本章主要介紹了計算機中的機器代碼——匯編語言,當我們使用高級語言(C、Java等)編程時,代碼會屏蔽機器級的細節,我們無法了解到機器級的代碼實作,既然有了高級語言,我們為什么還需要學習匯編語言呢?學習程式的機器級實作,可以幫助我們理解編譯器的優化能力,可以讓我們了解程式是如何運行的,哪些部分是可以優化的;當程式受到攻擊(漏洞)時,都會涉及到程式運行時控制資訊的細節,很多程式都會利用系統程式中的漏洞資訊重寫程式,從而獲得系統的控制權(蠕蟲病毒就是利用了gets函式的漏洞),特別是作為一名嵌入式軟體開發的從業人員,會經常接觸到底層的代碼實作,比如Bootloader中的時鐘初始化,重定位等都是用匯編語言實作的,雖然不要求我們使用匯編語言寫復雜的程式,但是要求我們要能夠閱讀和理解編譯器產生的匯編代碼,
@
目錄- 程式編碼
- 計算機的抽象模型
- 匯編代碼中的暫存器
- 機器代碼示例
- 反匯編簡介
- 資料格式
- 訪問資訊
- 運算元指示符
- 整數暫存器
- 三種型別的運算元
- 運算元的格式
- 資料傳送指令
- 壓入和彈出堆疊資料
- 運算元指示符
- 算數和邏輯操作
- 加載有效地址
- 一元和二元操作
- 移位操作
- 控制
- 條件碼
- 訪問條件碼
- 跳轉指令
- 跳轉指令的編碼
- 條件控制實作條件分支
- 條件傳送實作條件分支
- 回圈
- suitch陳述句
- 程序
- 運行時堆疊
- 轉移控制
- 資料傳送
- 堆疊上的區域存盤
- 暫存器中的區域存盤
- 遞回程序
- 陣列分配和訪問
- 基本原則
- ??指標運算
- 二維陣列
- 異質的資料結構
- 結構體
- 資料對齊
- 在機器級程式中將控制和程式結合起來
- 理解指標
- 記憶體越界參考
- 浮點代碼
- 資料傳送指令
- 雙運算元浮點轉換指令
- 三運算元浮點轉換指令
- 標量浮點算術運算
- 浮點數的位級操作
- 比較浮點數值的指令
程式編碼
計算機的抽象模型
??在之前的《深入理解計算機系統》(CSAPP)讀書筆記 —— 第一章 計算機系統漫游文章中提到過計算機的抽象模型,計算機利用更簡單的抽象模型來隱藏實作的細節,對于機器級編程來說,其中兩種抽象尤為重要,第一種是由指令集體系結構或指令集架構( Instruction Set Architecture,ISA)來定義機器級程式的格式和行為,它定義了處理器狀態、指令的格式,以及每條指令對狀態的影響,大多數ISA,包括x86-64,將程式的行為描述成好像每條指令都是按順序執行的,一條指令結束后,下一條再開始,處理器的硬體遠比描述的精細復雜,它們并發地執行許多指令,但是可以采取措施保證整體行為與ISA指定的順序執行的行為完全一致,第二種抽象是,機器級程式使用的記憶體地址是虛擬地址,提供的記憶體模型看上去是一個非常大的位元組陣列,存盤器系統的實際實作是將多個硬體存盤器和作業系統軟體組合起來,
匯編代碼中的暫存器
??程式計數器(通常稱為“PC”,在x86-64中用號%rip表示)給出將要執行的下一條指令在記憶體中的地址,
??整數暫存器檔案包含16個命名的位置,分別存盤64位的值,這些暫存器可以存盤地址(對應于C語言的指標)或整數資料,有的暫存器被用來記錄某些重要的程式狀態,而其他的暫存器用來保存臨時資料,例如程序的引數和區域變數,以及函式的回傳值,
??條件碼暫存器保存著最近執行的算識訓邏輯指令的狀態資訊,它們用來實作控制或資料流中的條件變化,比如說用來實作if和 while陳述句
??一組向量暫存器可以存放個或多個整數或浮點數值
??關于匯編中常用的暫存器建議看我整理的嵌入式軟體開發面試知識點中的ARM部分,里面詳細介紹了Arm中常用的暫存器和指令集,
機器代碼示例
??假如我們有一個main.c檔案,使用 gcc -0g -S main.c可以產生一個匯編檔案,接著使用gcc -0g -c main.c就可以產生目標代碼檔案main.o,通常,這個.o檔案是二進制格式的,無法直接查看,我們打開編輯器可以調整為十六進制的格式,示例如下所示,
53 48 89 d3 e8 00 00 00 00 48 89 03 5b c3
??這就是匯編指令對應的目標代碼,從中得到一個重要資訊,即機器執行的程式只是一個位元組序列,它是對一系列指令的編碼,機器對產生這些指令的源代碼幾乎一無所知,
反匯編簡介
??要查看機器代碼檔案的內容,有一類稱為反匯編器( disassembler)的程式非常有用,這些程式根據機器代碼產生一種類似于匯編代碼的格式,在 Linux系統中,使用命令 objdump -d main.o可以產生反匯編檔案,示例如下圖,

??在左邊,我們看到按照前面給出的位元組順序排列的14個十六進制位元組值,它們分成了若干組,每組有1~5個位元組,每組都是一條指令,右邊是等價的匯編語言
??其中一些關于機器代碼和它的反匯編表示的特性值得注意
-
x86-64的指令長度從1到15個位元組不等,常用的指令以及運算元較少的指令所需的位元組數少,而那些不太常用或運算元較多的指令所需位元組數較多
-
設計指令格式的方式是,從某個給定位置開始,可以將位元組唯一地解碼成機器指令,例如,只有指令 push%rbx是以位元組值53開頭的
-
反匯編器只是基于機器代碼檔案中的位元組序列來確定匯編代碼,它不需要訪問該程式的源代碼或匯編代碼
-
反匯編器使用的指令命名規則與GCC生成的匯編代碼使用的有些細微的差別,在我們的示例中,它省略了很多指令結尾的‘q’,這些后綴是大小指示符,在大多數情況中可以省略,相反,反匯編器給ca11和ret指令添加了‘q’后綴,同樣,省略這些后綴也沒有問題,
資料格式
?? Intel用術語“字(word)”表示16位資料型別,因此,稱32位數為“雙字( double words)”,稱64位數為“四字( quad words),下表給出了C語言基本資料型別對應的x86-64表示,
| C宣告 | Intel資料型別 | 匯編代碼后綴 | 大小(位元組) |
|---|---|---|---|
| char | 位元組 | b | 1 |
| short | 字 | w | 2 |
| int | 雙字 | l | 4 |
| long | 四字 | q | 8 |
| char* | 四字 | q | 8 |
| float | 單精度 | s | 4 |
| double | 雙精度 | 1 | 8 |
訪問資訊
運算元指示符
整數暫存器
??不同位的暫存器名字不同,使用的時候要注意,

三種型別的運算元
??1.立即數,用來表示常數值,比如,$0x1f ,不同的指令允許的立即數值范圍不同,匯編器會自動選擇最緊湊的方式進行數值編碼,
??2.暫存器,它表示某個暫存器的內容,16個暫存器的低位1位元組、2位元組、4位元組或8位元組中的一個作為運算元,這些位元組數分別對應于8位、16位、32位或64位,在圖3-3中,我們用符號\({r_a}\)來表示任意暫存器a,用參考\(R[{r_a}]\)來表示它的值,這是將暫存器集合看成一個陣列R,用暫存器識別符號作為索引,
??3.記憶體參考,它會根據計算出來的地址(通常稱為有效地址)訪問某個記憶體位置,因為將記憶體看成一個很大的位元組陣列,我們用符號\({M_b}[Addr]\)表示對存盤在記憶體中從地址Addr開始的b個位元組值的參考,為了簡便,我們通常省去下標b,
運算元的格式
??看匯編指令的時候,對照下圖可以讀懂大部分的匯編代碼,
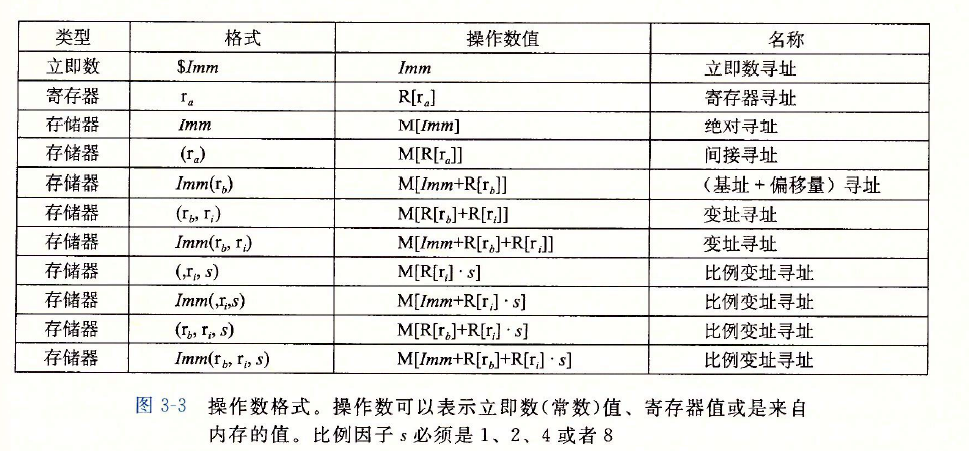
資料傳送指令
??不同后綴的指令主要區別在于它們操作的資料大小不同,
??源運算元:暫存器,記憶體
??目的運算元:暫存器,記憶體,
注意:傳送指令的兩個運算元不能都指向記憶體位置,將一個值從一個記憶體位置復制到另一個記憶體位置需要兩條指令—第一條指令將源值加載到暫存器中,第二條將該暫存器值寫入目的位置,
movl $0x4050,%eax Immediate--Register,4 bytes p,1sp move movw %bp,%sp Register--Register, 2 bytes movb (%rdi. %rcx),%al Memory--Register 1 bytes movb $-17,(%rsp) Immediate--Memory 1 bytes movq %rax,-12(%rpb) Register--Memory, 8 bytes
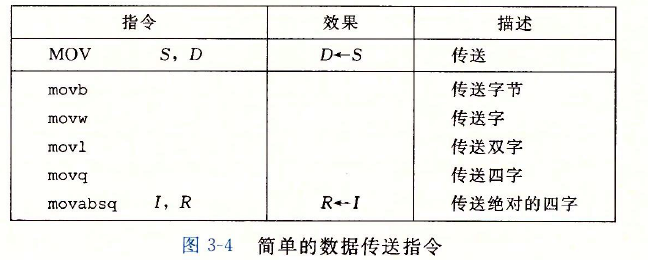
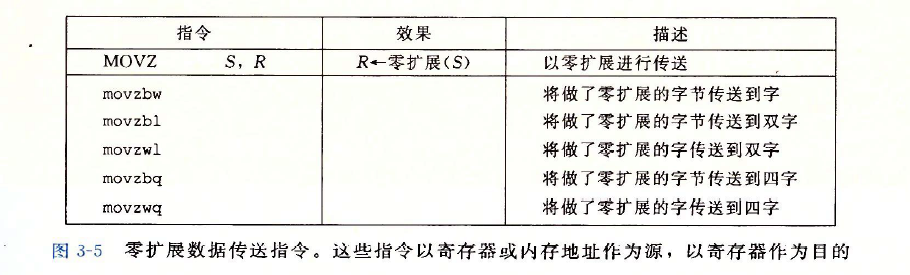
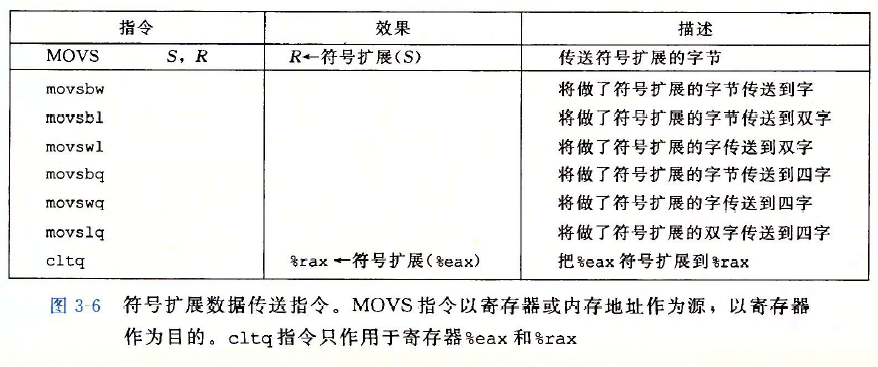
??將較小的源值復制到較大的目的時使用如下指令,
舉例

??程序引數xp和y分別存盤在暫存器%rdi和%rsi中(引數通過暫存器傳遞給函式),
??第二行:指令movq從記憶體中讀出xp,把它存放到暫存器%rax中(像x這樣的區域變數通常是保存在暫存器中,而不是在記憶體中),
??第三行:指令movq將y寫入到暫存器%rdi中的xp指向的記憶體位置,
??第四行:指令ret用暫存器 %rax從這個函式回傳一個值,
??總結:
??間接參考指標就是將該指標放在一個暫存器中,然后在記憶體參考中使用這個暫存器,
??像x這樣的區域變數通常是保存在暫存器中,而不是記憶體中,訪問暫存器比訪問記憶體要快得多,
壓入和彈出堆疊資料

??pushq指令的功能是把資料壓入到堆疊上,而popq指令是彈出資料,這些指令都只有一個運算元——壓入的資料源和彈出的資料目的,
pushq %rbp等價于以下兩條指令:
subq $8,%rsp Decrement stack pointer movq %rbp,(%rsp) Store %rbp on stackpopq %rax等價于下面兩條指令:
mova (%rsp), %rax Read %rax from stack addq $8,%rsp Increment stack pointer
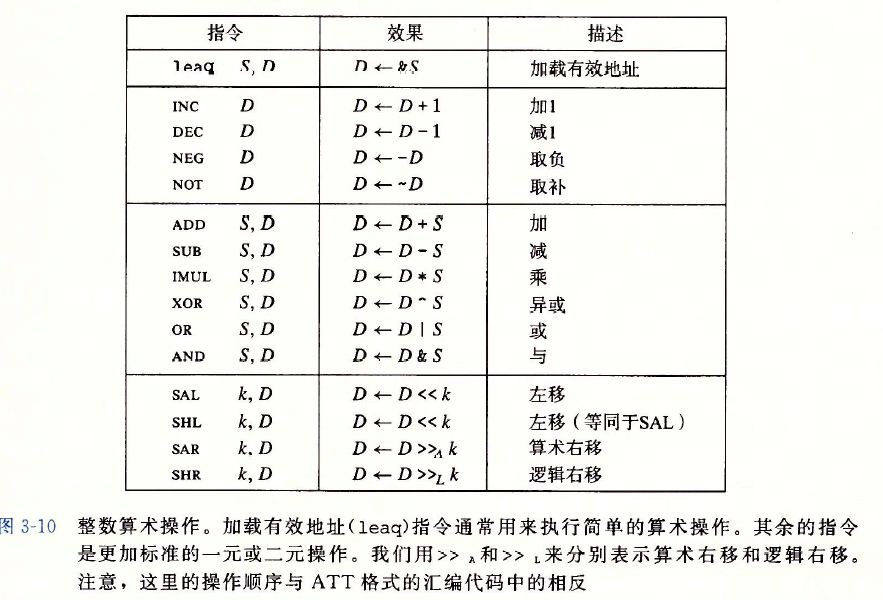
算數和邏輯操作
加載有效地址
??IA32指令集中有這樣一條加載有效地址指令leal,用法為leal S, D,效果是將S的地址存入D,是mov指令的變形,可是這條指令往往用在計算乘法上,GCC編譯器特別喜歡使用這個指令,比如下面的例子
leal (%eax, %eax, 2), %eax
??實作的功能相當于%eax = %eax * 3,括號中是一種比例變址尋址,將第一個數加上第二個數和第三個數的乘積作為地址尋址,leal的效果使源運算元正好是尋址得到的地址,然后將其賦值給%eax暫存器,為什么用這種方式算乘法,而不是用乘法指令imul呢?
??這是因為Intel處理器有一個專門的地址運算單元,使得leal的執行不必經過ALU,而且只需要單個時鐘周期,相比于imul來說要快得多,因此,對于大部分乘數為小常數的情況,編譯器都會使用leal完成乘法操作,
一元和二元操作
| 地址 | 值 |
|---|---|
| 0x100 | 0xFF |
| 0x108 | 0xAB |
| 0x110 | 0x13 |
| 0x118 | 0x11 |
| 暫存器 | 值 |
|---|---|
| %rax | 0x100 |
| %rcx | 0x1 |
| %rdx | 0x3 |
??看個例子應該就明白這些指令的含義了,不知道指令意思的,可以看運算元的格式這一節中總結的常見匯編指令的格式,
| 指令 | 目的 | 值 | 解釋 |
|---|---|---|---|
| addq %rcx,(%rax) | 0x100 | 0x100 | 將rcx暫存器的值(0x1)加到%rax地址處(0xFF) |
| subq %rdx,8(%rax) | 0x108 | 0xA8 | 從8(%rax)地址處取值(0XAB)并減去%rdx的值(0x3) |
| imulq $16,(%rax,%rdx,8) | 0x118 | 0x110 | (0x100+0x3 * 8) = 118.從118的地址取值并乘以10(16)結果為0x110 |
| incq 16(%rax) | 0x110 | 0x14 | %rax + 16 = 0x100+10 = 0x110,從0x110取值得0x13,結果+1為0x14, |
| decq %rcx | %rcx | 0x0 | 0x1-1 |
移位操作
??左移指令:SAL,SHL
??算術右移指令:SAR(填上符號位)
??邏輯右移指令:SHR(填上0)
??移位操作的目的運算元是一個暫存器或是一個記憶體位置,169

??C語言對應的匯編代碼


控制
條件碼
條件碼的定義:
??描述了最近的算識訓邏輯操作的屬性,可以檢測這些暫存器來執行條件分支指令,
常用的條件碼
??CF:進位標志,最近的操作使最高位產生了進位,可用來檢查無符號操作的溢位,
??ZF:零標志,最近的操作得出的結果為0,
??SF:符號標志,最近的操作得到的結果為負數,
??OF:溢位標志,最近的操作導致一個補碼溢位—正溢位或負溢位,
改變條件碼的指令
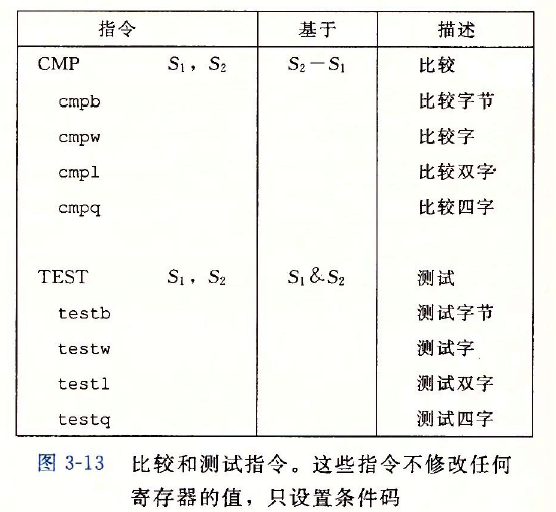
??cmp指令根據兩個運算元之差來設定條件碼,常用來比較兩個數,但是不會改變運算元,
??test指令用來測驗這個數是正數還是負數,是零還是非零,兩個運算元相同
test %rax,%rax //檢查%rax是負數、零、還是正數(%rax && %rax)
cmp %rax,%rdi //與sub指令類似,%rdi - %rax ,
??上表中除了leap指令,其他指令都會改變條件碼,
ⅩOR,進位標志和溢位標志會設定成0.對于移位操作,進位標志將設定為最后一個被移出的位,而溢位標志設定為0,INC和DEC指令會設定溢位和零標志,
訪問條件碼
訪問條件碼的三種方式
??1.可以根據條件碼的某種組合,將一個位元組設定為0或者1,
??2.可以條件跳轉到程式的某個其他的部分,
??3.可以有條件地傳送資料,
??對于第一種情況,常使用set指令來設定,set指令如下圖所示,
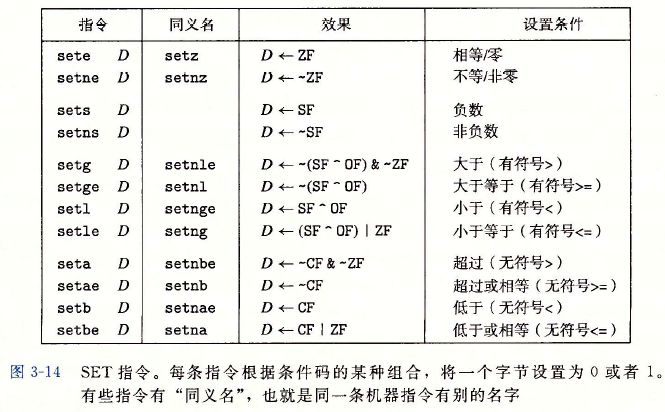
/* 計算a<b的匯編代碼 int comp(data_t a,data_t b) a in %rdi,b in %rsi */ comp: cmpq %rsi,%rdi setl %al movzbl %al,%eax retsetl %al 當a<b,設定%eax的低位為0或者1,
跳轉指令
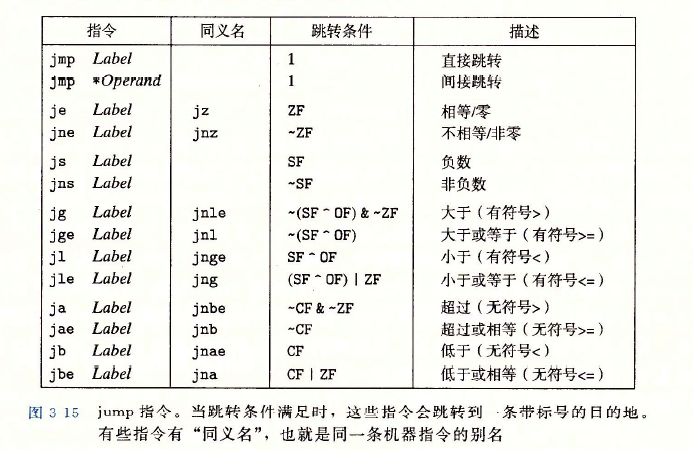
??上表中的有些指令是帶有后綴的,表示條件跳轉,下面解釋下這些后綴,有助于記憶,
??e == equal,ne == not equal,s == signed,ns == not signed,g == greater,ge == greater or equal,l == less,le == less or eauql,a == ahead,ae == ahead or equal,b == below,be == below or equal
??直接跳轉
jmp .L1 //直接給出標號,跳轉到標號處
??間接跳轉
jmp *%rax //用暫存器%rax中的值作為跳轉目標
jmp *(%rax) //以%rax中的值作為讀地址,從記憶體中讀出跳轉目標
跳轉指令的編碼
??通過看跳轉指令的編碼格式理解下程式計數器PC是如何實作跳轉的,
??匯編
movq %rdi, %rax
jmp .L2
.L3:
sarq %rax
.L2:
testq %rax, %rax
jg .L3
rep;ret
??反匯編
0:48 89 f8 mov %rdi,%raxrdi,
3:eb 03 jmp 8 <loop+0x8>
5:48 d1 f8 sar %rax
8:48 85 c0 test %rax %rax
b:71 f8 jg 5<loop+0x5>
d: f3 C3 repz rete
??右邊反匯編器產生的注釋中,第2行中跳轉指令的跳轉目標指明為0x8,第5行中跳轉指令的跳轉目標是0x5(反匯編器以十六進制格式給出所有的數字),不過,觀察指令的宇節編碼,會看到第一條跳轉指令的目標編碼(在第二個位元組中)為0x03.把它加上0×5,也就是下一條指令的地址,就得到跳轉目標地址0x8,也就是第4行指令的地址,
??類似,第二個跳轉指令的目標用單位元組、補碼表示編碼為0xf8(十進制-8),將這個數加上0xa(十進制13),即第6行指令的地址,我們得到0x5,即第3行指令的地址,
??這些例子說明,當執行PC相對尋址時,程式計數器的值是跳轉指令后面的那條指令的地址,而不是跳轉指令本身的地址,
條件控制實作條件分支

??上圖分別給出了C語言,goto表示,匯編語言的三種形式,這里使用goto陳述句,是為了構造描述匯編代碼程式控制流的C程式,
??匯編代碼的實作(圖3-16c)首先比較了兩個運算元(第2行),設定條件碼,如果比較的結果表明x大于或者等于y,那么它就會跳轉到第8行,增加全域變數 ge_cnt,計算x-y作為回傳值并回傳,由此我們可以看到 absdiff_se對應匯編代碼的控制流非常類似于gotodiff_ se的goto代碼,
??C語言中的if-else通用模版如下:

??對應的匯編代碼如下:

條件傳送實作條件分支

??GCC為該函式產生的匯編代碼如圖3-17c所示,它與圖3-17b中所示的C函式cmovdiff有相似的形式,研究這個C版本,我們可以看到它既計算了y-x,也計算了x-y,分別命名為rval和eval,然后它再測驗x是否大于等于y,如果是,就在函式回傳rval前,將eval復制到rval中,圖3-17c中的匯編代碼有相同的邏輯,關鍵就在于匯編代碼的那條 cmovge指令(第7行)實作了 cmovdiff的條件賦值(第8行),只有當第6行的cmpq指令表明一個值大于等于另一個值(正如后綴ge表明的那樣)時,才會把資料源暫存器傳送到目的,
??條件控制的匯編模版如下:

??實際上,基于條件資料傳送的代碼會比基于條件控制轉移的代碼性能要好,主要原因是處理器通過使用流水線來獲得高性能,處理器采用非常精密的分支預測邏輯來猜測每條跳轉指令是否會執行,只要它的猜測還比較可靠(現代微處理器設計試圖達到90%以上的成功率),指令流水線中就會充滿著指令,另一方面,錯誤預測一個跳轉,要求處理器丟掉它為該跳轉指令后所有指令已做的作業,然后再開始用從正確位置處起始的指令去填充流水線,這樣一個錯誤預測會招致很嚴重的懲罰,浪費大約15~30個時鐘周期,導致程式性能嚴重下降,
??使用條件傳送也不總是會提高代碼的效率,例如,如果 then expr或者 else expr的求值需要大量的計算,那么當相對應的條件不滿足時,這些作業就白費了,編譯器必須考慮浪費的計算和由于分支預測錯誤所造成的性能處罰之間的相對性能,說實話,編譯器井不具有足夠的資訊來做出可靠的決定;例如,它們不知道分支會多好地遵循可預測的模式,我們對GCC的實驗表明,只有當兩個運算式都很容易計算時,例如運算式分別都只是條加法指令,它才會使用條件傳送,根據我們的經驗,即使許多分支預測錯誤的開銷會超過更復雜的計算,GCC還是會使用條件控制轉移,
??所以,總的來說,條件資料傳送提供了一種用條件控制轉移來實作條件操作的替代策略,它們只能用于非常受限制的情況,但是這些情況還是相當常見的,而且與現代處理器的運行方式更契合,
回圈
??將回圈翻譯成匯編主要有兩種方法,第一種我們稱為跳轉到中間,它執行一個無條件跳轉跳到回圈結尾處的測驗,以此來執行初始的測驗,第二種方法叫guarded-do,首先用條件分支,如果初始條件不成立就跳過回圈,把代碼變換為do-whie回圈,當使用較髙優化等級編譯時,例如使用命令列選項-O1,GCC會采用這種策略,
跳轉到中間
??如下圖所示為while回圈寫的計算階乘的代碼,可以看到編譯器使用了跳轉到中間的翻譯方法,在第3行用jmp跳轉到以標號L5開始的測驗,如果n滿足要求就執行回圈,否則就退出,

guarded-do
??下圖為使用第二種方法編譯的匯編代碼,編譯時是用的是-O1,GCC就會采用這種方式編譯回圈,

??上面介紹的是while回圈和do-while回圈的兩種編譯模式,根據GCC不同的優化結果會得到不同的匯編代碼,實際上,for回圈產生的匯編代碼也是以上兩種匯編代碼中的一種,for回圈的通用形式如下所示,

??選擇跳轉到中間策略會得到如下goto代碼:

??guarded-do策略會得到如下goto代碼:

suitch陳述句
??switch陳述句可以根據一個整數索引值進行多重分支,它們不僅提高了C代碼的可讀性而且通過使用跳轉表這種資料結構使得實作更加高效,跳轉表是一個陣列,表項i是一個代碼段的地址,這個代碼段實作當開關索引值等于i時程式應該采取的動作,
??程式代碼用開關索引值來執行一個跳轉表內的陣列參考,確定跳轉指令的目標,和使用組很長的if-else陳述句相比,使用跳轉表的優點是執行開關陳述句的時間與開關情況的數量無關,GCC根據開關情況的數量和開關情況值的稀疏程度來翻譯開關陳述句,當開關情況數量比較多(例如4個以上),并且值的范圍跨度比較小時,就會使用跳轉表,

??原始的C代碼有針對值100、102104和106的情況,但是開關變數n可以是任意整數,編譯器首先將n減去100,把取值范圍移到0和6之間,創建一個新的程式變數,在我們的C版本中稱為 index,補碼表示的負數會映射成無符號表示的大正數,利用這一事實,將 index看作無符號值,從而進一步簡化了分支的可能性,因此可以通過測驗 index是否大于6來判定index是否在0~6的范圍之外,在C和匯編代碼中,根據 index的值,有五個不同的跳轉位置:loc_A(.L3),loc_B(.L5),loc_C(.L6),loc_D(.L7)和 loc_def(.L8),最后一個是默認的目的地址,每個標號都標識一個實作某個情況分支的代碼塊,在C和匯編代碼中,程式都是將 index和6做比較,如果大于6就跳轉到默認的代碼處,

??執行 switch陳述句的關鍵步驟是通過跳轉表來訪問代碼位置,在C代碼中是第16行一條goto陳述句參考了跳轉表jt,GCC支持計算goto,是對C語言的擴展,在我們的匯編代碼版本中,類似的操作是在第5行,jmp指令的運算元有前綴‘ * ’,表明這是一個間接跳轉,運算元指定一個記憶體位置,索引由暫存器%rsi給出,這個暫存器保存著 index的值,
??C代碼將跳轉表宣告為一個有7個元素的陣列,每個元素都是一個指向代碼位置的指標,這些元素跨越 index的值0 ~ 6,對應于n的值100~106,可以觀察到,跳轉表對重復情況的處理就是簡單地對表項4和6用同樣的代碼標號(loc_D),而對于缺失的情況的處理就是對表項1和5使用默認情況的標號(loc_def),
??在匯編代碼中,跳轉表宣告為如下形式

??(.rodata段的詳細解釋在我總結的嵌入式軟體開發筆試面試知識點中有詳細介紹)
已知switch匯編代碼,如何利用匯編語言和跳轉表的結構推斷出switch的C語言結構?
??關于C語言的switch陳述句,需要重點確定的有跳轉表的大小,跳轉范圍,那些case是缺失的,那些是重復的,下面我們一 一確定,
??這些表宣告中,從圖3-23的匯編第1行可以知道,n的起始計數為100,由第二行可以知道,變數和6進行比較,說明跳轉表索引偏移范圍為0 ~ 6,對應為100 ~106,從.quad .L3開始,由上到下,依次編號為0,1,2,3,4,5,6,其中由圖3-23的ja .L8可知,大于6時就跳轉到.L8,那么跳轉表中編號為1和5的都是跳轉的默認位置,因此,編號為1和5的為缺失的情況,即沒有101和105的選項,而編號為4和6的都跳轉到了.L7,說明兩者是對應于100+4=104,100+6=106,剩下的情況0,2,3依次編號為100,102,103,至此我們就得出了switch的編號情況,一共有6項,100,102,103,104,106,default,剩下的關于每種case的C語言內容就可以根據匯編代碼寫出來了,
程序
運行時堆疊
??C語言程序呼叫機制的一個關鍵特性(大多數其他語言也是如此)在于使用了堆疊資料結構提供的后進先出的記憶體管理原則,假如在程序P呼叫程序Q時,可以看到當Q在執行時,P以及所有在向上追溯到P的呼叫鏈中的程序,都是暫時被掛起的,當Q運行時,它只需要為區域變數分配新的存盤空間,或者設定到另一個程序的呼叫,另一方面,當Q回傳時,任何它所分配的區域存盤空間都可以被釋放,因此,程式可以用堆疊來管理它的程序所需要的存盤空間,堆疊和程式暫存器存放著傳遞控制和資料、分配記憶體所需要的資訊,當P呼叫Q時,控制和資料資訊添加到堆疊尾,當P回傳時,這些資訊會釋放掉,
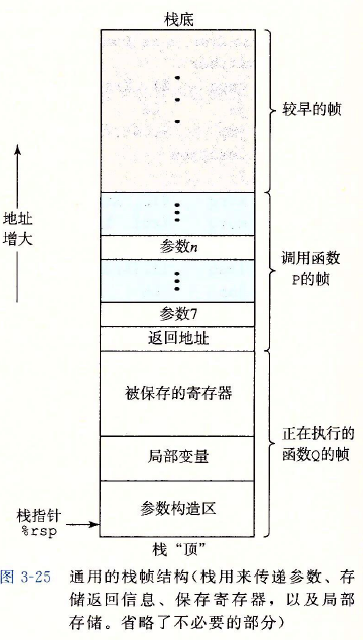
??x86-64的堆疊向低地址方向增長,而堆疊指標號%rsp指向堆疊頂元素,可以用 pushq和popq指令將資料存人堆疊中或是從堆疊中取出,將堆疊指標減小一個適當的量可以為沒有指定初始值的資料在堆疊上分配空間,類似地,可以通過增加堆疊指標來釋放空間,
??程序P可以傳遞最多6個整數值(也就是指標和整數),但是如果Q需要更多的引數,P可以在呼叫Q之前在自己的堆疊幀(也就是記憶體)里存盤好這些引數,
轉移控制
??將控制從函式轉移到函式Q只需要簡單地把程式計數器(PC)設定為Q的代碼的起始位置,不過,當稍后從Q回傳的時候,處理器必須記錄好它需要繼續P的執行的代碼位置,在x86-64機器中,這個資訊是用指令call Q呼叫程序Q來記錄的,該指令會把地址A壓入堆疊中,并將PC設定為Q的起始地址,壓入的地址A被稱為回傳地址,是緊跟在call指令后面的那條指令的地址,對應的指令ret會從堆疊中彈出地址A,并把PC設定為A,

??下面看個例子
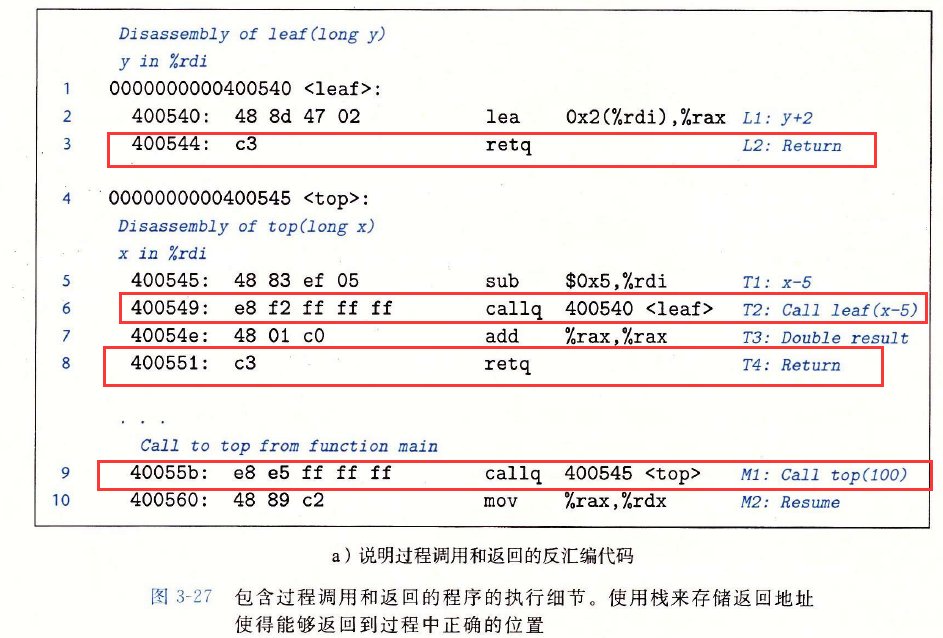
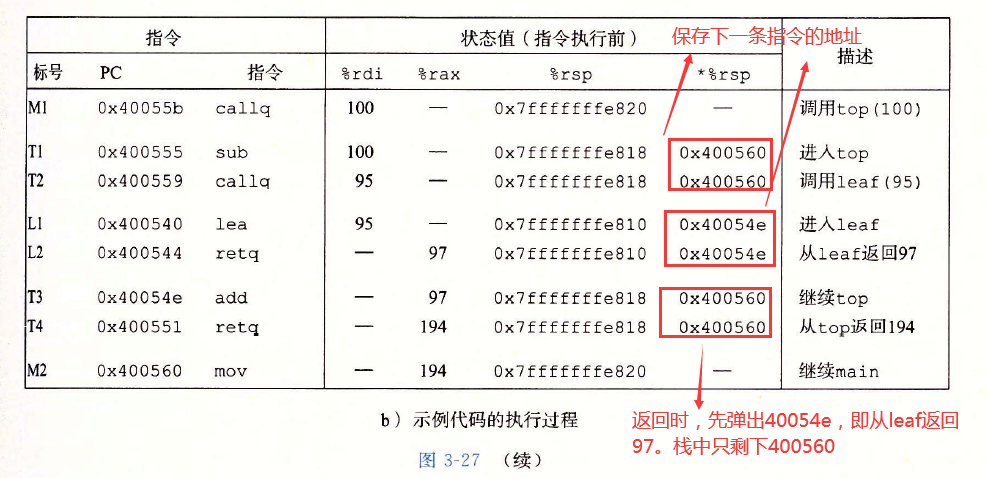
??main呼叫top(100),然后top呼叫leaf(95),函式leaf向top回傳97,然后top向main回傳194.前面三列描述了被執行的指令,包括指令標號、地址和指令型別,后面四列給出了在該指令執行前程式的狀態,包括暫存器%rdi、%rax和%rsp的內容,以及位于堆疊頂的值,
??leaf的指令L1將%rax設定為97,也就是要回傳的值,然后指令L2回傳,它從堆疊中彈出0×400054e,通過將PC設定為這個彈出的值,控制轉移回top的T3指令,程式成功完成對leaf的呼叫,回傳到top,
??指令T3將%rax設定為194,也就是要從top回傳的值,然后指令T4回傳,它從堆疊中彈出0×4000560,因此將PC設定為main的M2指令,程式成功完成對top的呼叫,回傳到main,可以看到,此時堆疊指標也恢復成了0x7fffffffe820,即呼叫top之前的值,
??這種把回傳地址壓入堆疊的簡單的機制能夠讓函式在稍后回傳到程式中正確的點,C語言標準的呼叫/回傳機制剛好與堆疊提供的后進先出的記憶體管理方法吻合,
資料傳送
??X86-64中,可以通過暫存器來傳遞最多6個引數,暫存器的使用是有特殊順序的,如下表所示,會根據引數的順序為其分配暫存器,
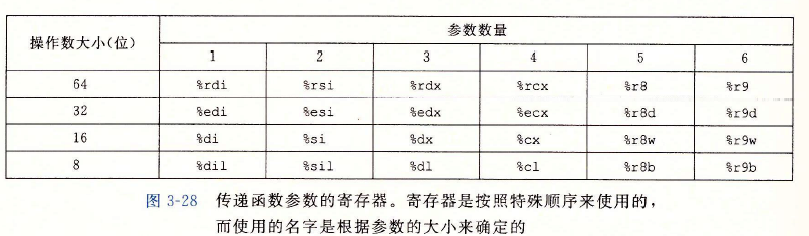
??當傳遞引數超過6個時,會把大于6個的部分放在堆疊上,
??如下圖所示的部分,紅框內的引數就是存盤在堆疊上的,

堆疊上的區域存盤
??通常來說,不需要超出暫存器大小的本地存盤區域,不過有些時候,區域資料必須存放在記憶體中,常見的情況包括:1.暫存器不足夠存放所有的本地資料,
2.對一個區域變數使用地址運算子‘&‘,因此必須能夠為它產生一個地址,3.某些區域變數是陣列或結構,因此必須能夠通過陣列或結構參考被訪問到,
??下面看一個例子,


??第二行的subq指令將堆疊指標減去32,實際上就是分配了32個位元組的記憶體空間,在堆疊指標的基礎上,分別+24,+20,+18,+17,用來存放1,2,3,4的值,在第7行中,使用leaq生成到17(%rsp)的指標并賦值給%rax,接著在堆疊指標基礎上+8和+16的位置存放引數7和引數8,而引數1-引數6分別放在6個暫存器中,堆疊幀的結構如下圖所示,
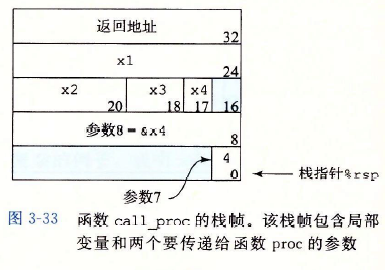
??上述匯編中第2-15行都是在為呼叫proc做準備(為區域變數和函式建立堆疊幀,將函式加載到暫存器),當準備作業完成后,就會開始執行proc的代碼,當程式回傳call_proc時,代碼會取出4個區域變數(第17~20行),并執行最終的計算,在程式結束前,把堆疊指標加32,釋放這個堆疊幀,
暫存器中的區域存盤
??暫存器組是唯一被所有程序共享的資源,因此,在某些呼叫程序中,我們要不同程序呼叫的暫存器不能相互影響,
??根據慣例,暫存器%rbx、%rbp和%r12~%r15被劃分為被呼叫者保存暫存器,當程序P呼叫程序Q時,Q必須保存這些暫存器的值,保證它們的值在Q回傳到P時與Q被呼叫時是一樣的,程序Q保存一個暫存器的值不變,要么就是根本不去改變它,要么就是把原始值壓入堆疊中,有了這條慣例,P的代碼就能安全地把值存在被呼叫者保存暫存器中(當然,要先把之前的值保存到堆疊上),呼叫Q,然后繼續使用暫存器中的值,
??下面看個例子,

??可以看到GCC生成的代碼使用了兩個被呼叫者保存暫存器:%rbp保存x和%rbx保存計算出來的Q(y)的值,在函式的開頭,把這兩個暫存器的值保存到堆疊中(第2~3行),在第一次呼叫Q之前,把引數ⅹ復制到%rbp(第5行),在第二次呼叫Q之前,把這次呼叫的結果復制到%rbx (第8行),在函式的結尾,(第13~14行),把它們從堆疊中彈出,恢復這兩個被呼叫者保存寄器的值,注意它們的彈壓入順序,說明了堆疊的后進先出規則,
遞回程序
??根據之前的內容可以知道,多個程序呼叫在堆疊中都有自己的私有空間,多個未完成呼叫的區域變數不會相互影響,遞回本質上也是多個程序的相互呼叫,如下所示為一個計算階乘的遞回呼叫,

??上圖給出了遞回的階乘函式的C代碼和生成的匯編代碼,可以看到匯編代碼使用暫存器%rbx來保存引數n,先把已有的值保存在堆疊上(第2行),隨后在回傳前恢復該值(第11行),根據堆疊的使用特性和暫存器保存規則,可以保證當遞回呼叫 refact(n-1)回傳時(第9行),(1)該次呼叫的結果會保存在暫存器號%rax中,(2)引數n的值仍然在暫存器各%rbx中,把這兩個值相乘就能得到期望的結果,
陣列分配和訪問
基本原則
??在機器代碼級是沒有陣列這一更高級的概念的,只是你將其視為位元組的集合,這些位元組的集合是在連續位置上存盤的,結構也是如此,它就是作為位元組集合來分配的,然后,C 編譯器的作業就是生成適當的代碼來分配該記憶體,從而當你去參考結構或陣列的某個元素時,去獲取正確的值,
??資料型別T和整型常數N,宣告一個陣列T A[N],起始位置表示為\({X_A}\).這個宣告有兩個效果,首先,它在記憶體中分配一個\(L \bullet N\)位元組的連續區域,這里L是資料型別T的大小(單位為位元組),其次,它引入了識別符號A,可以用來作A為指向陣列開頭的指標,這個指標的值就是\({X_A}\),可以用0~N-1的整數索引來訪問該陣列元素,陣列元素i會被存放在地址為\({X_A} + L \bullet i\)的地方,
char A[12];
char *B[8];
char C[6];
char *D[5];
陣列 元素大小 總的大小 起始地址 元素i A 1 12 \({X_A}\) \({X_A}+i\) B 8 64 \({X_B}\) \({X_B}+8i\) C 4 24 \({X_C}\) \({X_C}+4i\) D 8 40 \({X_D}\) \({X_D}+8i\)
??指標運算
??假設整型陣列E的起始地址和整數索引i分別存放在暫存器是%rdx和%rcx中,下面是一些與E有關的運算式,我們還給出了每個運算式的匯編代碼實作,結果存放在暫存器號%eax(如果是資料)或暫存器號%rax(如果是指標)中,

二維陣列
??對于一個宣告為T D[R] [C]的二維陣列來說,陣列D[i] [j]的記憶體地址為\({X_D} + L(C \bullet i + j)\),
??這里,L是資料型別T以位元組為單位的大小,假設\({X_A}\)、i和j分別在暫存器%rdi、%rsi和%rdx中,然后,可以用下面的代碼將陣列元素A[i] [j]復制到暫存器%eax中:
/*A in %rdi, i in %rsi, and j in %rdx*/
leaq (%rsi,%rsi,2), %rax //Compute 3i
leaq (%rdi,%rax,4),%rax //Compute XA+ 12i
movl (7rax, rdx, 4), %eax //Read from M[XA+ 12i+4j]
異質的資料結構
結構體
??C語言的 struct宣告創建一個資料型別,將可能不同型別的物件聚合到一個物件中,結構的所有組成部分都存放在記憶體中一段連續的區域內,而指向結構的指標就是結構第個位元組的地址,編譯器維護關于每個結構型別的資訊,指示每個欄位( field)的位元組偏移,它以這些偏移作為記憶體參考指令中的位移,從而產生對結構元素的參考,
??結構體在記憶體中是以偏移的方式存盤的,具體可以看這個文章,Linux內核中container_of宏的詳細解釋,
struct rec {
int i;
int j;
int a[2];
int *p;
};
??這個結構包括4個欄位:兩個4位元組int、一個由兩個型別為int的元素組成的陣列和一個8位元組整型指標,總共是24個位元組,

??看匯編代碼也可以看出,結構體成員的訪問是基地址加上偏移地址的方式,例如,假設 struct rec*型別的變數r放在暫存器%rdi中,那么下面的代碼將元素r->i復制到元素r->j:
/*Registers:r in %rdi,i %rsi */
movl (%rdi), %eax //Get r->i
movl %eax, 4(%rdi) //Store in r-27
leaq 8(%rdi,%rsi,4),//%rax 得到一個指標,8+4*%rsi,&(r->a[i])
資料對齊
??關于位元組對齊的相關內容見我整理的《嵌入式軟體筆試面試知識點總結》里面詳細介紹了位元組對齊的相關內容,
在機器級程式中將控制和程式結合起來
理解指標
??關于指標的幾點說明:
??1.每個指標都對應一個型別
int *ip;//ip為一個指向int型別物件的指標 char **cpp;//cpp為指向指標的指標,即cpp指向的本身就是一個指向char型別物件的指標 void *p;//p為通用指標,malloc的回傳值為通用指標,通過強制型別轉換可以轉換成我們需要的指標型別
??2.每個指標都有一個值,這個值可以是某個指定型別的物件的地址,也可以是一個特殊的NULL(0),
??3.指標用&運算子創建,在匯編代碼中,用leaq指令計算記憶體參考的地址,
int i = 0; int *p = &i;//取i的地址賦值給p指標
??4.* 運算子用于間接參考指標,參考的結果是一個具體的數值,它的型別與該指標的型別一致,
??5.陣列與指標緊密聯系,但是又有所區別,
int a[10] ={0};一個陣列的名字可以像一個指標變數一樣參考(但是不能修改),陣列參考(例如a[5]與指標運算和間接參考(例如*(a+5))有一樣的效果,
陣列參考和指標運算都需要用物件大小對偏移量進行伸縮,當我們寫運算式a+i,這里指標p的值為a,得到的地址計算為a+L * i,這里L是與a相關聯的資料型別的大小,
陣列名對應的是一塊記憶體地址,不能修改,指標指向的是任意一塊記憶體,其值可以隨意修改,
??6.將指標從一種型別強制轉換成另一種型別,只改變它的型別,而不改變它的值,強制型別轉換的一個效果是改變指標運算的伸縮,例如,如果a是一個char * 型別的指標,它的值為a,a+7結果為a+7 * 1,而運算式(int* )p+7結果為p+4 * 7,
記憶體越界參考
??C對于陣列參考不進行任何邊界檢查,而且區域變數和狀態資訊(例如保存的暫存器值和回傳地址)都存放在堆疊中,這兩種情況結合到一起就能導致嚴重的程式錯誤,對越界的陣列元素的寫操作會破壞存盤在堆疊中的狀態資訊,當程式使用這個被破壞的狀態,就會出現很嚴重的錯誤,一種特別常見的狀態破壞稱為緩沖區溢位( buffer overflow),


??上述C代碼,buf只分配了8個位元組的大小,任何超過7位元組的都會使的陣列越界,
??輸入不同數量的字串會發生不同的錯誤,具體可以參考下圖,

??echo函式的堆疊分布如下圖所示,
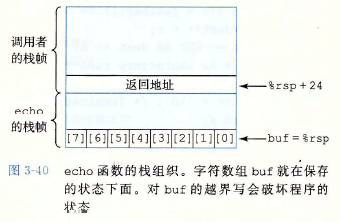
??字串到23個字符之前都沒有嚴重的后果,但是超過以后,回傳指標的值以及更多可能的保存狀態會被破壞,如果存盤的回傳地址的值被破壞了,那么ret指令(第8行)會導致程式跳轉到一個完全意想不到的位置,如果只看C代碼,根本就不可能看出會有上面這些行為,只有通過研究機器代碼級別旳程式才能理解像gets這樣的函式進行的記憶體越界寫的影響,
浮點代碼
??計算機中的浮點數可以說是"另類"的存在,每次提到資料相關的內容時,浮點數總是會被單獨拿出來說,同樣,在匯編中浮點數也是和其他型別的資料有所差別的,我們需要考慮以下幾個方面:1.如何存盤和訪問浮點數值,通常是通過某種暫存器方式來完成2.對浮點資料操作的指令3.向函式傳遞浮點數引數和從函式回傳浮點數結果的規則,4.函式呼叫程序中保存暫存器的規則—例如,一些暫存器被指定為呼叫者保存,而其他的被指定為被呼叫者保存,
??X86-64浮點數是基于SSE或AVX的,包括傳遞程序引數和回傳值的規則,在這里,我們講解的是基于AVX2,在利用GCC進行編譯時,加上-mavx2,GCC會生成AVX2代碼,
??如下圖所示,AVX浮點體系結構允許資料存盤在16個YMM暫存器中,它們的名字為%ymm0~%ymm15,每個YMM暫存器都是256位(32位元組),當對標量資料操作時,這些暫存器只保存浮點數,而且只使用低32位(對于float)或64位(對于 double),匯編代碼用暫存器的 SSE XMM暫存器名字%xmm0~%xmm15來參考它們,每個XMM暫存器都是對應的YMM暫存器的低128位(16位元組),

???其實浮點數的匯編指令和整數的指令都是差不多的,不需要都記住,用到的時候再查詢就可以了,
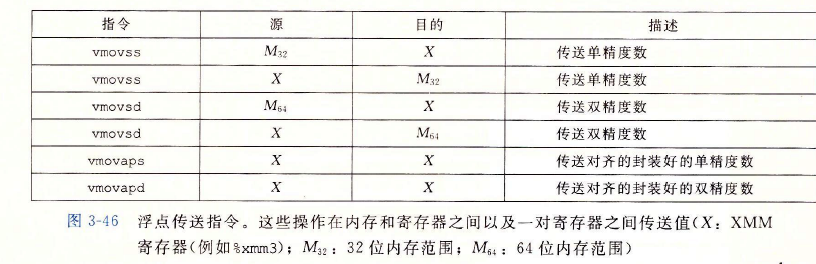
資料傳送指令
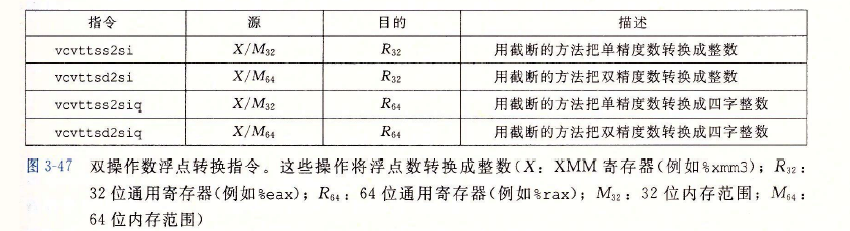
雙運算元浮點轉換指令
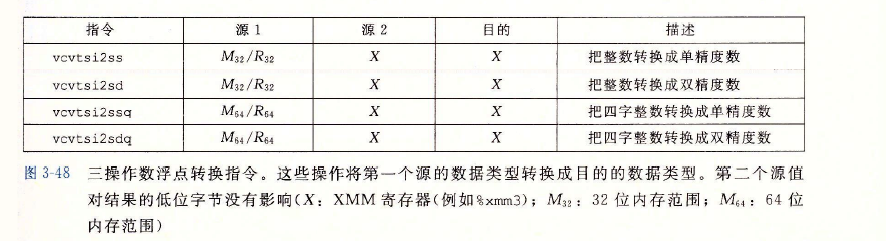
三運算元浮點轉換指令
標量浮點算術運算

浮點數的位級操作

比較浮點數值的指令

??在本章中,我們了解了C語言提供的抽象層下面的東西,通過讓編譯器產生機器級程式的匯編代碼表示,我們了解了編譯器和它的優化能力,以及機器、資料型別和指令集,本章要求我們要能閱讀和理解編譯器產生的機器級代碼,機器指令并不需要都記住,在需要的時候查就可以了,Arm的指令集和X86指令集大同小異,做嵌入式軟體開發掌握常用的Arm指令集就可以,嵌入式軟體開發知識點詳細介紹了常用的Arm指令集及其含義,有需要的可以關注我的公眾號領取,
??養成習慣,先贊后看!如果覺得寫的不錯,歡迎關注,點贊,轉發,謝謝!
如遇到排版錯亂的問題,可以通過以下鏈接訪問我的CSDN,
CSDN:CSDN搜索“嵌入式與Linux那些事”
歡迎歡迎關注我的公眾號:嵌入式與Linux那些事,領取秋招筆試面試大禮包(華為小米等大廠面經,嵌入式知識點總結,筆試題目,簡歷模版等)和2000G學習資料,

轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/231920.html
標籤:其他