輪詢
server mycat1 192.168.189.151:8066(mycat的ip和埠) check inter 5s(檢測心跳時間) rise 2 fall 3(失敗重連次數)
5.啟動haproxy負載均衡器
/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg
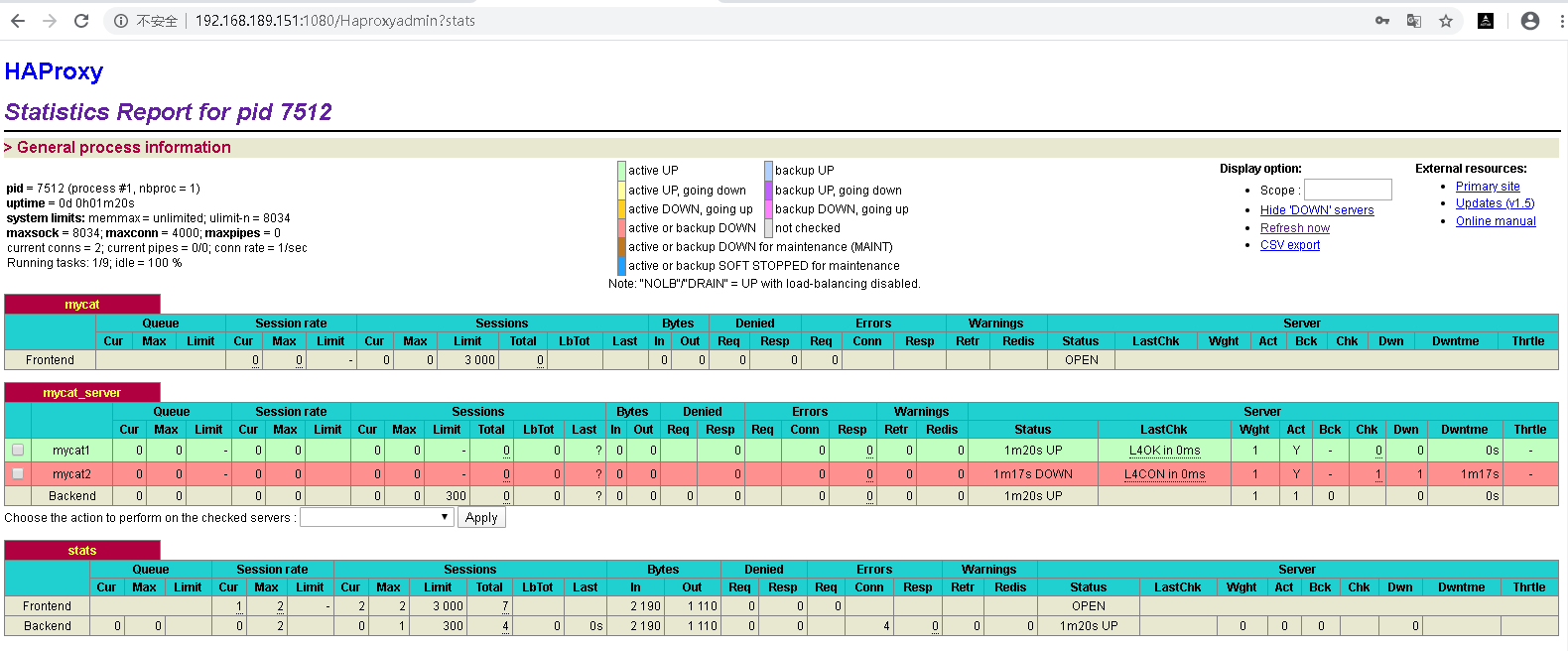
查看行程,如果看到如下則提示配置成功:
[root@localhost haproxy]# ps -ef|grep haproxy
haproxy 7512 1 0 09:02 ? 00:00:00 /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg
root 7516 7393 0 09:02 pts/0 00:00:00 grep --color=auto haproxy
關閉防火墻:
systemctl stop firewalld
在瀏覽器上訪問(連接地址:http://192.168.189.151:1080/Haproxyadmin?stats 賬號/密碼:上面listen中配置的admin/admin),如果看到如下頁面,就表示已經成功:
7.mycat負載均衡集群
1.靜態負載均衡演算法包括:輪詢,比率,優先權
? 輪詢:順序回圈將請求依次順序回圈地連接每個服務器,當其中某個服務器發生第二到第7層的故障,BIG-IP就把其從順序回圈佇列中拿出,不參加下一次的輪詢,直到其恢復正常,
? 比率:給每個服務器分配一個加權值為比例,根椐這個比例,把用戶的請求分配到每個服務器,當其中某個服務器發生第二到第7層的故障,BIG-IP 就把其從服務器佇列中拿出,不參加下一次的用戶請求的分配, 直到其恢復正常,
? 優先權:給所有服務器分組,給每個組定義優先權,BIG-IP 用戶的請求,分配給優先級最高的服務器組;當最高優先級中所有服務器出現故障,BIG-IP 才將請求送給次優先級的服務器組,這種方式,實際為用戶提供一種熱備份的方式,
2.負載均衡的優勢
? (1)高性能:負載均衡技術將業務較均衡的分擔到多臺設備或鏈路上,從而提高了整個系統的性能;
? (2)可擴展性:負載均衡技術可以方便的增加集群中設備或鏈路的數量,在不降低業務質量的前提下滿足不斷增長的業務需求;
? (3)高可靠性:單個甚至多個設備或鏈路出現故障也不會導致業務中斷,提高了整個系統的可靠性;
? (4)可管理性:大量的管理共組都集中在使用負載均衡技術的設備上,設備集群或鏈路集群只需要維護通過的配置即可;
? (5)透明性:對用戶而言,集群等于一個或多個高可靠性、高性能的設備或鏈路,用戶感知不到,也不關心具體的網路結構,增加或減少設備或鏈路數量都不會影響正常的業務,
8.keepalived
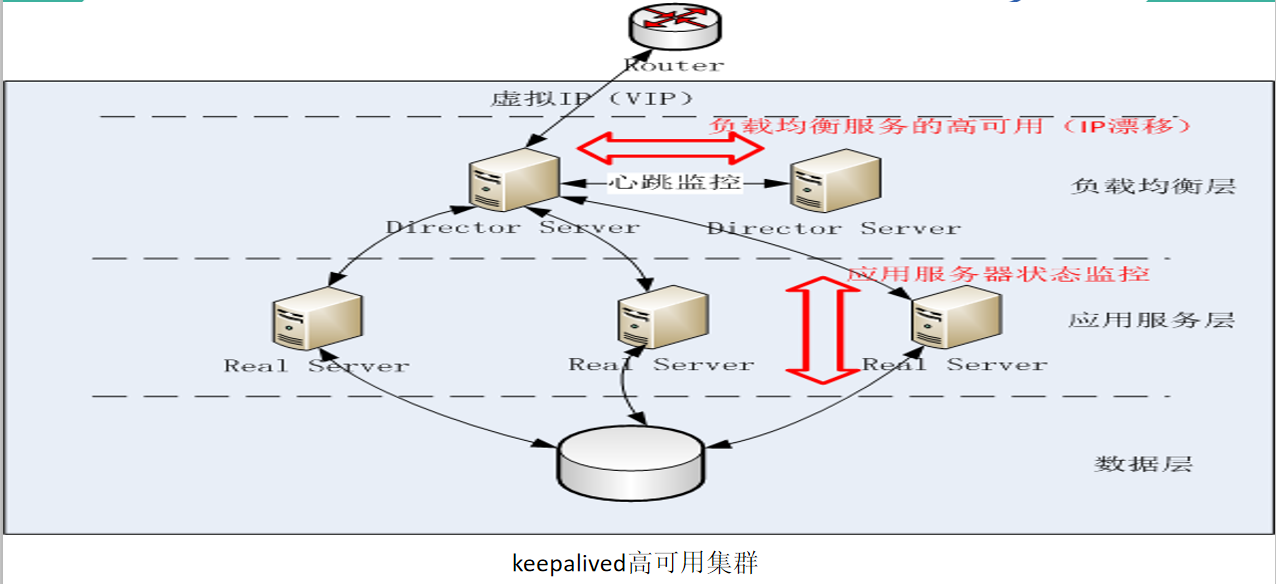
1.keepalived概念
? keepalived,保持存活,就是高可用設備或熱備用來防止單點故障的發生,keepalived通過請求一個vip來達到請求真實ipi地址的功能,而vip能夠在一臺機器發生故障的時候,自動漂移到另外一臺機器上,從來達到了高可用HAProxy的功能,
2.keepalived的功能
- 通過ip漂移
- 對HAProxy應用層的應用服務器集群進行狀態監控
3.keepalived原理
? keepalived的實作基于VRRP實作的保證集群高可用的一個服務軟體,主要功能是實作真機的故障隔離和負載均衡器間的失敗切換,防止單點故障,
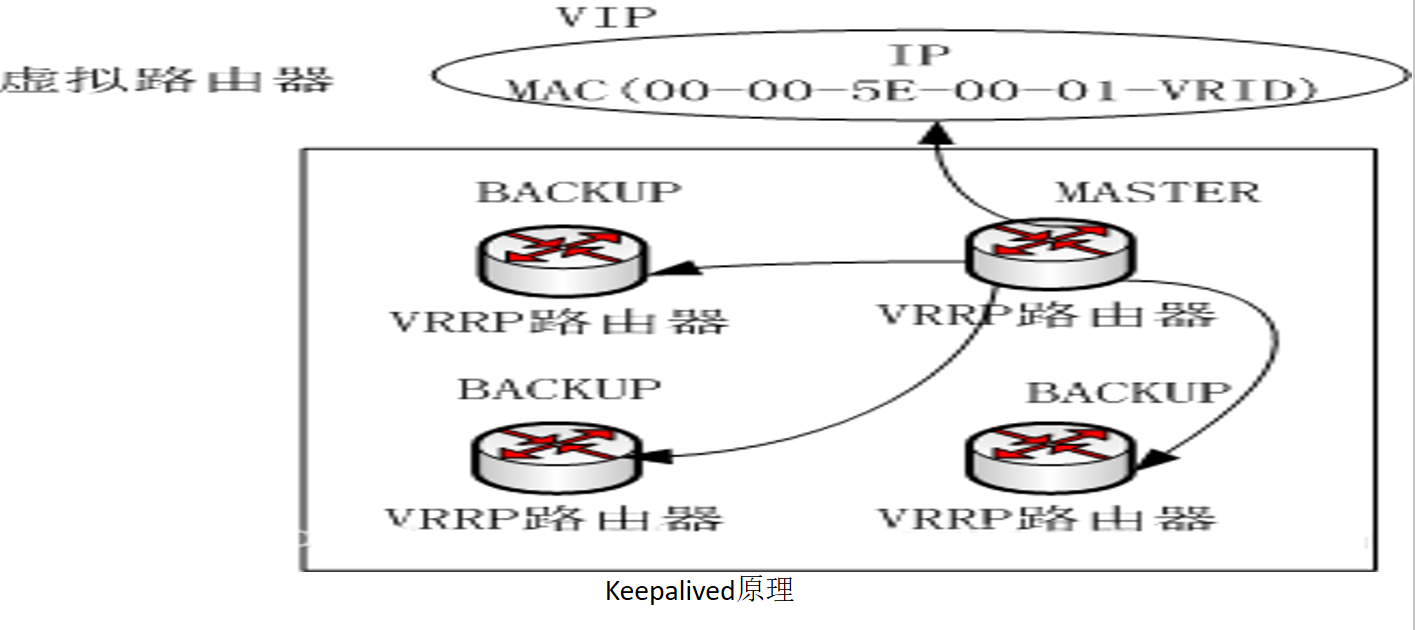
VRRP協議:Virtual Route Redundancy Protocol虛擬路由冗余協議,是一種容錯協議,保證當主機的下一跳路由出現故障時,由另一臺路由器來代替出現故障的路由器進行作業,從而保持網路通信的連續性和可靠性,在介紹VRRP之前先介紹一些關于VRRP的相關術語:
虛擬路由器:由一個 Master 路由器和多個 Backup 路由器組成,主機將虛擬路由器當作默認網關,
VRID:虛擬路由器的標識,有相同 VRID 的一組路由器構成一個虛擬路由器,
Master 路由器:虛擬路由器中承擔報文轉發任務的路由器,
Backup 路由器: Master 路由器出現故障時,能夠代替 Master 路由器作業的路由器,
虛擬 IP 地址:虛擬路由器的 IP 地址,一個虛擬路由器可以擁有一個或多個IP 地址,
IP 地址擁有者:介面 IP 地址與虛擬 IP 地址相同的路由器被稱為 IP 地址擁有者,
虛擬 MAC 地址:一個虛擬路由器擁有一個虛擬 MAC 地址,虛擬 MAC 地址的格式為 00-00-5E-00-01-{VRID},通常情況下,虛擬路由器回應 ARP 請求使用的是虛擬 MAC 地址,只有虛擬路由器做特殊配置的時候,才回應介面的真實 MAC 地址,
優先級: VRRP 根據優先級來確定虛擬路由器中每臺路由器的地位,
非搶占方式:如果 Backup 路由器作業在非搶占方式下,則只要 Master 路由器沒有出現故障,Backup 路由器即使隨后被配置了更高的優先級也不會成為Master 路由器,
搶占方式:如果 Backup 路由器作業在搶占方式下,當它收到 VRRP 報文后,會將自己的優先級與通告報文中的優先級進行比較,如果自己的優先級比當前的 Master 路由器的優先級高,就會主動搶占成為 Master 路由器;否則,將保持 Backup 狀態,
4.keepalived組件
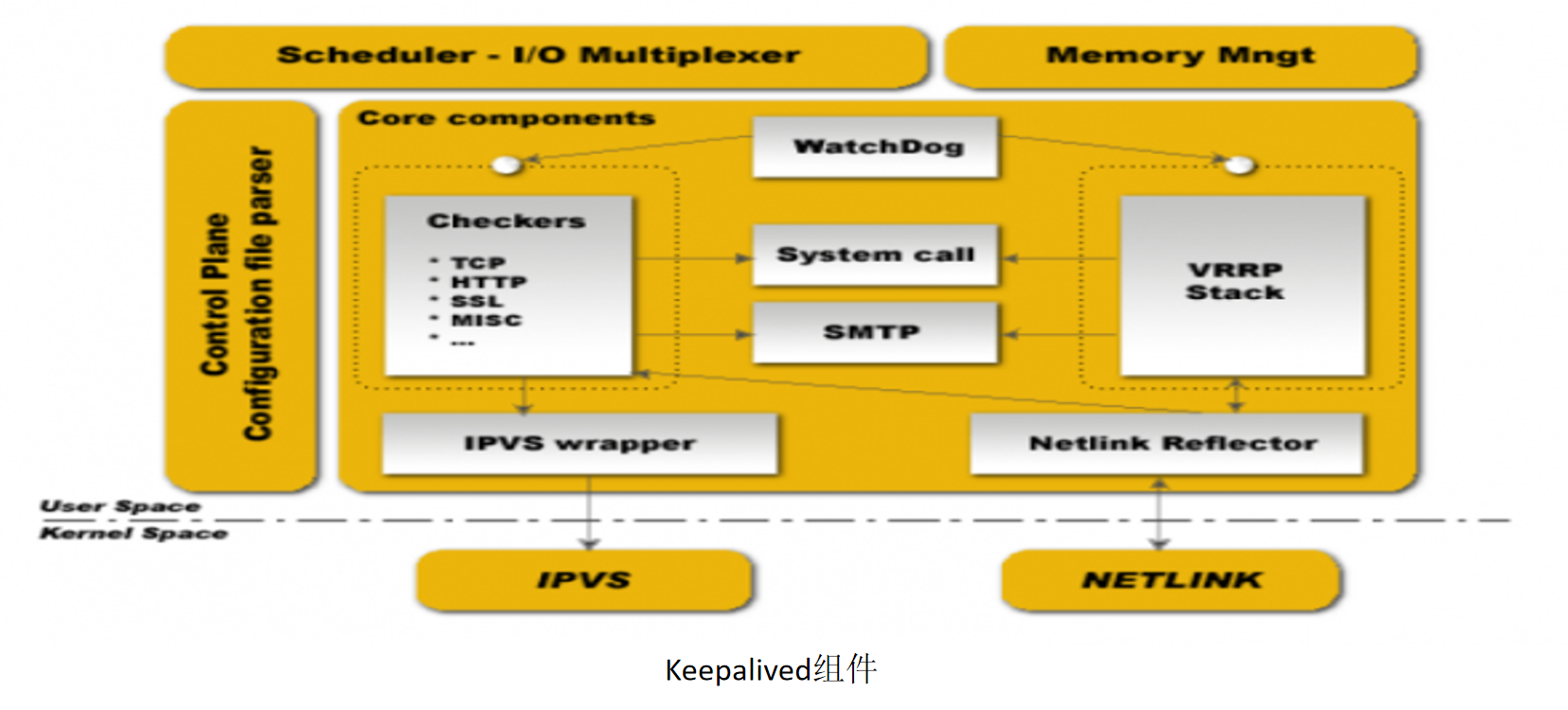
keepalived是模塊化設計,不同模塊負責不同的功能,core模塊為keepalived的核心,負責主行程的啟動、維護以及全域組態檔的加載和決議,checkers負責健康檢查,包括常見的各種檢查方式,VRRP模塊是來實作VRRP協議的,
5.keepalived配置
1.解壓并安裝(安裝keepalived 需要用到 openssl):
cd /home
# 安裝環境依賴
yum install gcc gcc-c++ openssl openssl-devel
# 如果沒有安裝過wget, yum install wget 安裝
wget -q https://www.keepalived.org/software/keepalived-1.2.18.tar.gz
# ls查看是否安裝了 keepalived-1.2.18.tar.gz
tar -zxvf keepalived-1.2.18.tar.gz
cd keepalived-1.2.18
# 監測
./configure --prefix=/usr/local/keepalived-1.2.18/
# 編譯安裝
make && make install
2.將keepalived安裝成Linux服務
# 因為沒有使用keepalived的默認路徑安裝(默認是/usr/local),安裝后,需要復制默認組態檔到默認路徑下
mkdir /etc/keepalived
cp /usr/local/keepalived-1.2.18/etc/keepalived/keepalived.conf /etc/keepalived/
# 將初始化檔案復制到etc里
cp /usr/local/keepalived-1.2.18/etc/rc.d/init.d/keepalived /etc/init.d
# 將組態檔復制到etc里
cp /usr/local/keepalived-1.2.18/etc/sysconfig/keepalived /etc/sysconfig
# 軟連接
ln -s /usr/local/keepalived-1.2.18/sbin/keepalived /usr/sbin/
# 將keepalived設定為開機啟動
chkconfig keepalived on
3.keepalived組態檔
cd /etc/keepalived/
# 修改組態檔,建議下載下來修改
vi keepalived.conf
# 下面是主keepalived.conf的組態檔
! Configuration File for keepalived
global_defs { # 全域配置標識,表明這個區域是全域配置
router_id LVS_MASTER
}
vrrp_sync_group VG1 {
group {
VI_1
}
}
# keepalived會去檢測負載均衡器,所以要設定一個腳本,讓他自己去檢測
vrrp_script chk_haproxy {
# 檢測haproxy狀態的腳本路徑
script "/etc/keepalived/haproxy_check.sh"
# 檢測間隔時間
interval 2
# 如果條件成立,權重+2,反之 -2
weight 2
}
# 定義一種虛擬路由協議,即vrrp,一個vrrp_instance 定義一個虛擬路由器,VI_1實體名
vrrp_instance VI_1 {
# 定義初始狀態,樂意是master或者backup(備份)
state MASTER
# 作業介面,通告選舉使用哪個介面進行,使用ip addr查看
interface ens33
# 虛擬路由id,如果是一組,則定義一個id,如果是多組,則定義多個
virtual_router_id 51
# 優先級策略選擇引數
priority 100
# 通告頻率單位是s
advert_int 1
# 通信認證機制
authentication {
auth_type PASS
auth_pass 1111
}
# 虛擬路由ip網段不一樣,設定自己的網段+ip
virtual_ipaddress {
192.168.189.100
}
# 檢測腳本 對應的是vrrp_script chk_haproxy 負載均衡器
track_script{
chk_haproxy
}
}
# 從keepalived.conf的組態檔:
global_defs {
#備用
router_id LVS_BACKUP
}
vrrp_sync_group VG1 {
group {
VI_1
}
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh"
interval 2
weight 2
}
vrrp_instance VI_1 {
# 狀態為備用的狀態
state BACKUP
interface ens33
virtual_router_id 51
# 優先級不能高于主
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.189.100
}
track_script{
chk_haproxy
}
}
4.keepalived檢測腳本
#!/bin/bash
START_HAPROXY="/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg" LOG_FILE="/usr/local/keepalived/log/haproxy-check.log" # 日志檔案,會新建一個日志檔案
HAPS=`ps -C haproxy --no-header |wc -l` # 檢測狀態,0表示未啟動,1表示啟動
date "+%Y-%m-%d %H:%M:%S" >> $LOG_FILE # 記錄時間
echo "check haproxy status" >> $LOG_FILE # 記錄狀態
if [ $HAPS -eq 0 ];then
echo $START_HAPROXY >> $LOG_FILE # 記錄啟動命令
/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg #啟動haproxy
sleep 3 #啟動之后進行睡眠,3s后再進行判斷是否已經成功啟動,如果沒有啟動就把keepalived服務關掉,換成備份的服務
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
echo "start haproxy failed, killall keepalived" >> $LOG_FILE
killall keepalived
service keepalived stop
fi
fi
5.給腳本賦值權限
chmod +x /etc/keepalived/haproxy_check.sh
# 創建日志目錄
mkdir /usr/local/keepalived/log
6.keepalived相關程式:
service keepalived start # 啟動
service keepalived stop # 停止
service keepalived restart # 重啟
service keepalived status # 查看keepalived狀態
7.演示ip漂移
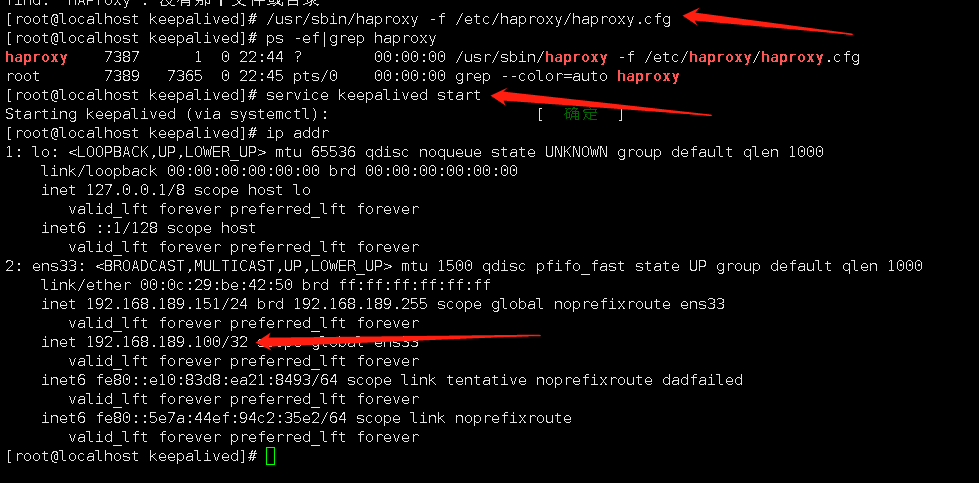
# 在從1上啟動haproxy
[root@localhost keepalived]# /usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg
# 啟動keepalived服務
[root@localhost keepalived]# service keepalived start
# ip addr 查看ip可以看到主keepalived的虛擬ip已經生效了
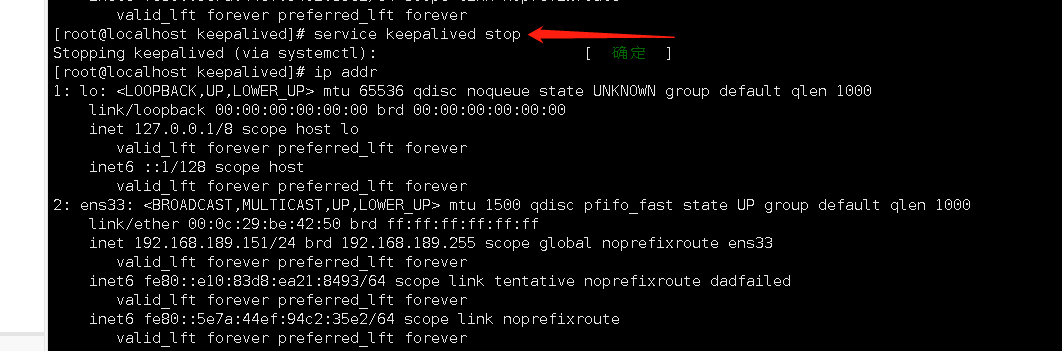
# 關閉主虛擬機上的keepalived,可以看到在主虛擬機上的虛擬ip已經沒有了,同時在虛擬ip已經飄到152這臺虛擬機上了
[root@localhost keepalived]# service keepalived stop
# 開啟主虛擬機上的keepalived,ip將重新回到主虛擬機上
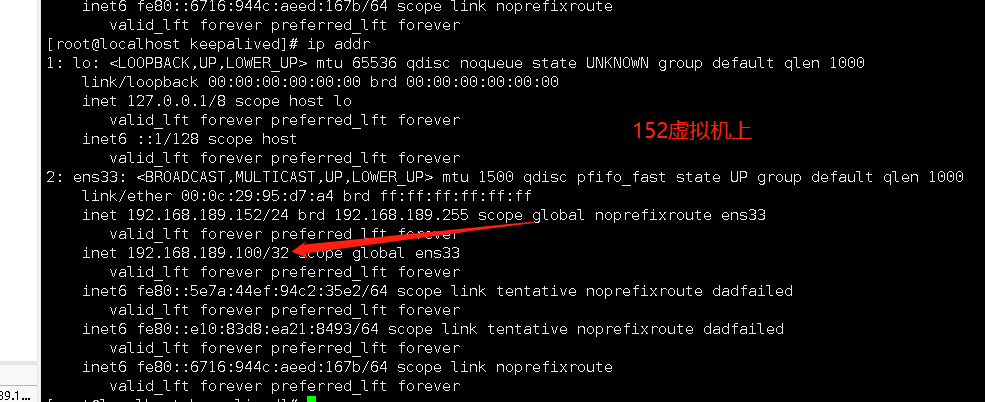
8.演示Keepalived 重新啟動haproxy
關閉haproxy,可以看到,keepalived把haproxy重啟了,
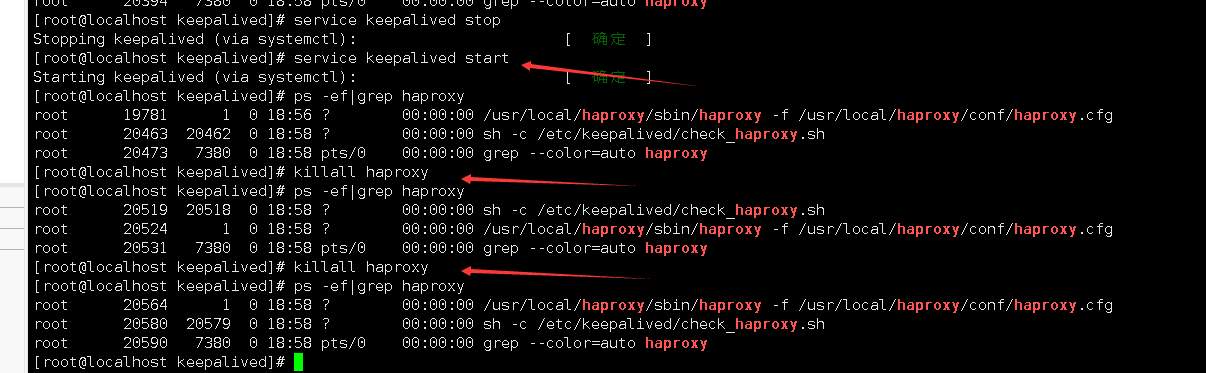
卸載keepalived和haproxy
卸載haproxy
yum remove haproxy
# 通過yum安裝的
yum remove keepalived
# 通過原始碼包安裝的
[root@localhost keepalived]# cd /home/keepalived-1.2.18
[root@localhost keepalived-1.2.18]# make uninstall
[root@localhost keepalived-1.2.18]# cd ../
[root@localhost home]# rm -rf keepalived-1.2.18
[root@localhost home]# rm -rf keepalived-1.2.18.tar.gz
[root@localhost home]# cd /etc
[root@localhost etc]# rm -rf keepalived
[root@localhost etc]# cd /usr/local
[root@localhost local]# rm -rf keepalived
[root@localhost local]# rm -rf keepalived-1.2.18/
# 驗證
[root@localhost etc]# serive keepalived satrt
-bash: serive: 未找到命令
[root@localhost etc]# systemctl start keepalived
Job for keepalived.service failed because the control process exited with error code. See "systemctl status keepalived.service" and "journalctl -xe" for details.
參考文章:
https://www.cnblogs.com/z-qinfeng/p/9726707.html
https://blog.csdn.net/bbwangj/article/details/82763431
https://blog.csdn.net/l1028386804/article/details/76397064
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/228271.html
標籤:Linux
上一篇:服務器重新部署踩坑記