本次實驗是CSAPP的第5個實驗,這次實驗主要是讓我們熟悉如何優化程式,如何寫出更具有效率的代碼,通過這次實驗,我們可以更好的理解計算機的作業原理,在以后撰寫代碼時,具有能結合軟硬體思考的能力,
@
目錄- 實驗簡介
- 資料結構體
- 旋轉Rotate
- 平滑Smooth
- 評價指標
- 版本管理
- 驅動
- 優化程式的方法
- Optimizing Rotate
- 優化版本一:分塊 8 * 8
- 優化版本二:分塊 32 * 32
- 優化版本三:回圈展開,32路并行
- Optimizing Smooth
- 優化版本一:消除函式呼叫
- 優化版本二:分開討論,分塊求平均
- 總結
實驗簡介
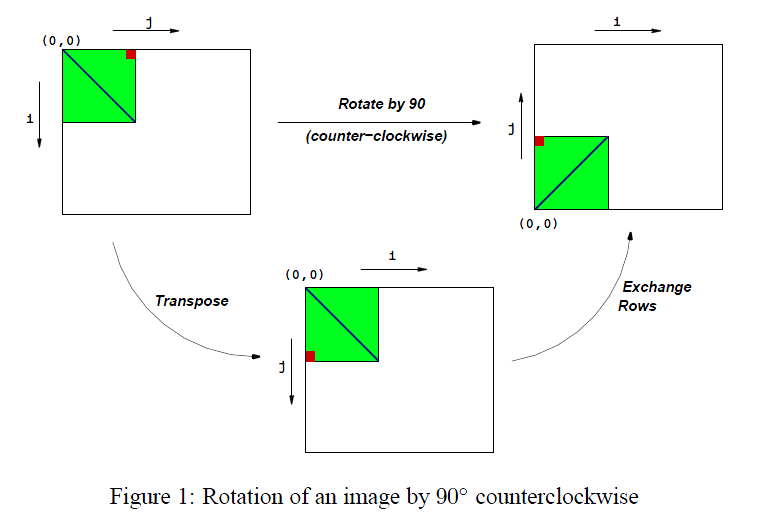
??本次實驗主要處理優化記憶體密集型代碼,影像處理提供了許多可以從優化中受益的功能示例,在本實驗中,我們將考慮兩種影像處理操作:旋轉,可將影像逆時針旋轉90o,平滑,可以“平滑”或“模糊”圖片,
??在本實驗中,我們將考慮將影像表示為二維矩陣M,其中\({M_{i,j}}\)表示M的第(i,j)個像素的值,像素值是紅色,綠色和藍色(RGB)值的三倍,我們只會考慮方形影像,令N表示影像的行(或列)數,行和列以C樣式編號,從0到N ? 1,
??給定這種表示形式,旋轉操作可以非常簡單地實作為以下兩個矩陣運算:
??轉置:對于每對(i,j),\({M_{i,j}}\)和\({M_{j,i}}\)是互換的
??交換行:第i行與第N-1 ? i行交換,
??具體如下圖所示
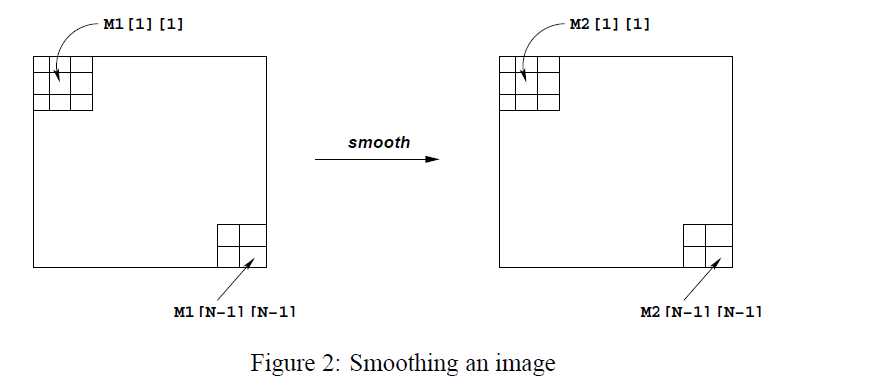
????通過用周圍所有像素的平均值替換每個像素值(在以該像素為中心的最大3×3視窗)中替換每個像素值來實作平滑操作,如下圖所示,像素的值\(M2[1][1]\) 和\(M2[N - 1][N - 1]\)如下所示:
??\(M2[1][1] = \frac{{\sum\nolimits_{i = 0}^2 {\sum\nolimits_{j = 0}^2 {M1[i][j]} } }}{9}\)
??\(M2[N - 1][N - 1] = \frac{{\sum\nolimits_{i = N - 2}^{N - 1} {\sum\nolimits_{j = N - 2}^{N - 1} {M1[i][j]} } }}{4}\)
??本次實驗中,我們需要修改唯一檔案是kernels.c,driver.c程式是一個驅動程式,可讓對我們修改的程式進行評分,使用命令make driver生成驅動程式代碼并使用./driver命令運行它,
資料結構體
??影像的核心資料是用結構體表示的,像素是一個結構,如下所示:
typedef struct {
unsigned short red; /* R value */
unsigned short green; /* G value */
unsigned short blue; /* B value */
} pixel;
??可以看出,RGB值具有16位表示形式(“ 16位顏色”),影像I表示為一維像素陣列,其中第(i,j)個像素為I [RIDX(i,j,n)],這里n是影像矩陣的維數,??RIDX是定義如下的宏:
#define RIDX(i,j,n) ((i)*(n)+(j))
??有關此代碼,請參見檔案defs.h,
旋轉Rotate
??以下C函式計算將源影像src旋轉90°的結果,并將結果存盤在目標影像dst中,dim是影像的尺寸,
void naive_rotate(int dim, pixel *src, pixel *dst) {
int i, j;
for(i=0; i < dim; i++)
for(j=0; j < dim; j++)
dst[RIDX(dim-1-j,i,dim)] = src[RIDX(i,j,dim)];
return;
}
??上面的代碼掃描源影像矩陣的行,然后復制到目標影像矩陣的列中,我們的任務是使用代碼移動,回圈展開和阻塞等技術重寫此代碼,以使其盡可能快地運行,(有關此代碼,請參見檔案kernels.c,)
平滑Smooth
??平滑功能將源影像src作為輸入,并在目標影像dst中回傳平滑結果,這是實作的一部分:
void naive_smooth(int dim, pixel *src, pixel *dst) {
int i, j;
for(i=0; i < dim; i++)
for(j=0; j < dim; j++)
dst[RIDX(i,j,dim)] = avg(dim, i, j, src); /* Smooth the (i,j)th pixel */
return;
}
??函式avg回傳第(i,j)個像素周圍所有像素的平均值,我們的任務是優化平滑(和avg)以盡可能快地運行, (注意:函式avg是一個區域函式,可以完全擺脫它而以其他方式實作平滑),(這段代碼(以及avg的實作)位于kernels.c檔案中,)
評價指標
??我們的主要性能指標是CPE,如果某個函式需要C個周期來運行大小為N×N的影像,則CPE值為\(C/{N^2}\),
版本管理
??我們可以撰寫旋轉和平滑例程的許多版本,為了幫助您比較撰寫的所有不同版本的性能,我們提供了一種“注冊”功能的方式,
??例如,我們提供給您的檔案kernels.c包含以下功能:
void register_rotate_functions() {
add_rotate_function(&rotate, rotate_descr);
}
??此函式包含一個或多個呼叫以添加旋轉函式,在上面的示例中,添加旋轉函式將函式旋轉與字串旋轉說明一起注冊,該字串是函式功能的ASCII描述,請參閱檔案kernels.c以了解如何創建字串描述,該字串的長度最多為256個字符,
驅動
??將撰寫的源代碼將與我們提供給驅動程式二進制檔案的目標代碼鏈接,要創建此二進制檔案,您將需要執行以下命令
unix> make driver
??每次更改kernels.c中的代碼時,都需要重新制作驅動程式,要測驗您的實作,然后可以運行以下命令:
unix> ./driver
??該驅動程式可以在四種不同的模式下運行:
??默認模式,在其中運行實施的所有版本,
??Autograder模式,其中僅運行rotation()和smooth()函式,這是當我們使用驅動程式對您的切紙進行評分時將運行的模式,
??檔案模式,其中僅運行輸入檔案中提到的版本,
??轉儲模式,其中每個版本的單行描述轉儲到文本檔案中,然后,您可以編輯該文本檔案,以僅使用檔案模式保留要測驗的版本,您可以指定是在轉儲檔案之后退出還是要運行您的實作,
??如果不帶任何引數運行,驅動程式將運行所有版本(默認模式),其他模式和選項可以通過驅動程式的命令列引數來指定,如下所示:
??-g:僅運行rotate()和smooth()函式(自動分級模式),
??-f
??-d
??-q :將版本名稱轉儲到轉儲檔案后退出,與-d一起使用,例如,要在列印轉儲檔案后立即退出,請鍵入./driver -qd dumpfile,
??-h:列印命令列用法,
優化程式的方法
emsp;?回顧下常用的優化程式的方法,總結如下:
(1)高級設計
??為遇到的問題選擇適當的演算法和資料結構,要特別警覺,避免使用那些會漸進地產生糟糕性能的演算法或編碼技術,
(2)基本編碼原則
??避免限制優化的因素,這樣編譯器就能產生高效的代碼,
??消除連續的函式呼叫,在可能時,將計算移到回圈外,考慮有選擇地妥協程式的模塊性以獲得更大的效率,
??消除不必要的記憶體參考,引入臨時變數來保存中間結果,只有在最后的值計算出來時,才將結果存放到陣列或全域變數中,
(3)低級優化
??結構化代碼以利用硬件功能,
??展開回圈,降低開銷,并且使得進一步的優化成為可能,
??通過使用例如多個累積變數和重新結合等技術,找到方法提高指令級并行,
??用功能性的風格重寫條件操作,使得編譯采用條件資料傳送,
(4)使用性能分析工具
??當處理大型程式時,將注意力集中在最耗時的部分變得很重要,代碼剖析程式和相關的工具能幫助我們系統地評價和改行程式性能,我們描述了 GPROF,一個標準的Unix剖析工具,還有更加復雜完善的剖析程式可用,例如 Intel的VTUNE程式開發系統,還有 Linux系統基本上都有的 VALGRIND,這些工具可以在程序級分解執行時間,估計程式每個基本塊( basic block)的性能,(基本塊是內部沒有控制轉移的指令序列,因此基本塊總是整個被執行的,)
Optimizing Rotate
??在這一部分中,我們將優化旋轉以實作盡可能低的CPE,您應該編譯驅動程式,然后使用適當的引數運行它以測驗您的實作,例如,運行提供的原始版本(用于旋轉)的驅動程式將生成如下所示的輸出:
??函式原始碼如下:
void naive_rotate(int dim, pixel *src, pixel *dst) {
int i, j;
for(i=0; i < dim; i++)
for(j=0; j < dim; j++)
dst[RIDX(dim-1-j,i,dim)] = src[RIDX(i,j,dim)];
return;
}
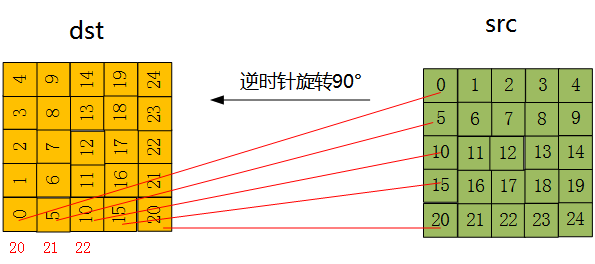
??其中,defs.h中RIDX定義為:#define RIDX(i,j,n) ((i)*(n)+(j))下面詳細分析下程式,
i = 0 j = 0 dest[20] = src[0] i = 1 j = 0 dest[21] = src[5]
i = 0 j = 1 dest[15] = src[1] i = 1 j = 1 dest[16] = src[6]
i = 0 j = 2 dest[10] = src[2] i = 1 j = 2 dest[11] = src[7]
i = 0 j = 3 dest[5] = src[3] i = 1 j = 3 dest[6] = src[8]
i = 0 j = 4 dest[0] = src[4] i = 1 j = 4 dest[1] = src[9]
??具體如下圖所示:
??這段代碼的作用就是將dim * dim大小的方塊中所有的像素進行行列調位、導致整幅圖畫進行了90度旋轉,觀察源代碼我們發現,程式進行了嵌套回圈,隨著dim的增加,回圈的復雜度越來越大,而且每回圈一次,dim-1-j就要計算一次,因此,我們考慮進行分塊優化,
優化版本一:分塊 8 * 8
??對于回圈分塊,這里的分塊指的是一個應用級的資料組塊,而不是高速快取中的塊,這樣構造程式,能將一個片加載到L1高速快取中去,并在這個片中進行所需要的所有讀和寫,然后丟掉這個片,加載下一個片,以此類推,
/*分塊:8 * 8*/
char rotate_descr[] = "rotate1: Current working version";
void rotate(int dim, pixel *src, pixel *dst) {
int i,j,i1,j1;
for(i=0; i < dim; i+=8)
for(j=0; j < dim; j+=8)
for(i1=i; i1 < i+8; i1++)
for(j1=j; j1 < j+8; j1++)
dst[RIDX(dim-1-j1,i1,dim)] = src[RIDX(i1,j1,dim)];
}
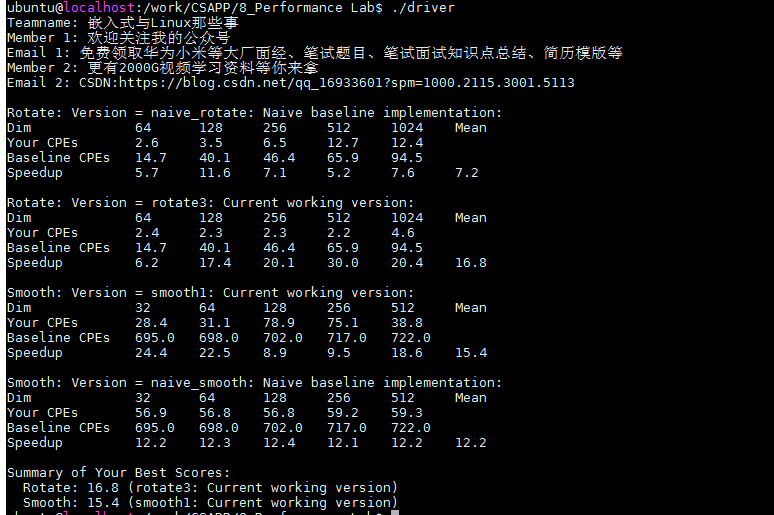
??優化后的版本測驗如下所示:
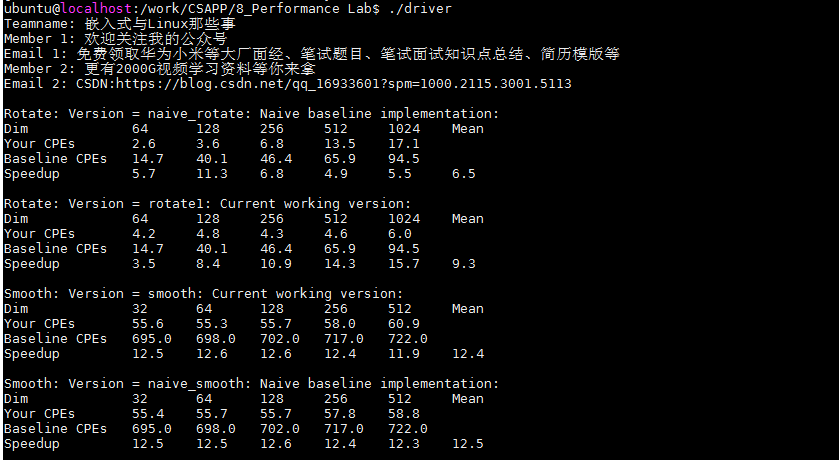
??右上圖可以看到,得分有了明顯的提升,Dim規模較小時,提升并不明顯,在Dim為1024*1024時,由原來的17.1降低到了6.0.說明我們的方法還是有效的,但是最后的總得得分只有9.3分,效果不是很好,
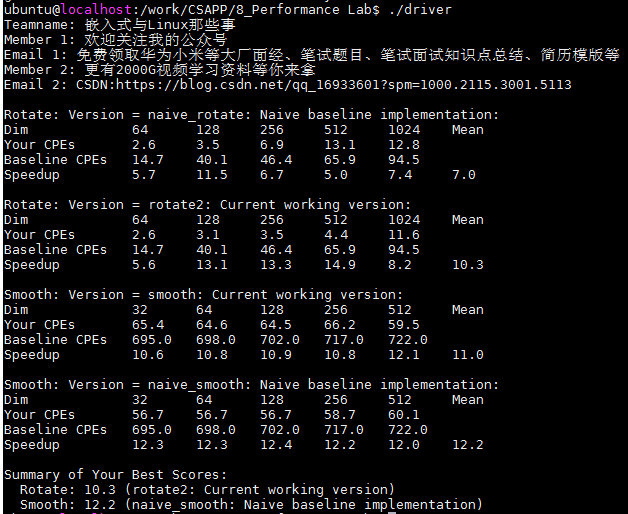
優化版本二:分塊 32 * 32
char rotate_descr[] = "rotate2: Current working version";
void rotate(int dim, pixel *src, pixel *dst) {
int i,j,i1,j1;
for(i=0; i < dim; i+=32)
for(j=0; j < dim; j+=32)
for(i1=i; i1 < i+32; i1++)
for(j1=j; j1 < j+32; j1++)
dst[RIDX(dim-1-j1,i1,dim)] = src[RIDX(i1,j1,dim)];
}
??本次繼續采用的是分塊策略,分為了32塊,但是由下圖的得分可以看到,性能基本有提升,所以,需要換個思路了,
優化版本三:回圈展開,32路并行
??在版本二的基礎上,我們進行回圈展開,32路并行,并使用指標代替RIDX進行陣列訪問,這里犧牲了程式的尺寸來換取速度優化,
char rotate_descr[] = "rotate3: Current working version";
void rotate(int dim, pixel *src, pixel *dst) {
int i,j;
int dst_base = (dim-1)*dim;
dst +=dst_base;
for(i = 0;i < dim;i += 32){
for(j = 0;j < dim;j++){
*dst = *src; src +=dim; dst++; //31組
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src++;
src -= (dim<<5)-dim; //src -=31*dim;
dst -=31+dim;
}
dst +=dst_base + dim;
dst +=32;
src +=(dim<<5)-dim; //src +=31*dim;
}
}
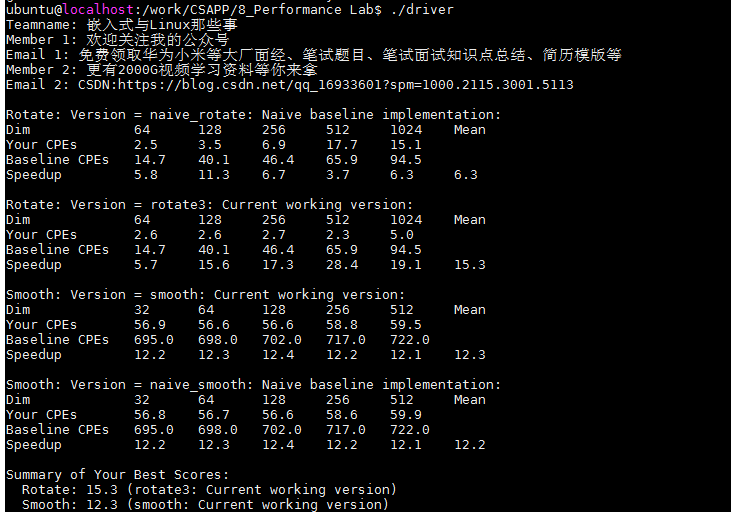
??我們在版本二的基礎上,將原來的程式的內回圈展開成32個并行,每一次同時處理32個像素點,即將回圈次數減少了32倍,大大加速了程式,分數由版本二的10.3分漲到了15.3分,特別是在哦1024 * 1024時,由15.1直接降到了5.0,性能提升還是很明顯的,
Optimizing Smooth
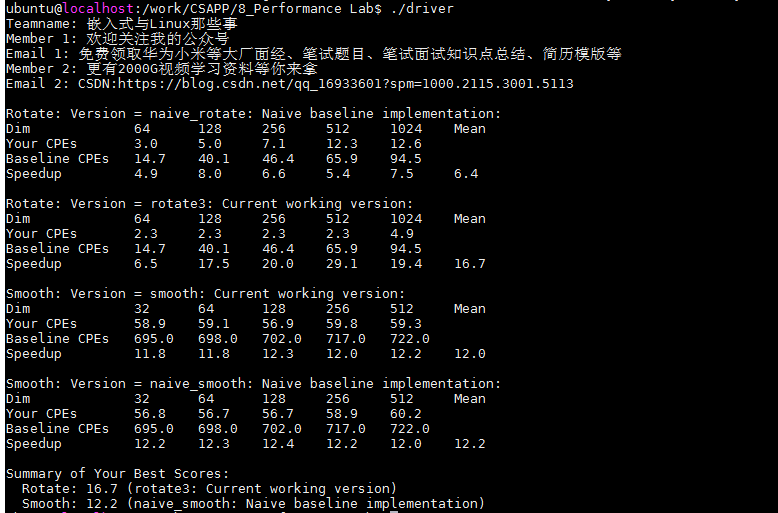
??在這一部分中,您將優化平滑度以實作盡可能低的CPE,例如,運行提供的樸素版本(為了平滑)的驅動程式將生成如下所示的輸出:
unix> ./driver
Smooth: Version = naive_smooth: Naive baseline implementation:
Dim 32 64 128 256 512 Mean
Your CPEs 695.8 698.5 703.8 720.3 722.7
Baseline CPEs 695.0 698.0 702.0 717.0 722.0
Speedup 1.0 1.0 1.0 1.0 1.0 1.0
void naive_smooth(int dim, pixel *src, pixel *dst) {
int i, j;
for(i=0; i < dim; i++)
for(j=0; j < dim; j++)
dst[RIDX(i,j,dim)] = avg(dim, i, j, src); /* Smooth the (i,j)th pixel */
return;
}
??這個函式的作用是平滑影像,在smooth函式中因為要求周圍點的平均值,所以會頻繁的呼叫avg函式,而且avg函式還是一個2層for回圈,所以我們可以考慮回圈展開或者消除函式呼叫等方法,減少avg函式呼叫和回圈,
??Smooth函式處理分為4塊,一為主體內部,由9點求平均值;二為4個頂點,由4點求平均值;三為四條邊界,由6點求平均值,從圖片的頂部開始處理,再上邊界,順序處理下來,其中在處理左邊界時,for回圈處理一行主體部分,
??未經優化的函式性能如下,得分為12.2分,
優化版本一:消除函式呼叫
void smooth(int dim, pixel *src, pixel *dst)
{
pixel_sum rowsum[530][530];
int i, j, snum;
for(i=0; i<dim; i++)
{
rowsum[i][0].red = (src[RIDX(i, 0, dim)].red+src[RIDX(i, 1, dim)].red);
rowsum[i][0].blue = (src[RIDX(i, 0, dim)].blue+src[RIDX(i, 1, dim)].blue);
rowsum[i][0].green = (src[RIDX(i, 0, dim)].green+src[RIDX(i, 1, dim)].green);
rowsum[i][0].num = 2;
for(j=1; j<dim-1; j++)
{
rowsum[i][j].red = (src[RIDX(i, j-1, dim)].red+src[RIDX(i, j, dim)].red+src[RIDX(i, j+1, dim)].red);
rowsum[i][j].blue = (src[RIDX(i, j-1, dim)].blue+src[RIDX(i, j, dim)].blue+src[RIDX(i, j+1, dim)].blue);
rowsum[i][j].green = (src[RIDX(i, j-1, dim)].green+src[RIDX(i, j, dim)].green+src[RIDX(i, j+1, dim)].green);
rowsum[i][j].num = 3;
}
rowsum[i][dim-1].red = (src[RIDX(i, dim-2, dim)].red+src[RIDX(i, dim-1, dim)].red);
rowsum[i][dim-1].blue = (src[RIDX(i, dim-2, dim)].blue+src[RIDX(i, dim-1, dim)].blue);
rowsum[i][dim-1].green = (src[RIDX(i, dim-2, dim)].green+src[RIDX(i, dim-1, dim)].green);
rowsum[i][dim-1].num = 2;
}
for(j=0; j<dim; j++)
{
snum = rowsum[0][j].num+rowsum[1][j].num;
dst[RIDX(0, j, dim)].red = (unsigned short)((rowsum[0][j].red+rowsum[1][j].red)/snum);
dst[RIDX(0, j, dim)].blue = (unsigned short)((rowsum[0][j].blue+rowsum[1][j].blue)/snum);
dst[RIDX(0, j, dim)].green = (unsigned short)((rowsum[0][j].green+rowsum[1][j].green)/snum);
for(i=1; i<dim-1; i++)
{
snum = rowsum[i-1][j].num+rowsum[i][j].num+rowsum[i+1][j].num;
dst[RIDX(i, j, dim)].red = (unsigned short)((rowsum[i-1][j].red+rowsum[i][j].red+rowsum[i+1][j].red)/snum);
dst[RIDX(i, j, dim)].blue = (unsigned short)((rowsum[i-1][j].blue+rowsum[i][j].blue+rowsum[i+1][j].blue)/snum);
dst[RIDX(i, j, dim)].green = (unsigned short)((rowsum[i-1][j].green+rowsum[i][j].green+rowsum[i+1][j].green)/snum);
}
snum = rowsum[dim-1][j].num+rowsum[dim-2][j].num;
dst[RIDX(dim-1, j, dim)].red = (unsigned short)((rowsum[dim-2][j].red+rowsum[dim-1][j].red)/snum);
dst[RIDX(dim-1, j, dim)].blue = (unsigned short)((rowsum[dim-2][j].blue+rowsum[dim-1][j].blue)/snum);
dst[RIDX(dim-1, j, dim)].green = (unsigned short)((rowsum[dim-2][j].green+rowsum[dim-1][j].green)/snum);
}
}
??在以上的優化中,我們取消了對avg函式的直接呼叫,而是直接對像素點的fgb顏色分別求均值,并且將重復利用的資料存盤在了陣列之中,因此,速度比之前有所提升,但是提升并不高,由12.2提升到15.4,
優化版本二:分開討論,分塊求平均
void smooth(int dim, pixel *src, pixel *dst)
{
int i,j;
int dim0=dim;
int dim1=dim-1;
int dim2=dim-2;
pixel *P1, *P2, *P3;
pixel *dst1;
P1=src;
P2=P1+dim0;
//左上角像素處理
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red)>>2;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
dst++;
//上邊界處理
for(i=1;i<dim1;i++)
{
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red)/6;
dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green)/6;
dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue)/6;
dst++;
P1++;
P2++;
}
//右上角像素處理
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red)>>2;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
dst++;
P1=src;
P2=P1+dim0;
P3=P2+dim0;
//左邊界處理
for(i=1;i<dim1;i++)
{
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red+P3->red+(P3+1)->red)/6;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green+P3->green+(P3+ 1)->green)/6;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue+P3->blue+(P3+1)->blue)/6;
dst++;
dst1=dst+1;
//中間主體部分處理
for(j=1;j<dim2;j+=2)
{
//同時處理兩個像素
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red+P3->red+(P3+1)->red+(P3+2)->red)/9;
dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green+P3->green+(P3+1)->green+(P3+2)->green)/9;
dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue+P3->blue+(P3+1)->blue+(P3+2)->blue)/9;
dst1->red=((P1+3)->red+(P1+1)->red+(P1+2)->red+(P2+3)->red+(P2+1)->red+(P2+2)->red+(P3+3)->red+(P3+1)->red+(P3+2)->red)/9;
dst1->green=((P1+3)->green+(P1+1)->green+(P1+2)->green+(P2+3)->green+(P2+1)->green+(P2+2)->green+(P3+3)->green+(P3+1)->green+(P3+2)->green)/9;
dst1->blue=((P1+3)->blue+(P1+1)->blue+(P1+2)->blue+(P2+3)->blue+(P2+1)->blue+(P2+2)->blue+(P3+3)->blue+(P3+1)->blue+(P3+2)->blue)/9;
dst+=2;
dst1+=2;
P1+=2;
P2+=2;
P3+=2;
}
for(;j<dim1;j++)
{
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red+P3->red+(P3+1)->red+(P3+2)->red)/9;
dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green+P3->green+(P3+1)->green+(P3+2)->green)/9;
dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue+P3->blue+(P3+1)->blue+(P3+2)->blue)/9;
dst++;
P1++;
P2++;
P3++;
}
//右側邊界處理
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red+P3->red+(P3+1)->red)/6;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green+P3->green+(P3+1)->green)/6;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue+P3->blue+(P3+1)->blue)/6;
dst++;
P1+=2;
P2+=2;
P3+=2;
}
//右下角處理
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red)>>2;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
dst++;
//下邊界處理
for(i=1;i<dim1;i++)
{
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red)/6;
dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green)/6;
dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue)/6;
dst++;
P1++;
P2++;
}
//右下角像素處理
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red)>>2;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
}
??在這個版本中,我們在版本一的基礎上繼續優化,將Smooth函式分為內部-頂點-邊界的四部分,一為主體內部,由9點求平均值;二為4個頂點,由4點求平均值;三為四條邊界,由6點求平均值,從圖片的頂部開始處理,再上邊界,順序處理下來,其中在處理左邊界時,for回圈處理一行主體部分,就是以上的代碼,
??下圖為測驗結果,由版本一的分15.4分提升到了44.1分,性能提升顯著!
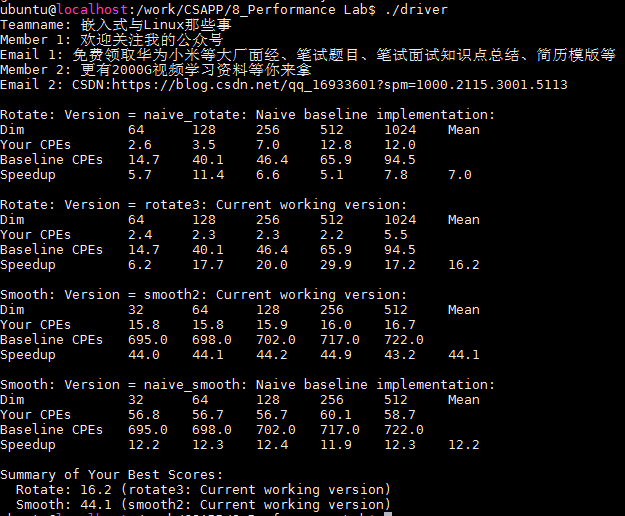
總結
??本次實驗的趣味性不如前幾個實驗,難度也沒有前幾個實驗的大,在實際優化程式時,我們不能一味的為了速度而展開程式,或者消除函式參考,以程式的體積和可讀性去換取性能的提升是非常不劃算的,在保證可讀性的前提下盡可能去提升程式的性能,
有任何問題,均可通過公告中的二維碼聯系我
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/247020.html
標籤:嵌入式
下一篇:httpd.conf的設定問題