本章主要研究了計算機中無符號數,補碼,浮點數的編碼方式,通過研究數字的實際編碼方式,我們能夠了解計算機中不同型別的資料可表示的值的范圍,不同算術運算的屬性,可以知道計算機是如何處理資料溢位的,了解計算機的編碼方式,對于我們寫出可以跨越不同機器,不同作業系統和編譯器組合的代碼具有重要的幫助,
@
目錄- 資訊存盤
- 為什么會有二進制?二進制有什么含義和優勢?
- 計算機的三種編碼方式
- 整數&浮點數
- 虛擬記憶體&虛擬地址空間
- 二進制&十進制&十六進制
- 二進制轉十六進制(分組轉換)
- 十進制轉十六進制
- 虛擬地址的范圍
- C語言基本資料型別的典型大小(位元組為單位)
- 大端&小端
- 擴展:大小端有什么意義?
- 位運算子&邏輯運算子
- 邏輯左移和算術左移
- 擴展:當移動位數大于實際位數時該怎么辦?
- 整數表示
- 無符號數的編碼
- 補碼的編碼
- 關于補碼需要注意的地方
- 確定資料型別的大小
- 無符號數和補碼的相互轉化
- 有符號數與無符號數的轉換
- 擴展數字
- 截斷數字
- 小結
- 整數運算
- 無符號數加法
- 補碼加法
- 補碼的非
- 無符號數的乘法
- 補碼的乘法
- 常數與符號數的乘法
- 常數與符號數的除法
- 無符號數的除法
- 補碼的除法(向下舍入)
- 補碼的除法(向上舍入)
- 總結
- 浮點數
- 二進制小數
- IEEE浮點表示
- 浮點數的運算規則
- 整數和浮點數相乘
- 兩個浮點數相乘
- 兩個浮點數相加
- 浮點數的偶數舍入
- 注意
- C語言中的浮點數
- 總結
資訊存盤
為什么會有二進制?二進制有什么含義和優勢?
??對于有10個手指的人類來說,使用十進制表示法是很自然的事情,但是當構造存盤和處理資訊的機器時,二進制值作業得更好,二值信號能夠很容易地被表示、存盤和傳輸,例如,可以表示為穿孔卡片上有洞或無洞、導線上的高電壓或低電壓,或者順時針或逆時針的磁場,對二值信號進行存盤和執行計算的電子電路非常簡單和可靠,制造商能夠在一個單獨的硅片上集成數百萬甚至數十億個這樣的電路,孤立地講,單個的位不是非常有用,然而,當把位組合在一起,再加上某種解釋,即賦予不同的可能位模式以含意,我們就能夠表示任何有限集合的元素,比如,使用一個二進制數字系統,我們能夠用位組來編碼非負數,通過使用標準的字符碼我們能夠對檔案中的字母和符號進行編碼,
計算機的三種編碼方式
??無符號:無符號(unsigned)編碼基于傳統的二進制表示法,表示大于或者等于零的數字,
??補碼:補碼(two' s-complement)編碼是表示有符號整數的最常見的方式,有符號整數就是可以為正或者為負的數字,
??浮點數:浮點數( floating-point)編碼是表示實數的科學記數法的以2為基數的版本,
整數&浮點數
??在計算機中,整數的運算子合運算子的交換律和結合律,溢位的結果會表示為負數,整數的編碼范圍比較小,但是其結果表示是精確的,
??浮點數的運算是不可結合的,并且其溢位會產生特殊的值——正無窮,浮點數的編碼范圍大,但是其結果表示是近似的,
??造成上述不同的原因主要是因為計算機對于整數和浮點數的編碼格式不同,
虛擬記憶體&虛擬地址空間
??大多數計算機使用8位的塊,或者位元組(byte),作為最小的可尋址的記憶體單位,而不是訪問記憶體中單獨的位,機器級程式將記憶體視為一個非常大的位元組陣列,稱為虛擬記憶體( virtual memory),記憶體的每個位元組都由一個唯一的數字來標識,稱為它的地址(address),所有可能地址的集合就稱為虛擬地址空間( virtual address space),
??指標是由資料型別和指標值構成的,它的值表示某個物件的位置,而它的型別表示那個位置上所存盤物件的型別(比如整數或者浮點數),C語言中任何一個型別的指標值對應的都是一個虛擬地址,C語言編譯器可以根據不同型別的指標值生成不同的機器碼來訪問存盤在指標所指向位置處的值,但是它生成的實際機器級程式并不包含關于資料型別的資訊,
二進制&十進制&十六進制
二進制轉十六進制(分組轉換)
??四位二進制可以表示一位十六進制,二進制和十六進制的互相轉換方法如下表所示,這里就不展開講解了,
| 十六進制 | 1 | 7 | 3 | A | 4 | C |
|---|---|---|---|---|---|---|
| 二進制 | 0001 | 0111 | 0011 | 1010 | 0100 | 1100 |
十進制轉十六進制
Gamma公式展示 \(\Gamma(n) = (n-1)!\quad\forall n\in\mathbb N\) 是通過 Euler integral
??設x為2的非負整數n次冪時,也就是\(x = {2^n}\),我們可以很容易地將x寫成十六進制形式,只要記住x的二進制表示就是1后面跟n個0(比如
\(1024 = {2^{10}}\),二進制為10000000000),十六進制數字0代表4個二進制0,所以,當n表示成i+4j的形式,其中0≤i≤3,我們可以把x寫成開頭的十六進制數字為1(i=0)、2(i=1)、4(i=2)或者8(i=3),后面跟隨著j個十六進制的0,比如,\(2048 = {2^{11}}\),我們有n=11=3+4*2,從而得到十六進制表示為0x800,下面再看幾個例子,
| n | \({2^{n}}\)(十進制) | \({2^{n}}\)(十六進制) |
|---|---|---|
| 9 | 512 | 0x200 |
| 19(3+4*4) | 524288 | 0x80000 |
| 14(2+4*2) | 16384 | 0x4000 |
| 16(0+4*4) | 65536 | 0x10000 |
| 17(1+4*4) | 131072 | 0x20000 |
| 5(1+4*1) | 32 | 0x20 |
| 7(3+4*1) | 128 | 0x80 |
??十進制轉十六進制還可以使用另一種方法:輾轉相除法,反過來,十六進制轉十進制可以用相應的16的冪乘以每個十六進制數字,
虛擬地址的范圍
??每臺計算機都有一個字長( word size),指明指標資料的標稱大小( nominal size),因為虛擬地址是以這樣的一個字來編碼的,所以字長決定的最重要的系統引數就是虛擬地址空間的最大大小,也就是說,對于一個字長為w位的機器而言,虛擬地址的范圍為0~\({2^{w}}\)-1 ,程式最多訪問\({2^{w}}\)個位元組,
16位字長機器的地址范圍:0~65535(FFFF)
32位字長機器的地址范圍:0~4294967296(FFFFFFFF,4GB)
64位字長機器的地址范圍:0~18446744073709551616(1999999999999998,16EB)
32位編譯指令:gcc -m32 main.c
64位編譯指令:gcc -m64 main.c
C語言基本資料型別的典型大小(位元組為單位)
| 有符號 | 無符號 | 32位 | 64位 |
|---|---|---|---|
| [signed] char | unsigned char | 1 | 1 |
| short | unsigned short | 2 | 2 |
| int | unsigned int | 4 | 4 |
| long | unsigned long | 4 | 8 |
| int32_t | uint32_t | 4 | 4 |
| int64_t | uint64_t | 8 | 8 |
| char* | 4 | 8 | |
| float | 4 | 4 | |
| double | 8 | 8 |
??注意:基本C資料型別的典型大小分配的位元組數是由編譯器如何編譯所決定的,并不是由機器位數而決定的,本表給出的是32位和64位程式的典型值,
??為了避免由于依賴“典型”大小和不同編譯器設定帶來的奇怪行為,ISOC99引入了類資料型別,其資料大小是固定的,不隨編譯器和機器設定而變化,其中就有資料型別int32_t和int64_t,它們分別為4個位元組和8個位元組,使用確定大小的整數型別是程式員準確控制資料表示的最佳途徑,
??對關鍵字的順序以及包括還是省略可選關鍵字來說,C語言允許存在多種形式,比如,下面所有的宣告都是一個意思:
unsigned long
unsigned long int
long unsigned
long unsigned int
大端&小端
??大端:是指資料的高位元組保存在記憶體的低地址中,而資料的低位元組保存在記憶體的高地址中,這樣的存盤模式有點兒類似于把資料當作字串順序處理:地址由小向大增加,而資料從高位往低位放,
??小端:是指資料的高位元組保存在記憶體的高地址中,而資料的低位元組保存在記憶體的低地址中,這種存盤模式將地址的高低和資料位權有效地結合起來,高地址部分權值高,低地址部分權值低,和我們的邏輯方法一致,
??舉個例子,假設變數x的型別為int,位于地址0x100處,它的十六進制值為0x01234567,地址范圍0x100~0x103的位元組順序依賴于機器的型別,
大端法
| 地址 | 0x100 | 0x101 | 0x102 | 0x103 |
|---|---|---|---|---|
| 資料 | 01 | 23 | 45 | 67 |
小端法
| 地址 | 0x100 | 0x101 | 0x102 | 0x103 |
|---|---|---|---|---|
| 資料 | 67 | 45 | 23 | 01 |
注意,在字0x01234567中,高位位元組的十六進制值為0x01,而低位位元組值為0x67,
記憶方式:
大端==高尾端,即尾端(67)放在高地址(0x103),
小端==低尾端,即尾端(67)放在低地址(0x100),
擴展:大小端有什么意義?
1.不同設備的資料傳輸
??A設備為小端模式,B設備為大端模式,當通過網路將A設備的資料傳輸到B設備時,就會出現問題,(B設備如何轉換A設備的資料將在后面章節講解)
2.閱讀反匯編代碼
??假設Intel x86-64(x86都屬于小端)生成某段程式的反匯編碼如下:
4004d3:01 05 43 0b 20 00 add %eax,0x200b43(%rip)
??這條指令是把一個字長的資料加到一個值上,該值的存盤地址由0x200b43加上當前程式計數器的值得到,當前程式計數器的值即為下一條將要執行指令的地址,
??我們習慣的閱讀順序為最低位在左邊,最高位在右邊,0x00200b43,而小端模式生成的反匯編碼最低位在右邊,最高位在左邊,01 05 43 0b 20 00.和我們的閱讀順序正好相反,
3.撰寫符合各種系統的通用程式
/*列印程式物件的位元組表示,這段代碼使用強制型別轉換來規避型別系統,很容易定義針對其他資料型別的類似函式*/
#include <stdio.h>
typedef unsigned char* byte_pointer;
/*傳遞給 show_bytes一個指向它們引數x的指標&x,且這個指標被強制型別轉換為“unsigned char*”,這種強制型別轉換告訴編譯器,程式應該把這個指標看成指向一個位元組序列,而不是指向一個原始資料型別的物件,*/
void show_bytes(byte_pointer start, size_t len){
size-t i;
for (i=0;i<len;i++)
printf("%.2x",start [i]);
printf("\n");
}
void show_int (int x){
show_bytes ((byte_pointer)&x,sizeof(int));
}
void show_float (float x){
show_bytes ((byte_pointer)&x,sizeof(float));
}
void show_pointer (void* x){
show_bytes ((byte_pointer)&x,sizeof(void* x));
}
void test_show_bytes (int val){
int ival = val;
float fval =(float)ival;
int *pval = &ival;
show_int(ival);
show_float(fval);
show_pointer(pval);
}
??以上代碼列印示例資料物件的位元組表示如下表:
| 機器 | 值 | 型別 | 位元組(十六進制) |
|---|---|---|---|
| Linux32 | 12345 | int | 39 30 00 00 |
| Windows | 12345 | int | 39 30 00 00 |
| Linux64 | 12345 | int | 39 30 00 00 |
| Linux32 | 12345.0 | float | 00 e4 40 46 |
| Windows | 12345.0 | float | 00 e4 40 46 |
| Linux64 | 12345.0 | float | 00 e4 40 46 |
| Linux32 | &ival | int * | e4 f9 ff bf |
| Windows | &ival | int * | b4 cc 22 00 |
| Linux64 | &ival | int * | b8 11 e5 ff ff 7f 00 00 |
??注:Linux64為x86-64處理器,
??除了位元組順序以外,int和 float的結果是一樣的,指標值與機器型別相關,引數12345的十六進制表示為0x00003039,對于int型別的資料,除了位元組順序以外,我們在所有機器上都得到相同的結果,此外,指標值卻是完全不同的,不同的機器/作業系統配置使用不同的存盤分配規則,( Linux32、 Windows機器使用4位元組地址,而 Linux64使用8位元組地址)
??可以觀察到,盡管浮點型和整型資料都是對數值12345編碼,但是它們有截然不同的位元組模式:整型為0x00003039,而浮點數為0x4640E400,一般而言,這兩種格式使用不同的編碼方法,
位運算子&邏輯運算子
??位運算子:& | ~ ^,邏輯運算子:&& || !,特別要 ~ 和!的區別,看下面的例子,
| 運算式 | 結果 |
|---|---|
| !0x41 | 0x00 |
| !!0x41 | 0x01 |
| !0x00 | 0x01 |
| ~0x41 | 0x3E |
| ~0x00 | 0xff |
??“!”邏輯非運算子,邏輯運算子一般將其運算元視為條件運算式,回傳結果為Bool型別:“!true”表示條件為真(true),“!false ”表示條件為假(false),
??"~"位運算子,代表位的取反,對于整形變數,對每一個二進制位進行取反,0變1,1變0,
^為異或運算子,有一個重要的性質:a ^ a = 0,a ^ 0= a,即任何數和其自身異或結果為0,和0異或結果仍為原來的數,利用這個性質,我們可以找出陣列中只出現一次/兩次/三次等的數字,如何找呢?
例1:假設給定一個陣列 arr,除了某個元素只出現一次以外,其余每個元素均出現兩次,找出那個只出現了一次的元素,
思路:其余元素出現了都是兩次,因此,將陣列內的所有元素依次異或,最后的結果即為只出現一次的元素,比如,arr = [0,0,1,1,8,8,12],0 ^ 0 ^ 1 ^ 1^ 8^ 8^ 12 = 12, 感興趣的可以自己編程試下,
例2:給定一個整數陣列 arr,其中恰好有兩個元素只出現一次,其余所有元素均出現兩次, 找出只出現一次的那兩個元素,
思路:首先可以通過異或獲得兩個出現一次的數字的異或值,該異或值中的為1的bit位肯定是來自這兩個數字之中的一個,然后可以隨便選一個為1的bit位,按照這個bit位,將所有該位為1的數字分為一組,所有該位為0的數字分為一組,這樣就成了查找兩個子陣列中只出現了一次的數字,
例3:假設給定一個陣列 arr,除了某個元素只出現一次以外,其余每個元素均出現了三次,找出那個只出現了一次的元素,
思路:可以自己考慮下,
??邏輯運算子&& 和||還有一個短路求值的性質,具體如下,
??如果對第一個引數求值就能確定運算式的結果,那么邏輯運算子就不會對第二個引數求值,常用的例子如下
int main()
{
int a=3,b=3;
(a=0)&&(b=5);
printf("a=%d,b=%d\n",a,b); // a = 0 ,b = 3
(a=1)||(b=5);
printf("a=%d,b=%d",a,b); // a = 1 ,b = 3
}
??a=0為假所以沒有對B進行操作
??a=1為真,所以沒有對b進行操作
邏輯左移和算術左移
??邏輯左移(SHL)和算數左移(SAL),規則相同,右邊統一添0
??邏輯右移(SHR),左邊統一添0
??算數右移(SAR),左邊添加的數和符號有關 (正數補0,負數補1)
??比如一個有符號位的8位二進制數11001101,邏輯右移不管符號位,如果移一位就變成01100110,算術右移要管符號位,右移一位變成11100110,
??e.g:1010101010,其中[]位是添加的數字
??邏輯左移一位:010101010[0]
??算數左移一位:010101010[0]
??邏輯右移一位:[0]101010101
??算數右移一位:[1]101010101
移位符號(<<, >>, >>>)
??<<,有符號左移位,將運算元的二進制整體左移指定位數,低位用0補齊,
??>>,有符號右移位,將運算元的二進制整體右移指定位數,正數高位用0補齊,負數高位用1補齊(保持負數符號不變),
擴展:當移動位數大于實際位數時該怎么辦?
??對于一個由w位組成的資料型別,如果要移動k≥w位會得到什么結果呢?例如,計算下面的運算式會得到什么結果,假設資料型別int為w=32,
int lval=OxFEDCBA98 << 32;
int aval=0xFEDCBA98 >> 36;
unsigned uval = OxFEDCBA98u >>40;
?? C語言標準很小心地規避了說明在這種情況下該如何做,在許多機器上,當移動一個w位的值時,移位指令只考慮位移量的低\([{\log _2}w]\)位,因此實際上位移量就是通過計算k mod w得到的,例如,當w=32時,上面三個移位運算分別是移動0、4和8位,得到結果:
lval OxFEDCBA98
aval OxFFEDCBA9
uvaL OXOOFEDCBA
??不過這種行為對于C程式來說是沒有保證的,所以應該保持位移量小于待移位值的位數,
整數表示
??約定一些術語如下所示
| 符號 | 型別 | 含義 |
|---|---|---|
| \([B2{T_w}]\) | 函式 | 二進制轉補碼 |
| \([B2{U_w}]\) | 函式 | 二進制轉無符號數 |
| \([U2{B_w}]\) | 函式 | 無符號數轉二進制 |
| \([U2{T_w}]\) | 函式 | 無符號轉補碼 |
| \([T2{B_w}]\) | 函式 | 補碼轉二進制 |
| \([T2{U_w}]\) | 函式 | 補碼轉無符號數 |
| \(T{Min_w}\) | 常數 | 最小補碼值 |
| \(T{Max_w}\) | 常數 | 最大補碼值 |
| \(U{Max_w}\) | 常數 | 最大無符號數 |
| \(+ _w^t\) | 操作 | 補碼加法 |
| \(+ _w^u\) | 操作 | 無符號數加法 |
| \(* _w^t\) | 操作 | 補碼乘法 |
| \(* _w^u\) | 操作 | 無符號數乘法 |
| \(- _w^t\) | 操作 | 補碼取反 |
| \(- _w^u\) | 操作 | 無符號數取反 |
無符號數的編碼
??無符號數編碼的定義:
??對向量\(\vec x = [{x_{w - 1}},{x_{w - 2}}, \cdots ,{x_0}]\):\(B2{U_w}(\vec x) = \sum\limits_{i = 0}^{w - 1} {{x_i}{2^i}}\),
??其中,\(\vec x\)看作一個二進制表示的數,每個位\({x_i}\)取值為0或1,舉個例子如下所示,
\(B2{U_4}([0001]) = 0*{2^3} + 0*{2^2} + 0*{2^1} + 1*{2^0} = 0 + 0 + 0 + 1 = 1\)
\(B2{U_4}([1111]) = 1*{2^3} + 1*{2^2} + 1*{2^1} + 1*{2^0} = 8 + 4 + 2 + 1 = 15\)
??無符號數能表示的最大值為:\(UMa{x_w} = \sum\limits_{i = 0}^{w - 1} {{2^w} - 1}\)
補碼的編碼
??補碼編碼的定義:
??對向量\(\vec x = [{x_{w - 1}},{x_{w - 2}}, \cdots ,{x_0}]\):\(B2{T_w}(\vec x) = - {x_{w - 1}}{2^{w - 1}} + \sum\limits_{i = 0}^{w - 2} {{x_i}{2^i}}\),
??最高有效位\({x_{w - 1}}\)也稱為符號位,它的“權重”為$ - {2^{w - 1}}$,是無符號表示中權重的負數,符號位被設定為1時,表示值為負,而當設定為0時,值為非負,舉個例子
\(B2{T_4}([0001]) = - 0*{2^3} + 0*{2^2} + 0*{2^1} + 1*{2^0} = 0 + 0 + 0 + 1 = 1\)
\(B2{T_4}([1111]) = - 1*{2^3} + 1*{2^2} + 1*{2^1} + 1*{2^0} = - 8 + 4 + 2 + 1 = - 1\)
??w位補碼所能表示的范圍:\(TMi{n_w} = - {2^{w - 1}}\),\(TMa{x_w} = {2^{w - 1}} - 1\),
關于補碼需要注意的地方
??第一,補碼的范圍是不對稱的:\(\left| {TMin} \right| = \left| {TMax} \right| + 1\),也就是說,\(TMin\)沒有與之對應的正數,之所以會有這樣的不對稱性,是因為一半的位模式(符號位設定為1的數)表示負數,而另一半(符號位設定為0的數)表示非負數,因為0是非負數,也就意味著能表示的整數比負數少一個,
??第二,最大的無符號數值剛好比補碼的最大值的兩倍大一點:\(UMa{x_w} = 2TMa{x_w} + 1\),補碼表示中所有表示負數的位模式在無符號表示中都變成了正數,
??注:補碼并不是計算機表示負數的唯一方式,只是大家都采用了這種方式,計算機也可以用其他方式表示負數,比如原碼和反碼,有興趣可以繼續深入了解,
確定資料型別的大小
??在不同位長的系統中,int,double,long等占據的位數不同,其可表示的范圍的大小也不一樣,如何撰寫具有通用性的程式呢?ISO C99標準在檔案stdint.h中引入了整數型別類,這個檔案定義了一組資料型別,他們的宣告形式位:intN_t,uintN_t(N取值一般為8,16,32,64),比如,uint16_t在任何作業系統中都可以表述一個16位的無符號變數,int32_t表示32位有符號變數,
??同樣的,這些資料型別的最大值和最小值由一組宏定義表示,比如INTN_MIN,INTN_MAX和UINTN_MAX,
??列印確定型別的內容時,需要使用宏,
??比如,列印int32_t,uint64_t,可以用如下方式:
printf("x=%"PRId32",y=%"PRIu64"\n",x,y);
??編譯為64位程式時,宏PRId32展開成字串“d”,宏PRIu64則展開成兩個字串“l”“u”,當C前處理器遇到僅用空格(或其他空白字符)分隔的一個字串常量序列時,就把它們串聯起來,因此,上面的 printf呼叫就變成了:printf("x=%d.y=%lu\n",x,y);
??使用宏能保證:不論代碼是如何被編譯的,都能生成正確的格式字串,
無符號數和補碼的相互轉化
??補碼轉換為無符號數:
對于滿足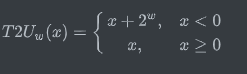
舉例如下:
| x | \(T2{U_4}(x)\) | 解釋 |
|---|---|---|
| -8 | 8 | -8<0,-8+\({2^4}\)=16,\(T2{U_4}(-8)\)=16 |
| -3 | 13 | -3<0,-3+\({2^4}\)=13,\(T2{U_4}(-3)\)=16 |
| -2 | 14 | -2<0,-2+\({2^4}\)=14,\(T2{U_4}(-2)\)=16 |
| -1 | 15 | -1<0,-1+\({2^4}\)=15,\(T2{U_4}(-1)\)=16 |
| 0 | 0 | \(T2{U_4}(0)\)=0 |
| 5 | 5 | \(T2{U_4}(5)\)=5 |
??無符號數轉補碼:
??對于滿足\(0 \le u \le UMa{x_w}\)的u有:
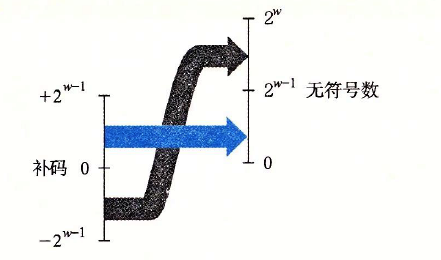
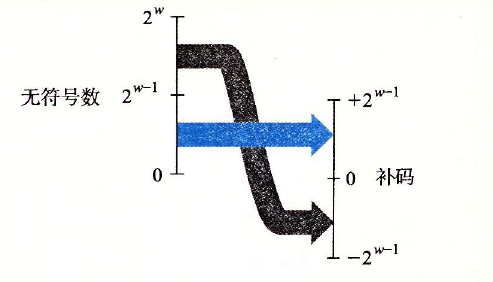
??結合下面兩張圖理解下:
??從補碼到無符號數的轉換,函式T2U將負數轉換為大的正數
??從無符號數到補碼的轉換,函式U2T把大于\({2^{w - 1}} - 1\)的數字轉換為負值
有符號數與無符號數的轉換
??前面提到過,補碼并不是計算機表示負數的唯一方式,但是幾乎所有的計算機都是使用補碼來表示負數,因此無符號數轉有符號數就是使用函式\(U2{T_w}\),而從有符號數轉無符號數就是應用函式\(T2{U_w}\),
??注意:當執行一個運算時,如果它的一個運算元是有符號的而另一個是無符號的,那么C語言會隱式地將有符號引數強制型別轉換為無符號數,并假設這兩個數都是非負的,來執行這個運算,
??比如,假設資料型別int表示為32位補碼,求運算式-1<0U的值,因為第二個運算元是無符號的,第一個運算元就會被隱式地轉換為無符號數,因此運算式就等價于4294967295U<0U,所以運算式的值為0,
擴展數字
??要將一個無符號數轉換為一個更大的資料型別,我們只要簡單地在表示的開頭添加0,這種運算被稱為零擴展( zero extension),
??比如,將16位的無符號數12(0xC),擴展為32位為0x0000000C,
??要將一個補碼數字轉換為一個更大的資料型別,可以執行一個符號擴展( sign exten sion),即擴展符號位,
??比如,將16位的有符號數-25(0x8019,1000000000011001),擴展為32位為0xffff8019,
截斷數字
??無符號數截斷公式為:\(B2{U_k}(x) = B2{U_w}(X)mod{2^k}\)等價于\(x' = x\bmod {2^k}\),\(x'\)為其截斷k位的結果,
??比如,將9從int轉換為short,即需要截斷16位,k=16,\(9\bmod {2^{16}} = 9\),因此,9從int轉換為short的結果為9,
??有符號數的截斷公式為:\(B2{T_k}(x) = U2{T_k}(B2{U_w}(X)mod{2^k})\)等價于\(x' = U2{T_k}(x{\kern 1pt} {\kern 1pt} {\kern 1pt} mod{2^k})\),\(x'\)為其截斷k位的結果,
??比如,將53791從int轉換為short,即需要截斷16位,k=16,\(53791\bmod {2^{16}} = 53791\),\(U2{T_{16}}(53791) = 53791 - 65536 = - 12345\),因此,53791從int轉換為short的結果為-12345,
??無符號數截斷的幾個例子(將4位數值截斷為3位)
| 原始值 | 截斷值 |
|---|---|
| 0 | 0 |
| 2 | 2 |
| 9 | 1 |
| 11 | 3 |
| 15 | 7 |
??有符號數截斷的幾個例子(將4位數值截斷為3位)
| 原始值 | 截斷值 |
|---|---|
| 0 | 0 |
| 2 | 2 |
| -7 | 1 |
| -5 | 3 |
| -1 | -1 |
小結
??關于有符號數和無符號數的轉換,數字的擴展與截斷,經常發生于不同型別,不同位長數字的轉換,這些操作一般都是由計算機自動完成的,但是我們最好要知道計算機是如何完成轉換的,這對于我們檢查BUG是特別有用的,這些內容我們不一定要都記住,但是當發生錯誤時,我們是要知道從哪里檢查,
整數運算
無符號數加法
??對滿足
,正常情況下,x+y的值保持不變,而溢位情況則是該和減去\({2^{\rm{w}}}\)的結果,
比如,考慮一個4位數字表示(最大值為15),x=9,y=12,和為21,超出了范圍,那么x+y的結果為9+12-15=6,
補碼加法
對滿足
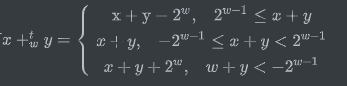
??當\({{2^{w - 1}} \le x + y}\),產生正溢位,當\({w + y < - {2^{w - 1}}}\),產生負溢位,當\({ - {2^{w - 1}} \le x + y < {2^{w - 1}}}\),正常,具體參考下圖,
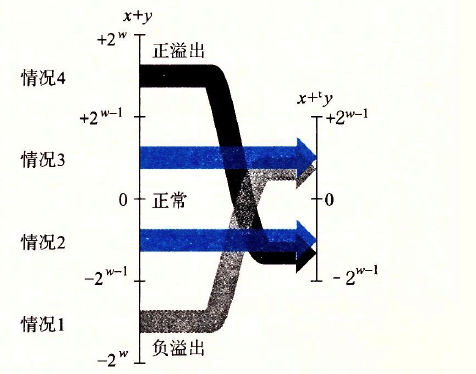
??舉例如下表所示(以4位補碼加法為例)
| x | y | x+y | \(x + _4^ty\) | 情況 |
|---|---|---|---|---|
| -8[1000] | -5[1011] | -13[10011] | 3[0011] | 1 |
| -8[1000] | -8[1000] | -16[10000] | 0[0000] | 1 |
| -8[1000] | 5[0101] | -3[11101] | -3[1101] | 2 |
| 2[0010] | 5[0101] | 7[00111] | 7[0111] | 3 |
| 5[0101] | 5[0101] | 10[01010] | -6[1010] | 4 |
補碼的非
??對滿足\(TMi{n_w} \le x \le TMa{x_w}\)的x,其補碼的非\(- _w^tx\)由下式給出
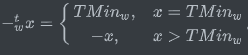
(吐槽下CSDN,使用typora寫好latex公式,粘貼過來報錯,原來CSDN的Markdown是用Katex渲染的,這不是增加作業量嗎?)
??也就是說,對w位的補碼加法來說,\({TMi{n_w}}\)是自己的加法的逆,而對其他任何數值x都有-x作為其加法的逆,
無符號數的乘法
??對滿足\(0 \le x,y \le UMa{x_w}\)的x和y有:\(x*_w^uy = (x*y)mod{2^w}\),
補碼的乘法
??對滿足\(TMi{n_w} \le {\rm{x}}{\rm{y}} \le TM{\rm{a}}{{\rm{x}}_{\rm{w}}}\)的x和y有:\(x*_w^ty = U2{T_w}((x*y)mod{2^w})\),
舉例,3位數字乘法的結果
| 模式 | x | y | x * y | 截斷的x * y |
|---|---|---|---|---|
| 無符號 | 4 [100] | 5 [101] | 20 [010100] | 4 [100] |
| 補碼 | -4 [100] | -3 [101] | 12 [001100] | -4 [100] |
| 無符號 | 2 [010] | 7 [111] | 14 [001110] | 6 [110] |
| 補碼 | 2 [010] | -1 [111] | -2 [111110] | -2 [110] |
| 無符號 | 6 [110] | 6 [110] | 36 [100100] | 4 [100] |
| 補碼 | -2 [110] | -2 [110] | 4 [000100] | -4 [100] |
常數與符號數的乘法
??在大多數機器上,整數乘法指令相當慢,需要10個或者更多的時鐘周期,然而其他整數運算(例如加法、減法、位級運算和移位)只需要1個時鐘周期,因此,編譯器使用了一項重要的優化,試著用移位和加法運算的組合來代替乘以常數因子的乘法,
??由于整數乘法比移位和加法的代價要大得多,許多C語言編譯器試圖以移位、加法和減法的組合來消除很多整數乘以常數的情況,例如,假設一個程式包含運算式x*14,利用\(14 = {2^3} + {2^2} + {2^1}\),編譯器會將乘法重寫為(x<<3)+(x<<2)+(x<1),將一個乘法替換為三個移位和兩個加法,無論x是無符號的還是補碼,甚至當乘法會導致溢位時,兩個計算都會得到一樣的結果,(根據整數運算的屬性可以證明這一點,)更好的是,編譯器還可以利用屬性\(14 = {2^4} - 1\),將乘法重寫為(x<<4)-(x<<1),這時只需要兩個移位和一個減法,
??歸納以下,對于某個常數的K的運算式x * K生成代碼,我們可以用下面兩種不同形式中的一種來計算這些位對乘積的影響:
??形式A:\((x < < n) + (x < < (n - 1)) + \cdots + (x < < m)\)
??形式B:\((x < < (n + 1)) - (x < < m)\)
??對于嵌入式開發中,我們經常使用這種方式來操作暫存器了,在編程中,我們要習慣使用移位運算來代替乘法運算,可以大大提高代碼的效率,
常數與符號數的除法
??在大多數機器上,整數除法要比整數乘法更慢—需要30個或者更多的時鐘周期,除以2的冪也可以用移位運算來實作,只不過我們用的是右移,而不是左移,無符號和補碼數分別使用邏輯移位和算術移位來達到目的,
無符號數的除法
??對無符號運算使用移位是非常簡單的,部分原因是由于無符號數的右移一定是邏輯右移,同時注意,移位總是舍入到零,
??舉例如下,以12340的16位表示邏輯右移k位的結果,左端移入的零以粗體表示,
| k | >>k(二進制) | 十進制 | \(12340/{2^k}\) |
|---|---|---|---|
| 0 | 0011000000110100 | 12340 | 12340.0 |
| 1 | 0001100000011010 | 6170 | 6170.0 |
| 4 | 0000001100000011 | 771 | 771.25 |
| 8 | 0000000000110000 | 48 | 48.203125 |
補碼的除法(向下舍入)
??對于除以2的冪的補碼運算來說,情況要稍微復雜一些,首先,為了保證負數仍然為負,移位要執行的是算術右移,
??對于x≥0,變數x的最高有效位為0,所以效果與邏輯右移是一樣的,因此,對于非負數來說,算術右移k位與除以\({2^k}\)是一樣的,
??舉例如下所示,對-12340的16位表示進行算術右移k位,對于不需要舍入的情況(k=1),結果是\(x/{2^k}\),當需要進行舍入時,移位導致結果向下舍入,例如,右移4位將會把-771.25向下舍入為-772,我們需要調整策略來處理負數x的除法,
| k | >>k(二進制) | 十進制 | \(-12340/{2^k}\) |
|---|---|---|---|
| 0 | 1100111111001100 | -12340 | -12340.0 |
| 1 | 1110011111100110 | -6170 | -6170.0 |
| 4 | 1111110011111100 | -772 | -771.25 |
| 8 | 1111111111001111 | -49 | -48.203125 |
補碼的除法(向上舍入)
??我們可以通過在移位之前“偏置( biasing)”這個值,來修正這種不合適的舍入,
??下表說明在執行算術右移之前加上一個適當的偏置量是如何導致結果正確舍入的,在第3列,我們給出了-12340加上偏量值之后的結果,低k位(那些會向右移出的位)以斜體表示,我們可以看到,低k位左邊的位可能會加1,也可能不會加1,對于不需要舍入的情況(k=1),加上偏量只影響那些被移掉的位,對于需要舍入的情況,加上偏量導致較高的位加1,所以結果會向零舍入,
| k | 偏量 | -12340+偏量 | >>k(二進制) | 十進制 | \(-12340/{2^k}\) |
|---|---|---|---|---|---|
| 0 | 0 | 1100111111001100 | 1100111111001100 | -12340 | -12340.0 |
| 1 | 1 | 1100111111001101 | 1110011111100110 | -6170 | -6170.0 |
| 4 | 15 | 1100111111011011 | 1111110011111100 | -771 | -771.25 |
| 8 | 255 | 1101000011001011 | 1111111111001111 | -48 | -48.203125 |
總結
??現在我們看到,除以2的冪可以通過邏輯或者算術右移來實作,這也正是為什么大多數機器上提供這兩種型別的右移,不幸的是,這種方法不能推廣到除以任意常數,同乘法不同,我們不能用除以2的冪的除法來表示除以任意常數K的除法,
浮點數
二進制小數
??一種關于二進制的小數編碼:\(b = \sum\limits_{i = - n}^m {{2^i} \times {b_i}}\),
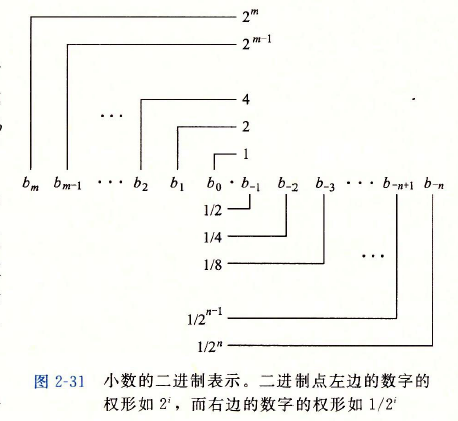
??二進制小數點向左移動一位相當于這個數被2除,二進制小數點向右移動一位相當于將數乘2,
IEEE浮點表示
IEEE浮點標準用\(V = {( - 1)^s} \times M \times {2^E}\)的形式來表示一個數
-
符號(sign)s決定這數是負數(s=1)還是正數(s=0),而對于數值0的符號位解釋作為特殊情況處理,
-
尾數( significand)M是一個二進制小數,它的范圍是$1 \sim 2 - \varepsilon $,或者是$0 \sim 1 - \varepsilon $,
-
階碼( exponent)E的作用是對浮點數加權,這個權重是2的E次冪(可能是負數),將浮點數的位表示劃分為三個欄位,分別對這些值進行編碼:
-
一個單獨的符號位s直接編碼符號s
-
k位的階碼欄位\(\exp = {e_{k - 1}} \cdots {e_1}{e_0}\)編碼階碼E,
-
n位小數欄位\(frac = {f_{n - 1}} \cdots {f_1}{f_0}\)編碼尾數M,但是編碼出來的值也依賴于階碼欄位的值是否等于0,
??C語言中的編碼方式:
??單精度浮點格式(float) —— s、exp和frac欄位分別為1位、k = 8位和n = 23位,得到一個32位表示,
?? 雙精度浮點格式(double) —— s、exp和frac欄位分別為1位、k = 11位和n = 52位,得到一個64位表示,

??根據exp的值,被編碼的值可以分成三種不同的情況:
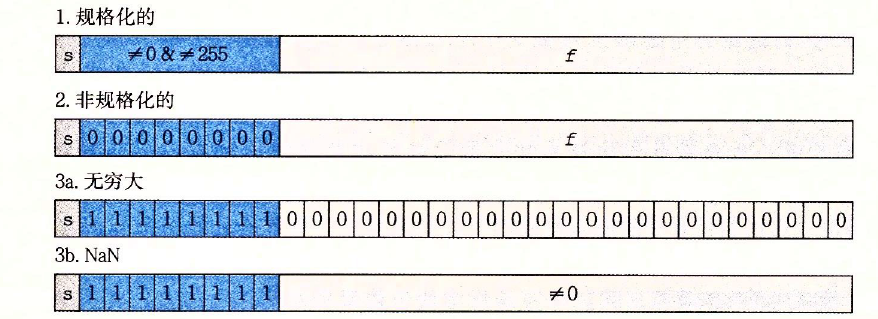
?? 情況1:規格化的值 —— exp的位模式:既不全為0(數值0),也不全為1(單精度數值為255,雙精度數值為2047),
?? 階碼的值:E = e - Bias(偏置編碼法)
??e是無符號數,其位表示為 \({e_{k - 1}} \cdots {e_1}{e_0}\),單精度下取值范圍為1~254.雙精度下取值范圍為1 ~ 2047,
?? 偏置值\(Bias = {2^{k - 1}} - 1\),單精度下是127,雙精度下是1023,
??因此階段碼E的取值范圍:單精度下是-126 ~ +127,雙精度下是-1022 ~ 1024,
e的范圍:1~254
Bias的值:127
E的范圍:-126~127
?? 尾數的值:M=1+f(隱式編碼法,因為有個隱含的1,所以無法表示0)
?? 其中\(0 \le f \le 1.0\),f的二進制表示為\(0.{f_{n - 1}} \cdots {f_1}{f_0}\),也就是二進制小數點在最高有效位的左邊,
??因此添加了一個隱含的1,M的取值范圍為\(1.0 \le M \le 2.0\),
為什么不在exp域中使用補碼編碼?為什么采用偏置編碼的形式?
exp域如果為補碼編碼,比較兩個浮點數既要比較補碼的符號位,又要比較編碼位,
而在exp域中采用偏置編碼,我們只需要比較一次無符號數e的值就可以了,
舉例:float f = 15213.0
\(\begin{array}{l} {15213_{10}} = {11101101101101_2}\\ \quad {\kern 1pt} \;\;\, = {1.1101101101101_2} \times {2^{13}} \end{array}\)
\(\begin{array}{l} M = {1.1101101101101_2}\\ frac = {11011011011010000000000_2} \end{array}\)
則:
\(\begin{array}{l} E = 13\\ Bias = 127\\ \exp = 140 = {10001100_2} \end{array}\)

??情況2:非規格化的值 —— exp的位模式為全0,
??階碼的值:E = 1 - Bias,
??尾數的值:M = f(沒有隱含的1,可以表示0)
??非規格化數有兩個用途:
??表示數值0 —— 只要尾數M = 0,
?? 表示非常接近于0.0的數
??情況3:特殊值 —— exp的位模式為全1,
??當小數域全為0時,得到的值表示無窮,當s = 0時是\(+ \infty\),當s=1時是\(-\infty\),當小數域為非零0,得到NaN(Not a Number),
浮點數的運算規則
整數和浮點數相乘
??規則:\(x{ + _f}y = Round(x + y)\),\(x{ \times _f}y = Round(x \times y)\),其中\(Round(x \times y)\)要遵循下表的舍入規則,
| 1.4 | 1.6 | 1.5 | 2.5 | -1.5 | |
|---|---|---|---|---|---|
| 向0舍入 | 1 | 1 | 1 | 2 | -1 |
| 向負無窮舍入 | 1 | 1 | 1 | 2 | -2 |
| 向正無窮舍入 | 2 | 2 | 2 | 3 | -1 |
| 偶數舍入(四舍五入) | 1 | 2 | 2 | 2 | -2 |
兩個浮點數相乘
??兩個浮點數相乘規則:\(({( - 1)^{s1}} \times M1 \times {2^{E1}}) \times ({( - 1)^{s2}} \times M2 \times {2^{E2}}) = {( - 1)^S} \times M \times {2^E}\)
??S:s1^s2
??M:M1+M2
??E:E1+E2
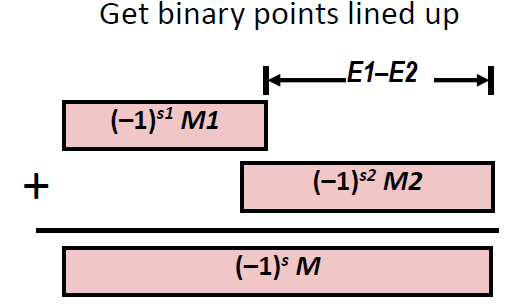
兩個浮點數相加
??浮點數相加規則:\({( - 1)^{s1}} \times M1 \times {2^{E1}} + {( - 1)^{s2}} \times M2 \times {2^{E2}} = {( - 1)^S} \times M \times {2^E}\)
??S和M的值為兩個浮點數小數點對齊后相加的結果,
??E:E1 (假設E1>E2)
浮點數的偶數舍入
??例如有效數字超出規定數位的多余數字是1001,它大于超出規定最低位的一半(即0.5),故最低位進1,如果多余數字是0111,它小于最低位的一半,則舍掉多余數字(截斷尾數、截尾)即可,對于多余數字是1000、正好是最低位一半的特殊情況,最低位為0則舍掉多余位,最低位為1則進位1、使得最低位仍為0(偶數),
??注意這里說明的數位都是指二進制數,
舉例:要求保留小數點后3位,
對于1.0011001,舍入處理后為1.010(去掉多余的4位,加0.001)
對于1.0010111,舍入處理后為1.001(去掉多余的4位)
對于1.0011000,舍入處理后為1.010(去掉多余的4位,加0.001,使得最低位為0)對于1.1001001,舍入處理后為1.101(去掉多余的4位,加0.001)
對于1.1000111,舍入處理后為1.100(去掉多余的4位)
對于1.1001000,舍入處理后為1.100(去掉多余的4位,不加,因為最低位已經為0)對于1.01011,舍入處理后為1.011(去掉多余的2位,加0.001)
對于1.01001,舍入處理后為1.010(去掉多余的2位)
對于1.01010,舍入處理后為1.010(去掉多余的2位,不加)
注意
??浮點數的運算不支持結合律,
舉例:(1e10+3.14)-1e10=0,3.14+(1e10-1e10)=3.14,因為舍入的原因,第一個運算式會丟失3.14,
舉例:(1e20 * 1e20)1e-20 求值為正無窮,而1e20 * (1e201e-20) = 1e20,
C語言中的浮點數
在C語言中,當在int、float和 double格式之間進行強制型別轉換時,程式改變數值和位模式的原則如下(假設int是32位的)
- 從int轉換成 float,數字不會溢位,但是可能被舍入,
- 從int或float轉換成 double,因為double有更大的范圍(也就是可表示值的范圍),也有更高的精度(也就是有效位數),所以能夠保留精確的數值,
- 從 double轉換成float,因為范圍要小一些,所以值可能溢位成\(+ \infty\)或\(- \infty\),另外,由于精確度較小,它還可能被舍入從float或者 double轉換成int,值將會向零舍入,例如,1.999將被轉換成1,而-1.999將被轉換成-1,進一步來說,值可能會溢位,C語言標準沒有對這種情況指定固定的結果,一個從浮點數到整數的轉換,如果不能為該浮點數找到一個合理的整數近似值,就會產生這樣一個值,因此,運算式(int)+1e10會得到-21483648,即從一個正值變成了一個負值,
舉例:int x = ...; float f = ....;double d =... ;
運算式 對/錯 備注 x == (int)(float)x 錯 float 沒有足夠的位表示int,轉換會造成精度丟失 x == (int)(double)x 對 f ==(float)(double)f 對 d == (double)(float)d 錯 float->double精度不夠 f == -(-f) 對 2/3 == 2/3.0 錯 d<0.0 ==> ((d*2)<0.0) 對 d>f ==> -f >-d 對 d*d >=0.0 對 (d+f)-d == f 錯 沒有結合律
總結
??本章中需要掌握的內容主要有:無符號數,補碼,有符號數的編碼方式,可表示的范圍大小,相互轉換的規則,運算規則,浮點數的編碼方式了解即可,這部分有點難以理解,如果后面有用到的話再回來細看,但是對于C語言中其他資料型別到浮點數的轉換規則是要掌握的,
??養成習慣,先贊后看!如果覺得寫的不錯,歡迎關注,點贊,轉發,一鍵三連謝謝!
如遇到排版錯亂的問題,可以通過以下鏈接訪問我的CSDN,
CSDN:CSDN搜索“嵌入式與Linux那些事”
歡迎歡迎關注我的公眾號:嵌入式與Linux那些事,領取秋招筆試面試大禮包(華為小米等大廠面經,嵌入式知識點總結,筆試題目,簡歷模版等)和2000G學習資料,

轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/231704.html
標籤:其他
下一篇:Linux命令總結