在實際的作業中,我們可能會經常使用鏈表結構來存盤資料,特別是嵌入式開發,經常會使用linux內核最經典的雙向鏈表 list_head,本篇文章詳細介紹了Linux內核的通用鏈表是如何實作的,對于經常使用的函式都給出了詳細的說明和測驗用例,并且移植了Linux內核的鏈表結構,在任意平臺都可以方便的呼叫內核已經寫好的函式,建議收藏,以備不時之需!
@
目錄- 鏈表簡介
- 單鏈表
- 雙鏈表
- 回圈鏈表
- Linux內核中的鏈表
- 鏈表的定義
- 鏈表的初始化
- 內核實作
- 說明
- 舉例
- 鏈表增加節點
- 內核實作
- 說明
- 舉例
- 鏈表洗掉節點
- 內核實作
- 說明
- 舉例
- 鏈表替換節點
- 內核實作
- 說明
- 舉例
- 鏈表洗掉并插入節點
- 內核實作
- 說明
- 舉例
- 鏈表的合并
- 內核實作
- 說明
- 用例
- 鏈表的遍歷
- 內核實作
- 說明
- 舉例
- 疑惑解答
- list.h移植原始碼
鏈表簡介
??鏈表是一種常用的組織有序資料的資料結構,它通過指標將一系列資料節點連接成一條資料鏈,是線性表的一種重要實作方式,相對于陣列,鏈表具有更好的動態性,建立鏈表時無需預先知道資料總量,可以隨機分配空間,可以高效地在鏈表中的任意位置實時插入或洗掉資料,
??通常鏈表資料結構至少應包含兩個域:資料域和指標域,資料域用于存盤資料,指標域用于建立與下一個節點的聯系,按照指標域的組織以及各個節點之間的聯系形式,鏈表又可以分為單鏈表、雙鏈表、回圈鏈表等多種型別,下面分別給出這幾類常見鏈表型別的示意圖:
單鏈表
??單鏈表是最簡單的一類鏈表,它的特點是僅有一個指標域指向后繼節點(next),因此,對單鏈表的遍歷只能從頭至尾(通常是NULL空指標)順序進行,

雙鏈表
??通過設計前驅和后繼兩個指標域,雙鏈表可以從兩個方向遍歷,這是它區別于單鏈表的地方,如果打亂前驅、后繼的依賴關系,就可以構成"二叉樹";如果再讓首節點的前驅指向鏈表尾節點、尾節點的后繼指向首節點,就構成了回圈鏈表;如果設計更多的指標域,就可以構成各種復雜的樹狀資料結構,

回圈鏈表
??回圈鏈表的特點是尾節點的后繼指向首節點,前面已經給出了雙鏈表的示意圖,它的特點是從任意一個節點出發,沿兩個方向的任何一個,都能找到鏈表中的任意一個資料,如果去掉前驅指標,就是單回圈鏈表,

??關于鏈表的更詳細的內容可以看這兩篇博客
史上最全單鏈表的增刪改查反轉等操作匯總以及5種排序演算法
詳解雙向鏈表的基本操作.
Linux內核中的鏈表
??上面介紹了普通鏈表的實作方式,可以看到資料域都是包裹在節點指標中的,通過節點指標訪問下一組資料,但是 Linux內核的鏈表實作可以說比較特殊,只有前驅和后繼指標,而沒有資料域,鏈表的頭檔案是在include/list.h(Linux2.6內核)下,在實際作業中,也可以將內核中的鏈表拷貝出來供我們使用,就需不要造輪子了,
鏈表的定義
??內核鏈表只有前驅和后繼指標,并不包含資料域,這個鏈表具備通用性,使用非常方便,因此可以很容易的將內核鏈表結構體包含在任意資料的結構體中,非常容易擴展,我們只需要將鏈表結構體包括在資料結構體中就可以,下面看具體的代碼,
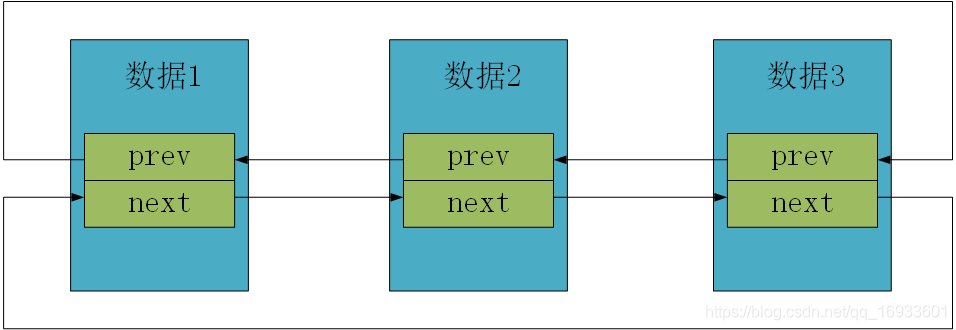
??內核鏈表的結構
//鏈表結構
struct list_head
{
struct list_head *prev;
struct list_head *next;
};
??當需要用內核的鏈表結構時,只需要在資料結構體中定義一個struct list_head{}型別的結構體成員物件就可以,這樣,我們就可以很方便地使用內核提供給我們的一組標準介面來對鏈表進行各種操作,我們定義一個學生結構體,里面包含學號和數學成績,結構體如下:
struct student
{
struct list_head list;//暫且將鏈表放在結構體的第一位
int ID;
int math;
};
鏈表的初始化
內核實作
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
說明
??INIT_LIST_HEAD 和LIST_HEAD都可以初始化鏈表,二者的區別如下:
??LIST_HEAD(stu_list) 初始化鏈表時會順便創建鏈表物件,
//LIST_HEAD(stu_list)展開如下
struct list_head stu_list= { &(stu_list), &(stu_list) };
??INIT_LIST_HEAD(&stu1.stu_list) 初始化鏈表時需要我們已經有了一個鏈表物件stu1_list,
??`我們可以看到鏈表的初始化其實非常簡單,就是讓鏈表的前驅和后繼都指向了自己,
舉例
INIT_LIST_HEAD(&stu1.stu_list);
鏈表增加節點
內核實作
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
#ifndef CONFIG_DEBUG_LIST
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
#else
extern void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next);
#endif
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
#ifndef CONFIG_DEBUG_LIST
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
#else
extern void list_add(struct list_head *new, struct list_head *head);
#endif
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
說明
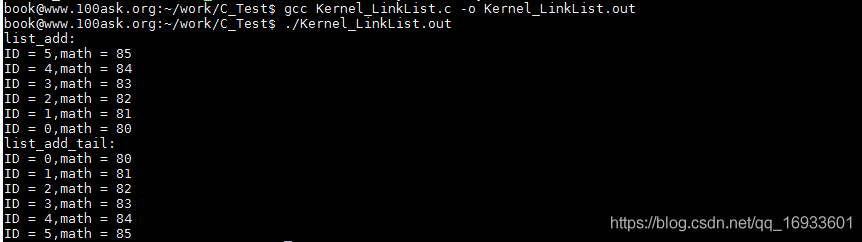
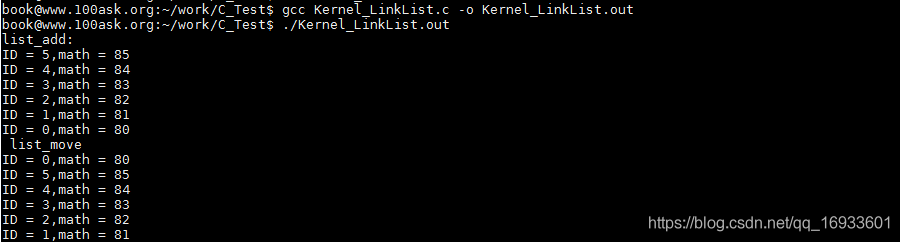
??list_add為頭插法,即在鏈表頭部(head節點)前插入節點,最后列印的時候,先插入的先列印,后插入的后列印,例如原鏈表為1->2->3,使用list_add插入4后變為,4->1->2->3,因為鏈表時回圈的,而且通常沒有首尾節點的概念,所以可以把任何一個節點當成head,
??同理,list_add_tail為尾插法,即在鏈表尾部(head節點)插入節點,最后列印的時候,先插入的后列印,后插入的先列印,例如原鏈表為1->2->3,使用list_add_tail插入4后變為,1->2->3->4,
舉例
#include "mylist.h"
#include <stdio.h>
#include <stdlib.h>
struct student
{
struct list_head stu_list;
int ID;
int math;
};
int main()
{
struct student *p;
struct student *q;
struct student stu1;
struct student stu2;
struct list_head *pos;
//鏈表的初始化
INIT_LIST_HEAD(&stu1.stu_list);
INIT_LIST_HEAD(&stu2.stu_list);
//頭插法創建stu stu1鏈表
for (int i = 0;i < 6;i++) {
p = (struct student *)malloc(sizeof(struct student));
p->ID=i;
p->math = i+80;
//頭插法
list_add(&p->stu_list,&stu1.stu_list);
//尾插法
//list_add_tail(&p->list,&stu.list);
}
printf("list_add: \r\n");
list_for_each(pos, &stu1.stu_list) {
printf("ID = %d,math = %d\n",((struct student*)pos)->ID,((struct student*)pos)->math);
}
//尾插法創建stu stu1鏈表
for (int i = 0;i < 6;i++) {
p = (struct student *)malloc(sizeof(struct student));
p->ID=i;
p->math = i+80;
//頭插法
//list_add(&p->stu_list,&stu1.stu_list);
//尾插法
list_add_tail(&p->stu_list,&stu2.stu_list);
}
printf("list_add_tail: \r\n");
list_for_each(pos, &stu2.stu_list) {
printf("ID = %d,math = %d\n",((struct student*)pos)->ID,((struct student*)pos)->math);
}
return 0;
}
鏈表洗掉節點
內核實作
//原來內核設定的洗掉鏈表后的指向位置
// # define POISON_POINTER_DELTA 0
// #define LIST_POISON1 ((void *) 0x00100100 + POISON_POINTER_DELTA)
// #define LIST_POISON2 ((void *) 0x00200200 + POISON_POINTER_DELTA)
//這里我們設定為NULL 內核中定義NULL 為0
#define NULL ((void *)0)
#define LIST_POISON1 NULL
#define LIST_POISON2 NULL
/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
#ifndef CONFIG_DEBUG_LIST
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
#else
extern void list_del(struct list_head *entry);
#endif
說明
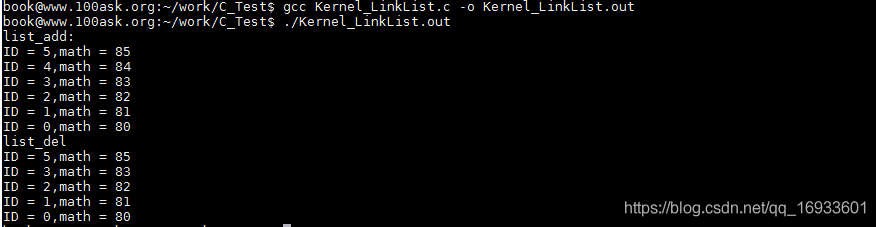
??鏈表洗掉之后,entry的前驅和后繼會分別指向LIST_POISON1和LIST_POISON2,這個是內核設定的一個區域,但是在本例中將其置為了NULL,
舉例
#include "mylist.h"
#include <stdio.h>
#include <stdlib.h>
struct student
{
struct list_head stu_list;
int ID;
int math;
};
int main()
{
struct student *p;
struct student *q;
struct student stu1;
struct student stu2;
struct list_head *pos1;
//注意這里的pos2,后面會解釋為什么定義為
struct student *pos2;
//stu = (struct student*)malloc(sizeof(struct student));
//鏈表的初始化
INIT_LIST_HEAD(&stu1.stu_list);
INIT_LIST_HEAD(&stu2.stu_list);
LIST_HEAD(stu);
//頭插法創建stu stu1鏈表
for (int i = 0;i < 6;i++) {
p = (struct student *)malloc(sizeof(struct student));
p->ID=i;
p->math = i+80;
//頭插法
list_add(&p->stu_list,&stu1.stu_list);
//尾插法
//list_add_tail(&p->list,&stu.list);
}
printf("list_add: \r\n");
list_for_each(pos1, &stu1.stu_list) {
printf("ID = %d,math = %d\n",((struct student*)pos1)->ID,((struct student*)pos1)->math);
}
//洗掉
list_for_each_entry(pos2,&stu1.stu_list,stu_list) {
if (pos2->ID == 4) {
list_del(&pos2->stu_list);
break;
}
}
printf("list_del\r\n");
list_for_each_entry(pos2,&stu1.stu_list,stu_list) {
printf("ID = %d,math = %d\n",pos2->ID,pos2->math);
}
return 0;
}
鏈表替換節點
內核實作
/**
* list_replace - replace old entry by new one
* @old : the element to be replaced
* @new : the new element to insert
*
* If @old was empty, it will be overwritten.
*/
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
static inline void list_replace_init(struct list_head *old,
struct list_head *new)
{
list_replace(old, new);
INIT_LIST_HEAD(old);//重新初始化
}
說明
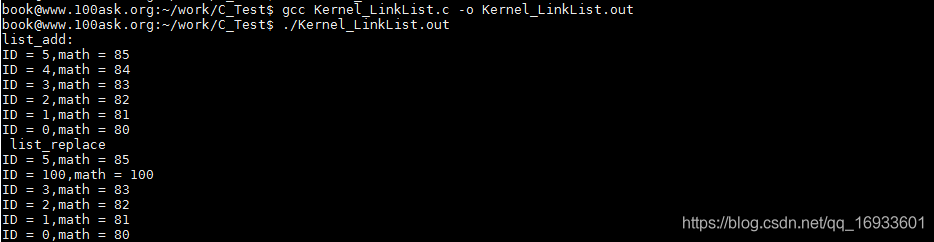
??list_replace使用新的節點替換舊的節點,
??list_replace_init與list_replace不同之處在于,list_replace_init會將舊的節點重新初始化,讓前驅和后繼指向自己,
舉例
#include "mylist.h"
#include <stdio.h>
#include <stdlib.h>
struct student
{
struct list_head stu_list;
int ID;
int math;
};
int main()
{
struct student *p;
struct student *q;
struct student stu1;
struct student stu2;
struct list_head *pos1;
struct student *pos2;
struct student new_obj={.ID=100,.math=100};
//stu = (struct student*)malloc(sizeof(struct student));
//鏈表的初始化
INIT_LIST_HEAD(&stu1.stu_list);
INIT_LIST_HEAD(&stu2.stu_list);
LIST_HEAD(stu);
//頭插法創建stu stu1鏈表
for (int i = 0;i < 6;i++) {
p = (struct student *)malloc(sizeof(struct student));
p->ID=i;
p->math = i+80;
//頭插法
list_add(&p->stu_list,&stu1.stu_list);
//尾插法
//list_add_tail(&p->list,&stu.list);
}
printf("list_add: \r\n");
list_for_each(pos1, &stu1.stu_list) {
printf("ID = %d,math = %d\n",((struct student*)pos1)->ID,((struct student*)pos1)->math);
}
//替換
list_for_each_entry(pos2,&stu1.stu_list,stu_list) {
if (pos2->ID == 4) {
list_replace(&pos2->stu_list,&new_obj.stu_list);
break;
}
}
printf("list_replace\r\n");
list_for_each_entry(pos2,&stu1.stu_list,stu_list) {
printf("ID = %d,math = %d\n",pos2->ID,pos2->math);
}
return 0;
}
鏈表洗掉并插入節點
內核實作
/**
* list_move - delete from one list and add as another's head
* @list: the entry to move
* @head: the head that will precede our entry
*/
static inline void list_move(struct list_head *list, struct list_head *head)
{
__list_del(list->prev, list->next);
list_add(list, head);
}
/**
* list_move_tail - delete from one list and add as another's tail
* @list: the entry to move
* @head: the head that will follow our entry
*/
static inline void list_move_tail(struct list_head *list,
struct list_head *head)
{
__list_del(list->prev, list->next);
list_add_tail(list, head);
}
說明
??list_move函式實作的功能是洗掉list指向的節點,同時將其以頭插法插入到head中,list_move_tail和list_move功能類似,只不過是將list節點插入到了head的尾部,
舉例
#include "mylist.h"
#include <stdio.h>
#include <stdlib.h>
struct student
{
struct list_head stu_list;
int ID;
int math;
};
int main()
{
struct student *p;
struct student *q;
struct student stu1;
struct student stu2;
struct list_head *pos1;
struct student *pos2;
struct student new_obj={.ID=100,.math=100};
//stu = (struct student*)malloc(sizeof(struct student));
//鏈表的初始化
INIT_LIST_HEAD(&stu1.stu_list);
INIT_LIST_HEAD(&stu2.stu_list);
LIST_HEAD(stu);
//頭插法創建stu stu1鏈表
for (int i = 0;i < 6;i++) {
p = (struct student *)malloc(sizeof(struct student));
p->ID=i;
p->math = i+80;
//頭插法
list_add(&p->stu_list,&stu1.stu_list);
//尾插法
//list_add_tail(&p->list,&stu.list);
}
printf("list_add: \r\n");
list_for_each(pos1, &stu1.stu_list) {
printf("ID = %d,math = %d\n",((struct student*)pos1)->ID,((struct student*)pos1)->math);
}
//移位替換
list_for_each_entry(pos2,&stu1.stu_list,stu_list) {
if (pos2->ID == 0) {
list_move(&pos2->stu_list,&stu1.stu_list);
break;
}
}
printf("list_move\r\n");
list_for_each_entry(pos2,&stu1.stu_list,stu_list) {
printf("ID = %d,math = %d\n",pos2->ID,pos2->math);
}
return 0;
}
鏈表的合并
內核實作
static inline void __list_splice(struct list_head *list,
struct list_head *head)
{
struct list_head *first = list->next;
struct list_head *last = list->prev;
struct list_head *at = head->next;
first->prev = head;
head->next = first;
last->next = at;
at->prev = last;
}
/**
* list_splice - join two lists
* @list: the new list to add.
* @head: the place to add it in the first list.
*/
static inline void list_splice(struct list_head *list, struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head);
}
/**
* list_splice_init - join two lists and reinitialise the emptied list.
* @list: the new list to add.
* @head: the place to add it in the first list.
*
* The list at @list is reinitialised
*/
static inline void list_splice_init(struct list_head *list,
struct list_head *head)
{
if (!list_empty(list)) {
__list_splice(list, head);
INIT_LIST_HEAD(list);//置空
}
}
說明
??list_splice完成的功能是合并兩個鏈表,假設當前有兩個鏈表,表頭分別是stu_list1和stu_list2(都是struct list_head變數),當呼叫list_splice(&stu_list1,&stu_list2)時,只要stu_list1非空,stu_list1鏈表的內容將被掛接在stu_list2鏈表上,位于stu_list2和stu_list2.next(原stu_list2表的第一個節點)之間,新stu_list2鏈表將以原stu_list1表的第一個節點為首節點,而尾節點不變,
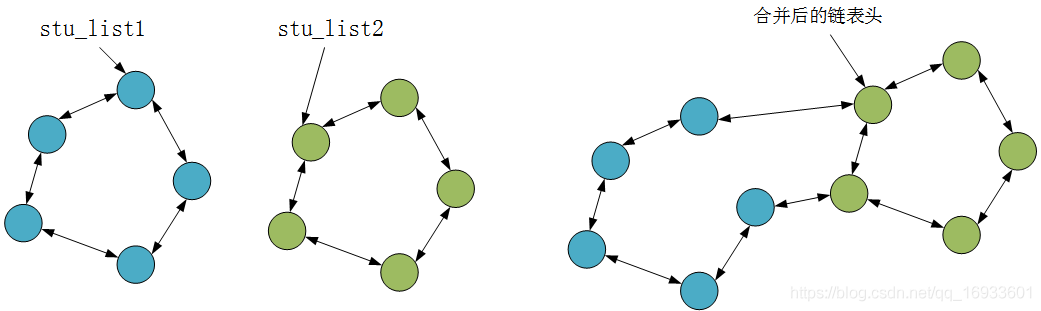
??list_splice_init和list_splice類似,只不過在合并完之后,呼叫INIT_LIST_HEAD(list)將list設定為空鏈,
用例
#include "mylist.h"
#include <stdio.h>
#include <stdlib.h>
struct student
{
struct list_head stu_list;
int ID;
int math;
};
int main()
{
struct student *p;
struct student *q;
struct student stu1;
struct student stu2;
struct list_head *pos1;
struct student *pos2;
struct student new_obj={.ID=100,.math=100};
//stu = (struct student*)malloc(sizeof(struct student));
//鏈表的初始化
INIT_LIST_HEAD(&stu1.stu_list);
INIT_LIST_HEAD(&stu2.stu_list);
LIST_HEAD(stu);
//頭插法創建stu1 list鏈表
for (int i = 0;i < 6;i++) {
p = (struct student *)malloc(sizeof(struct student));
p->ID=i;
p->math = i+80;
//頭插法
list_add(&p->stu_list,&stu1.stu_list);
//尾插法
//list_add_tail(&p->list,&stu.list);
}
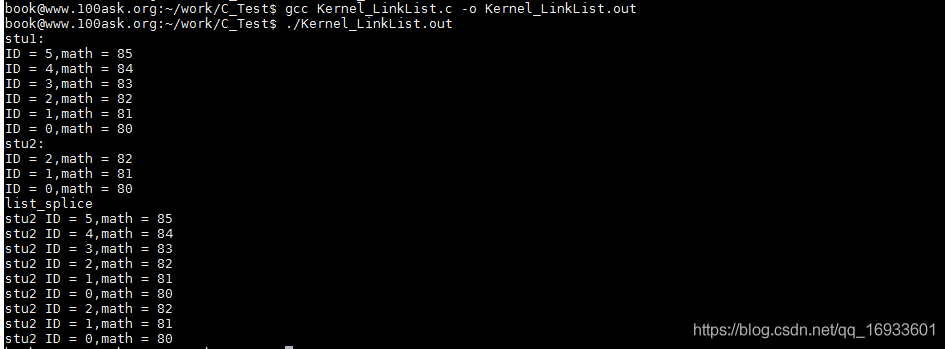
printf("stu1: \r\n");
list_for_each(pos1, &stu1.stu_list) {
printf("ID = %d,math = %d\n",((struct student*)pos1)->ID,((struct student*)pos1)->math);
}
//頭插法創建stu2 list 鏈表
for (int i = 0;i < 3;i++) {
q = (struct student *)malloc(sizeof(struct student));
q->ID=i;
q->math = i+80;
//頭插法
list_add(&q->stu_list,&stu2.stu_list);
//尾插法
//list_add_tail(&p->list,&stu.list);
}
printf("stu2: \r\n");
list_for_each(pos1, &stu2.stu_list) {
printf("ID = %d,math = %d\n",((struct student*)pos1)->ID,((struct student*)pos1)->math);
}
//合并
list_splice(&stu1.stu_list,&stu2.stu_list);
printf("list_splice\r\n");
list_for_each(pos1, &stu2.stu_list) {
printf("stu2 ID = %d,math = %d\n",((struct student*)pos1)->ID,((struct student*)pos1)->math);
}
return 0;
}
鏈表的遍歷
內核實作
//計算member在type中的位置
#define offsetof(type, member) (size_t)(&((type*)0)->member)
//根據member的地址獲取type的起始地址
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
/**
* list_first_entry - get the first element from a list
* @ptr: the list head to take the element from.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*
* Note, that list is expected to be not empty.
*/
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; prefetch(pos->next), pos != (head); \
pos = pos->next)
/**
* __list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*
* This variant differs from list_for_each() in that it's the
* simplest possible list iteration code, no prefetching is done.
* Use this for code that knows the list to be very short (empty
* or 1 entry) most of the time.
*/
#define __list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
/**
* list_for_each_prev - iterate over a list backwards
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; prefetch(pos->prev), pos != (head); \
pos = pos->prev)
/**
* list_for_each_safe - iterate over a list safe against removal of list entry
* @pos: the &struct list_head to use as a loop cursor.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
/**
* list_for_each_entry_reverse - iterate backwards over list of given type.
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_reverse(pos, head, member) \
for (pos = list_entry((head)->prev, typeof(*pos), member); \
prefetch(pos->member.prev), &pos->member != (head); \
pos = list_entry(pos->member.prev, typeof(*pos), member))
/**
* list_prepare_entry - prepare a pos entry for use in list_for_each_entry_continue()
* @pos: the type * to use as a start point
* @head: the head of the list
* @member: the name of the list_struct within the struct.
*
* Prepares a pos entry for use as a start point in list_for_each_entry_continue().
*/
#define list_prepare_entry(pos, head, member) \
((pos) ? : list_entry(head, typeof(*pos), member))
/**
* list_for_each_entry_continue - continue iteration over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Continue to iterate over list of given type, continuing after
* the current position.
*/
#define list_for_each_entry_continue(pos, head, member) \
for (pos = list_entry(pos->member.next, typeof(*pos), member); \
prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
/**
* list_for_each_entry_from - iterate over list of given type from the current point
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate over list of given type, continuing from current position.
*/
#define list_for_each_entry_from(pos, head, member) \
for (; prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
/**
* list_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
/**
* list_for_each_entry_safe_continue
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate over list of given type, continuing after current point,
* safe against removal of list entry.
*/
#define list_for_each_entry_safe_continue(pos, n, head, member) \
for (pos = list_entry(pos->member.next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
/**
* list_for_each_entry_safe_from
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate over list of given type from current point, safe against
* removal of list entry.
*/
#define list_for_each_entry_safe_from(pos, n, head, member) \
for (n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
/**
* list_for_each_entry_safe_reverse
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate backwards over list of given type, safe against removal
* of list entry.
*/
#define list_for_each_entry_safe_reverse(pos, n, head, member) \
for (pos = list_entry((head)->prev, typeof(*pos), member), \
n = list_entry(pos->member.prev, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.prev, typeof(*n), member))
說明
??list_entry(ptr, type, member)可以得到節點結構體的地址,得到地址后就可以對結構體中的元素進行操作了,依靠list_entry(ptr, type, member)函式,內核鏈表的增刪查改都不需要知道list_head結構體所嵌入式的物件,就可以完成各種操作,(為什么這里使用container_of來定義list_entry(ptr, type, member)結構體呢,下面會詳細解釋)
??list_first_entry(ptr, type, member)得到的是結構體中第一個元素的地址
??list_for_each(pos, head)是用來正向遍歷鏈表的,pos相當于一個臨時的節點,用來不斷指向下一個節點,
??list_for_each_prev(pos, head)和list_for_each_entry_reverse(pos, head, member)是用來倒著遍歷鏈表的
??list_for_each_safe(pos, n, head)和list_for_each_entry_safe(pos, n, head, member),這兩個函式是為了避免在遍歷鏈表的程序中因pos節點被釋放而造成的斷鏈這個時候就要求我們另外提供一個與pos同型別的指標n,在for回圈中暫存pos下一個節點的地址,(內核的設計者考慮的真是全面!)
??list_prepare_entry(pos, head, member)用于準備一個結構體的首地址,用在list_for_each_entry_contine()中
??list_for_each_entry_continue(pos, head, member)從當前pos的下一個節點開始繼續遍歷剩余的鏈表,不包括pos.如果我們將pos、head、member傳入list_for_each_entry,此宏將會從鏈表的頭節點開始遍歷,
??list_for_each_entry_continue_reverse(pos, head, member)從當前的pos的前一個節點開始繼續反向遍歷剩余的鏈表,不包括pos,
??list_for_each_entry_from(pos, head, member)從pos開始遍歷剩余的鏈表,
??list_for_each_entry_safe_continue(pos, n, head, member)從pos節點的下一個節點開始遍歷剩余的鏈表,并防止因洗掉鏈表節點而導致的遍歷出錯,
??list_for_each_entry_safe_from(pos, n, head, member) 從pos節點開始繼續遍歷剩余的鏈表,并防止因洗掉鏈表節點而導致的遍歷出錯,其與list_for_each_entry_safe_continue(pos, n, head, member)的不同在于在第一次遍歷時,pos沒有指向它的下一個節點,而是從pos開始遍歷,
??list_for_each_entry_safe_reverse(pos, n, head, member)從pos的前一個節點開始反向遍歷一個鏈表,并防止因洗掉鏈表節點而導致的遍歷出錯,
??list_safe_reset_next(pos, n, member) 回傳當前pos節點的下一個節點的type結構體首地址,
舉例
#include "mylist.h"
#include <stdio.h>
#include <stdlib.h>
struct student
{
struct list_head stu_list;
int ID;
int math;
};
int main()
{
struct student *p;
struct student *q;
struct student stu1;
struct student stu2;
struct list_head *pos1;
struct student *pos2;
struct student new_obj={.ID=100,.math=100};
//stu = (struct student*)malloc(sizeof(struct student));
//鏈表的初始化
INIT_LIST_HEAD(&stu1.stu_list);
INIT_LIST_HEAD(&stu2.stu_list);
LIST_HEAD(stu);
//頭插法創建stu stu1鏈表
for (int i = 0;i < 6;i++) {
p = (struct student *)malloc(sizeof(struct student));
p->ID=i;
p->math = i+80;
//頭插法
list_add(&p->stu_list,&stu1.stu_list);
//尾插法
//list_add_tail(&p->list,&stu.list);
}
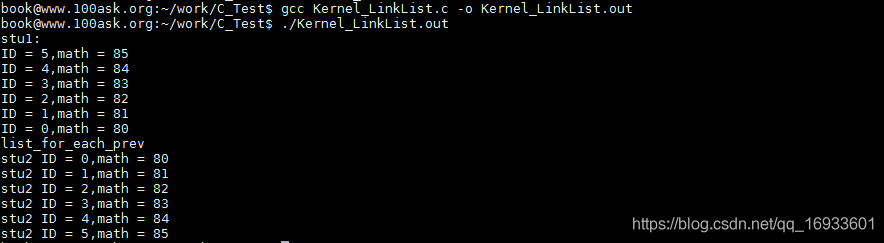
printf("stu1: \r\n");
list_for_each(pos1, &stu1.stu_list) {
printf("ID = %d,math = %d\n",((struct student*)pos1)->ID,((struct student*)pos1)->math);
}
printf("list_for_each_prev\r\n");
list_for_each_prev(pos1, &stu1.stu_list){
printf("stu2 ID = %d,math = %d\n",((struct student*)pos1)->ID,((struct student*)pos1)->math);
}
return 0;
}
??例子就不都寫出來了,感興趣的可以自己試試,
疑惑解答
??之前我們定義結構體的時候是把 struct list_head放在首位的,當使用list_for_each遍歷的時候,pos獲取的位置就是結構體的位置,也就是鏈表的位置,如下所示
struct student
{
struct list_head list;//暫且將鏈表放在結構體的第一位
int ID;
int math;
};
list_for_each(pos, &stu1.stu_list) {
printf("ID = %d,math = %d\n",((struct student*)pos)->ID,((struct student*)pos)->math);
}
??但是當我們把struct list_head list;放在最后時,pos獲取的顯然就已經不是鏈表的位置了,那么當我們再次呼叫list_for_each時就會出錯,
struct student
{
int ID;
int math;
struct list_head list;//暫且將鏈表放在結構體的第一位
};
??list_for_each_entry這個函式表示在遍歷的時候獲取entry,該宏中的pos型別為容器結構型別的指標,這與前面list_for_each中的使用的型別不再相同(這也就是為什么我們上面會分別定義pos1和pos2的原因了),不過這也是情理之中的事,畢竟現在的pos,我要使用該指標去訪問資料域的成員age了;head是你使用INIT_LIST_HEAD初始化的那個物件,即頭指標,注意,不是頭結點;member就是容器結構中的鏈表元素物件,使用該宏替代前面的方法,這個時候就要用到container_of這個宏了,(再一次感嘆內核設計者的偉大),
??關于container_of宏將在下一篇文章詳細介紹,這里先知道如何使用就可以,
list.h移植原始碼
??這里需要注意一點,如果是在GNU中使用GCC進行程式開發,可以不做更改,直接使用上面的函式即可;但如果你想把其移植到Windows環境中進行使用,可以直接將prefetch陳述句洗掉即可,因為prefetch函式它通過對資料手工預取的方法,減少了讀取延遲,從而提高了性能,也就是prefetch是GCC用來提高效率的函式,如果要移植到非GNU環境,可以換成相應環境的預取函式或者直接洗掉也可,它并不影響鏈表的功能,
/*
* @Description: 移植Linux2.6內核list.h
* @Version: V1.0
* @Autor: https://blog.csdn.net/qq_16933601
* @Date: 2020-09-12 22:54:51
* @LastEditors: Carlos
* @LastEditTime: 2020-09-16 00:35:17
*/
#ifndef _MYLIST_H
#define _MYLIST_H
//原來鏈表洗掉后指向的位置,這里我們修改成 0
// # define POISON_POINTER_DELTA 0
// #define LIST_POISON1 ((void *) 0x00100100 + POISON_POINTER_DELTA)
// #define LIST_POISON2 ((void *) 0x00200200 + POISON_POINTER_DELTA)
#define NULL ((void *)0)
#define LIST_POISON1 NULL
#define LIST_POISON2 NULL
//計算member在type中的位置
#define offsetof(type, member) (size_t)(&((type*)0)->member)
//根據member的地址獲取type的起始地址
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
//鏈表結構
struct list_head
{
struct list_head *prev;
struct list_head *next;
};
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
static inline void init_list_head(struct list_head *list)
{
list->prev = list;
list->next = list;
}
#ifndef CONFIG_DEBUG_LIST
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
#else
extern void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next);
#endif
//從頭部添加
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
#ifndef CONFIG_DEBUG_LIST
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
#else
extern void list_add(struct list_head *new, struct list_head *head);
#endif
//從尾部添加
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
static inline void __list_del(struct list_head *prev, struct list_head *next)
{
prev->next = next;
next->prev = prev;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
static inline void __list_splice(struct list_head *list,
struct list_head *head)
{
struct list_head *first = list->next;
struct list_head *last = list->prev;
struct list_head *at = head->next;
first->prev = head;
head->next = first;
last->next = at;
at->prev = last;
}
/**
* list_empty - tests whether a list is empty
* @head: the list to test.
*/
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
/**
* list_splice - join two lists
* @list: the new list to add.
* @head: the place to add it in the first list.
*/
static inline void list_splice(struct list_head *list, struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head);
}
/**
* list_replace - replace old entry by new one
* @old : the element to be replaced
* @new : the new element to insert
*
* If @old was empty, it will be overwritten.
*/
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
static inline void list_replace_init(struct list_head *old,
struct list_head *new)
{
list_replace(old, new);
INIT_LIST_HEAD(old);
}
/**
* list_move - delete from one list and add as another's head
* @list: the entry to move
* @head: the head that will precede our entry
*/
static inline void list_move(struct list_head *list, struct list_head *head)
{
__list_del(list->prev, list->next);
list_add(list, head);
}
/**
* list_move_tail - delete from one list and add as another's tail
* @list: the entry to move
* @head: the head that will follow our entry
*/
static inline void list_move_tail(struct list_head *list,
struct list_head *head)
{
__list_del(list->prev, list->next);
list_add_tail(list, head);
}
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
/**
* list_for_each_prev - iterate over a list backwards
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; pos != (head); \
pos = pos->prev)
??養成習慣,先贊后看!如果覺得寫的不錯,歡迎關注,點贊,收藏,轉發,謝謝!
??以上代碼均為測驗后的代碼,如有錯誤和不妥的地方,歡迎指出,
歡迎歡迎關注我的公眾號:嵌入式與Linux那些事,領取秋招筆試面試大禮包(華為小米等大廠面經,嵌入式知識點總結,筆試題目,簡歷模版等)和2000G學習資料,公眾號主要分享Linux驅動開發,資料結構與演算法,計算機基礎,C/C++等相關知識,有任何問題均可以加我微信,歡迎騷擾!,
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/236861.html
標籤:嵌入式