目錄??在計算機系統模型中,CPU執行指令,而存盤器系統為CPU存放指令和資料,實際上,存盤器系統是一個具有不同容量、成本和訪問時間的存盤設備的層次結構,
??如果你的程式需要的資料是存盤在CPU暫存器中,那么在指令的執行期間,在0個周期內就能訪問到它們,如果存盤在高速快取中,需要4~75個周期,如果存盤在主存中,需要上百個周期,而如果存盤在磁盤上,需要大約幾千萬個周期!
??計算機程式的一個基本屬性稱為區域性,具有良好區域性的程式傾向于一次又一次地訪問相同的資料項集合,或是傾向于訪問鄰近的資料項集合,具有良好區域性的程式比區域性差的程式更多地傾向于從存盤器層次結構中較高層次處訪問資料項,因此運行得更快,
- 存盤技術
- 隨機訪問存盤器
- 區域性
- 存盤器層次結構
- 高速快取存盤器
- 撰寫高速快取友好的代碼
- 總結
存盤技術
隨機訪問存盤器
??隨機訪問存盤器( Random-Access Memory,RAM)分為兩類:靜態的和動態的,靜態RAM(SRAM)比動態RAM(DRAM)更快,但也貴得多,SRAM用來作為高速快取存盤器,DRAM用來作為主存以及圖形系統的幀緩沖區,
靜態RAM
??SRAM將每個位存盤在一個雙穩態的( bistable)存盤器單元里,每個單元是用一個六晶體管電路來實作的,這個電路有這樣一個屬性,它可以無限期地保持在兩個不同的電壓配置( configuration)或狀態( state)之一,其他任何狀態都是不穩定的,在不穩定狀態時,電路會迅速轉移到兩個穩定狀態的一個,
??由于SRAM存盤器單元的雙穩態特性,只要有電,它就會永遠地保持它的值,即使有干擾(例如電子噪音)來擾亂電壓,當干擾消除時,電路就會恢復到穩定值,
動態RAM
??DRAM將每個位存盤為對一個電容的充電,DRAM存盤器可以制造得非常密集,每個單元由一個電容和一個訪問晶體管組成,但是,與SRAM不同,DRAM存盤器單元對干擾非常敏感,當電容的電壓被擾亂之后,它就永遠不會恢復了,暴露在光線下會導致電容電壓改變,
??下表總結了SRAM和DRAM存盤器的特性,只要有供電,SRAM就會保持不變,與DRAM不同,它不需要重繪,SRAM的存取比DRAM快,SRAM對諸如光和電噪聲這樣的干擾不敏感,代價是SRAM單元比DRAM單元使用更多的晶體管,因而密集度低,而且更貴,功耗更大,
| 每位晶體管數 | 相對訪問時間 | 持續的 | 敏感的 | 相對花費 | 應用 | |
|---|---|---|---|---|---|---|
| SRAM | 6 | 1X | 是 | 否 | 1000X | 高速快取存盤器 |
| DRAM | 1 | 10X | 否 | 是 | 1X | 主存,幀緩沖區 |
傳統的DRAM
??DRAM芯片中的單元(位)被分成d個超單元( supercell),每個超單元都由w個DRAM單元組成,一個\(d \times w\)的DRAM總共存盤了\(dw\)位資訊,超單元被組織成一個r行c列的長方形陣列,這里rc=d,每個超單元有形如(i,j)的地址,這里i表示行,而j表示列,
??例如,如下圖所示是一個16×8的DRAM芯片的組織,有d=16個超單元,每個超單元有w=8位,r=4行,c=4列,帶陰影的方框表示地址(2,1)處的超單元,資訊通過稱為引腳(pin)的外部連接器流入和流出芯片,每個引腳攜帶一個1位的信號,下圖給出了兩組引腳:8個data引腳,它們能傳送一個位元組到芯片或從芯片傳出一個位元組,以及2個addr引腳,它們攜帶2位的行和列超單元地址,其他攜帶控制資訊的引腳沒有顯示出來,
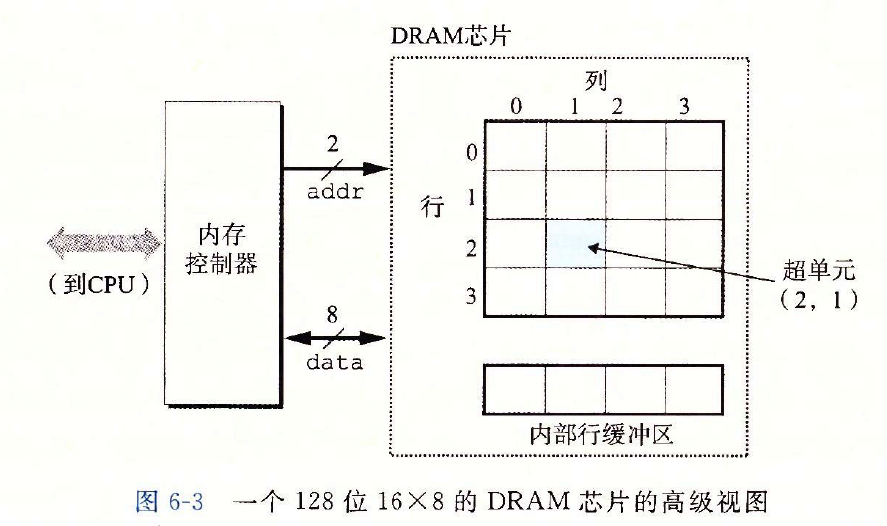
??每個DRAM芯片被連接到某個稱為記憶體控制器( memory controller)的電路,這個電路可以一次傳送w位到每個DRAM芯片或一次從每個DRAM芯片傳出w位,為了讀出超單元(i,j)的內容,記憶體控制器將行地址i發送到DRAM,然后是列地址j,DRAM把超單元(i,j)的內容發回給控制器作為回應,行地址i稱為RAS( Row Access strobe,行訪問選通脈沖)請求,列地址j稱為CAS( Column Access strobe,列訪問選通脈沖)請求,注意,RAS和CAS請求共享相同的DRAM地址引腳,
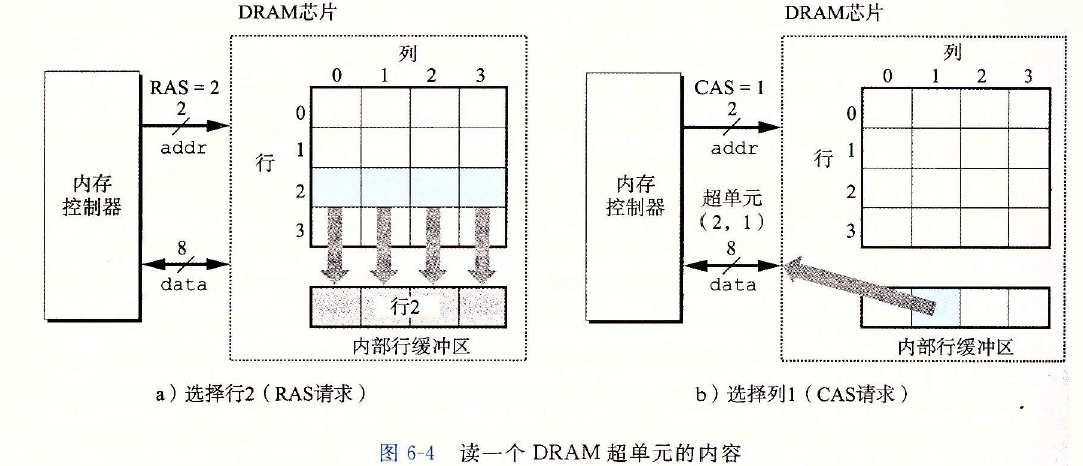
??例如,要從圖6-3中16×8的DRAM中讀出超單元(2,1),記憶體控制器發送行地址2,如下圖a所示,DRAM的回應是將行2的整個內容都復制到一個內部行緩沖區,接下來,記憶體控制器發送列地址1,如下圖b所示,DRAM的回應是從行緩沖區復制出超單元(2,1)中的8位,并把它們發送到記憶體控制器,
??電路設計者將DRAM組織成二維陣列而不是線性陣列的一個原因是降低芯片上地址引腳的數量,例如,如果示例的128位DRAM被組織成一個16個超單元的線性陣列,地址為0~15,那么芯片會需要4個地址引腳而不是2個,二維陣列組織的缺點是必須分兩步發送地址,這增加了訪問時間,
增強的DRAM
??可以通過以下方式提高訪問基本DRAM的速度,
??快頁模式DRAM( Fast Page Mode dram, FPM DRAM),傳統的DRAM將超單元的一整行復制到它的內部行緩沖區中,使用一個,然后丟棄剩余的,FPM DRAM允許對同一行連續地訪問可以直接從行緩沖區得到服務,
假如要讀取第4行的3個超單元,傳統DRAM需要發出3次RAS,CAS,而FPM DRAM只需要發出一次RAS,CAS,后面跟2個CAS即可,
? 擴展資料輸出DRAM( Extended Data Out Dram, EDO DRAM), FPM DRAM的個增強的形式,它允許各個CAS信號在時間上靠得更緊密一點,
??同步DRAM( Synchronous DRaM, SDRAM), SDRAM用與驅動記憶體控制器相同的外部時鐘信號的上升沿來代替許多這樣的控制信號,最終效果就是 SDRAM能夠比那些異步的存盤器更快地輸出它的超單元的內容,
??雙倍資料速率同步DRAM( Double data- Rate SynchronouS DRAm, DDR SDRAM),DDR SDRAM是對 SDRAM的一種增強,它通過使用兩個時鐘沿作為控制信號,從而使DRAM的速度翻倍,不同型別的 DDR SDRAM是用提高有效帶寬的很小的預取緩沖區的大小來劃分的:DDR(2位)、DDR2(4位)和DDR(8位),
??視頻RAM( Video ram,VRAM),它用在圖形系統的幀緩沖區中,VRAM的思想與 FPM DRAM類似,兩個主要區別是:1)VRAM的輸出是通過依次對內部緩沖區的整個內容進行移位得到的;2)VRAM允許對記憶體并行地讀和寫,因此,系統可以在寫下一次更新的新值(寫)的同時,用幀緩沖區中的像素刷螢屏(讀),
非易失性存盤器
??如果斷電,DRAM和SRAM會丟失它們的資訊,從這個意義上說,它們是易失的( volatile),另一方面,非易失性存盤器( nonvolatile memory)即使是在關電后,仍然保存著它們的資訊,
??對EPROM編程是通過使用一種把1寫人 EPROM的特殊設備來完成的, EPROM能夠被擦除和重編程的次數的數量級可以達到1000次,EEPROM能夠被編程的次數的數量級可以達到10次,
??閃存( flash memory)是一類非易失性存盤器,基于 EEPROM,它已經成為了一種重要的存盤技術,
訪問主存
??資料流通過稱為總線(bus)的共享電子電路在處理器和DRAM主存之間來來回回,每次CPU和主存之間的資料傳送都是通過一系列步驟來完成的,這些步驟稱為總線事務( bus transaction),讀事務( read transaction)從主存傳送資料到CPU,寫事務( write trans-action)從CPU傳送資料到主存,
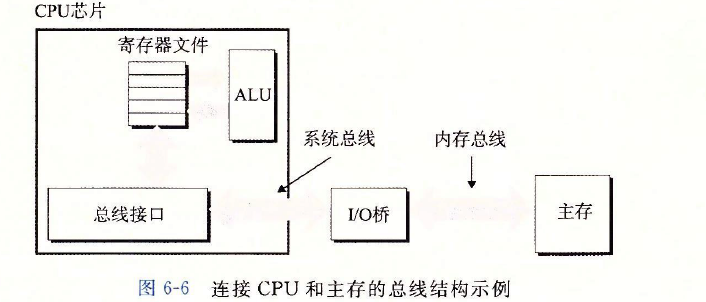
??總線是一組并行的導線,能攜帶地址、資料和控制信號,取決于總線的設計,資料和地址信號可以共享同一組導線,也可以使用不同的,同時,兩個以上的設備也能共享同一總線,控制線攜帶的信號會同步事務,并標識出當前正在被執行的事務的型別,例如,當前關注的這個事務是到主存的嗎?還是到諸如磁盤控制器這樣的其他I/O設備?這個事務是讀還是寫?總線上的資訊是地址還是資料項?
??展示了一個示例計算機系統的配置,主要部件是CPU芯片、我們將稱為IO橋接器(I/ O bridge)的芯片組(其中包括記憶體控制器),以及組成主存的DRAM記憶體模塊這些部件由一對總線連接起來,其中一條總線是系統總線( system bus),它連接CPU和I/O橋接器,另一條總線是記憶體總線( memory bus),它連接I/O橋接器和主存,I/O橋接器將系統總線的電子信號翻譯成記憶體總線的電子信號,
區域性
??一個撰寫良好的計算機程式常常具有良好的區域性( locality),也就是,它們傾向于參考鄰近于其他最近參考過的資料項的資料項,或者最近參考過的資料項本身,這種傾向性,被稱為區域性原理( principle of locality),是一個持久的概念,對硬體和軟體系統的設計和性能都有著極大的影響,區域性通常有兩種不同的形式:時間區域性( temporal locality)和空間區域性( spatial locality),在一個具有良好時間區域性的程式中,被參考過一次的記憶體位置很可能在不遠的將來再被多次參考,在一個具有良好空間區域性的程式中,如果一個記憶體位置被參考了次,那么程式很可能在不遠的將來參考附近的一個記憶體位置,一般而言,有良好區域性的程式比區域性差的程式運行得更快,
??如下所示的函式sumvec,它對一個向量的元素求和,在這個例子中,變數sum在每次回圈迭代中被參考一次,因此,對于sum來說,有好的時間區域性,另一方面,因為sun是標量,對于sum來說,沒有空間區域性,
int sumvec(int v[N])
{
int i,sum = 0;
for (i = 0; i < N; i++)
sum += v[i];
return sum;
}
參考模式:
地址: 0 4 8 12 16
內容: v0 v1 v2 v3 v4
訪問順序: 1 2 3 4 5
??如上所示,向量v的元素是被順序讀取的,一個接一個,按照它們存盤在記憶體中的順序(為了方便,我們假設陣列是從地址0開始的),因此,對于變數v,函式有很好的空間區域性,但是時間區域性很差,因為每個向量元素只被訪問一次,
步長為1的參考模式為順序參考模式( sequential reference pattern),一個連續向量中,每隔k個元素進行訪問,就稱為步長為k的參考模式( stride-k reference pattern),步長為1的參考模式是程式中空間區域性常見和重要的來源,一般而言,隨著步長的增加,空間區域性下降,
??如下的函式 sumarrayrows,它對一個二維陣列的元素求和,雙重嵌套回圈按照行優先順序(row major order)讀陣列的元素,也就是,內層回圈讀第一行的元素,然后讀第二行,依此類推,函式 sumarrayrows具有良好的空間區域性,因為它按照陣列被存盤的行優先順序來訪問這個陣列,其結果是得到一個很好的步長為1的參考模式,具有良好的空間區域性,
int sum_array_rows(int a[M][N])
{
int i, j, sum = 0;
for (i = 0; i < M; i++)
for (j = 0; j < N; j++)
sum += a[i][j];
return sum;
}
參考模式:
地址: 0 4 8 12 16
內容: a00 a01 a02 a10 a11
訪問順序: 1 2 3 4 5
存盤器層次結構
??存盤技術和計算機軟體的一些基本的和持久的屬性:
??存盤技術:不同存盤技術的訪問時間差異很大,速度較快的技術每位元組的成本要比速度較慢的技術高,而且容量較小,CPU和主存之間的速度差距在增大,
??計算機軟體:一個撰寫良好的程式傾向于展示出良好的區域性,
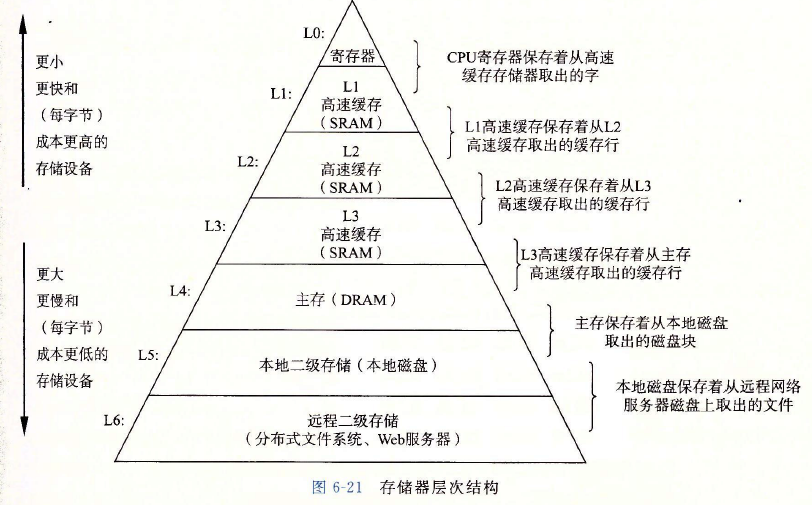
??硬體和軟體的這些基本屬性互相補充得很完美,它們這種相互補充的性質使人想到一種組織存盤器系統的方法,稱為存盤器層次結構( memory hierarchy),下圖展示了一個典型的存盤器層次結構,一般而言,從高層往底層走,存盤設備變得更慢、更便宜和更大,在最高層(L0),是少量快速的CPU暫存器,CPU可以在一個時鐘周期內訪問它們,接下來是一個或多個小型到中型的基于SRAM的高速快取存盤器,可以在幾個CPU時鐘周期內訪問它們,然后是一個大的基于DRAM的主存,可以在幾十到幾百個時鐘周期內訪問它們,接下來是慢速但是容量很大的本地磁盤,最后,有些系統甚至包括了一層附加的遠程服務器上的磁盤,要通過網路來訪問它們,
存盤器結構中的快取
??一般而言,高速快取( cache,讀作“cash”)是一個小而快速的存盤設備,它作為存盤在更大、也更慢的設備中的資料物件的緩沖區域,使用高速快取的程序稱為快取( caching,讀作“ cashing"),
??存盤器層次結構的中心思想是,對于每個k,位于k層的更快更小的存盤設備作為位于k+1層的更大更慢的存盤設備的快取,換句話說,層次結構中的每一層都快取來自較低一層的資料物件,
??資料總是以塊大小為傳送單元( transfer unit)在第k層和第k+1層之間來回復制的,雖然在層次結構中任何一對相鄰的層次之間塊大小是固定的,但是其他的層次對之間可以有不同的塊大小,如上圖所示,L1和L0之間的傳送通常使用的是1個字大小的塊,L2和L1之間(以及L3和I2之間、I4和I3之間)的傳送通常使用的是幾十個位元組的塊,而L5和L4之間的傳送用的是大小為幾百或幾千位元組的塊,一般而言,層次結構中較低層(離CPU較遠)的設備的訪問時間較長,因此為了補償這些較長的訪問時間,傾向于使用較大的塊,
快取命中
??當程式需要第k+1層的某個資料物件d時,它首先在當前存盤在第k層的一個塊中查找d,如果d剛好快取在第k層中,那么就是我們所說的快取命中( cache hit),
快取不命中
??另一方面,如果第k層中沒有快取資料物件d,那么就是我們所說的快取不命中( cache miss),當發生快取不命中時,第k層的快取從第k+1層快取中取出包含d的那個塊,如果第k層的快取已經滿了,可能就會覆寫現存的一個塊,(快取的替換策略:隨機替換替換策略,最少被使用(LRU)替換策略),
快取不命中種類
??區分不同種類的快取不命中有時候是很有幫助的,如果第k層的快取是空的,那么對任何資料物件的訪問都會不命中,一個空的快取有時被稱為冷快取( cold cache),此類不命中稱為強制性不命中( compulsory miss)或冷不命中( cold miss),冷不命中很重要,因為它們通常是短暫的事件,不會在反復訪問存盤器使得快取暖身( warmed up)之后的穩定狀態中出現,
快取管理
??存盤器層次結構的本質是,每一層存盤設備都是較低一層的快取,在每一層上,某種形式的邏輯必須管理快取,這里,我們的意思是指某個東西要將快取劃分成塊,在不同的層之間傳送塊,判定是命中還是不命中,并處理它們,管理快取的邏輯可以是硬體、軟體,或是兩者的結合,
高速快取存盤器
??高速快取關于讀的操作非常簡單,首先,在高速快取中查找所需字\(w\)的副本,如果命中,立即回傳字\(w\)給CPU,如果不命中,從存盤器層次結構中較低層中取出包含字\(w\)的塊,將這個塊存盤到某個高速快取行中(可能會驅逐一個有效的行),然后回傳字\(w\),
??寫的情況就要復雜一些了,假設我們要寫一個已經快取了的字\(w\)(寫命中, write hit),在高速快取更新了它的\(w\)的副本之后,怎么更新\(w\)在層次結構中緊接著低一層中的副本呢?最簡單的方法,稱為直寫( write-through),就是立即將\(w\)的高速快取塊寫回到緊接著的低一層中,雖然簡單,但是直寫的缺點是每次寫都會引起總線流量,另一種方法,稱為寫回( write-back),盡可能地推遲更新,只有當替換演算法要驅逐這個更新過的塊時,才把它寫到緊接著的低一層中,由于區域性,寫回能顯著地減少總線流量,但是它的缺點是增加了復雜性,高速快取必須為每個高速快取行維護一個額外的修改位( dirty bit),表明這個高速快取塊是否被修改過,
??另一個問題是如何處理寫不命中,一種方法,稱為寫分配( write-allocate),加載相應的低一層中的塊到高速快取中,然后更新這個高速快取塊,寫分配試圖利用寫的空間區域性,但是缺點是每次不命中都會導致一個塊從低一層傳送到高速快取,另一種方法,稱為非寫分配(not- write-allocate),避開高速快取,直接把這個字寫到低一層中,直寫高速快取通常是非寫分配的,寫回高速快取通常是寫分配的,
??高速快取既保存資料,也保存指令,只保存指令的高速快取稱為 i-cache,只保存程式資料的高速快取稱為 d-cache,既保存指令又包括資料的高速快取稱為統一的高速快取( unified cache),現代處理器包括獨立的 i-cache和d-cache,這樣做有很多原因,有兩個獨立的高速快取,處理器能夠同時讀一個指令字和一個資料字, i-cache通常是只讀的,因此比較簡單,通常會針對不同的訪問模式來優化這兩個高速快取,它們可以有不同的塊大小,相聯度和容量,使用不同的高速快取也確保了資料訪問不會與指令訪問形成沖突不命中,反過來也是一樣,代價就是可能會引起容量不命中增加,
撰寫高速快取友好的代碼
??確保代碼高速快取友好的基本方法,
??1)讓最常見的情況運行得快,程式通常把大部分時間都花在少量的核心函式上,而這些函式通常把大部分時間都花在了少量回圈上,所以要把注意力集中在核心函式里的回圈上,而忽略其他部分,
??2)盡量減小每個回圈內部的快取不命中數量,在其他條件(例如加載和存盤的總次數)相同的情況下,不命中率較低的回圈運行得更快,
??考慮如下的函式
int sumvec(int v[N])
{
int i,sum = 0;
for(i = 0;i<N;i++)
sum +=v[i];
return sum;
}
??首先,注意對于區域變數i和sum,回圈體有良好的時間區域性,現在考慮一下對向量v的步長為1的參考,一般而言,如果一個高速快取的塊大小為B位元組,那么一個步長為k的參考模式(這里k是以字為單位的)平均每次回圈迭代會有\(\min (1,(wordsize \times k)/B)\)次快取不命中,當k=1時,它取最小值,所以對v的步長為1的參考確實是高速快取友好的,
??例如,假設v是塊對齊的,字為4個位元組,高速快取塊為4個字,而高速快取初始為空(冷高速快取),在這個例子中,對v[0]的參考會不命中,而相應的包含v[0] ~v[3]的塊會被從記憶體加載到高速快取中,因此,接下來三個參考都會命中,對v[4]的參考會導致不命中,而個新的塊被加載到高速快取中,接下來的三個參考都命中,依此類推,總的來說,四個參考中,三個會命中,在這種冷快取的情況下,這是我們所能做到的最好的情況了,
??總之,簡單的 sumvec示例說明了兩個關于撰寫高速快取友好的代碼的重要問題:第一,對區域變數的反復參考是好的,因為編譯器能夠將它們快取在暫存器檔案中(時間區域性),第二,步長為1的參考模式是好的,因為存盤器層次結構中所有層次上的快取都是將資料存盤為連續的塊(空間區域性),
總結
??本章主要介紹了各種各樣的存盤系統及其原理,一般來說,較小、較快的設備在頂部,較大、較慢的設備在底部,因為撰寫良好的程式有好的區域性,大多數資料都可以從較高層得到服務,結果就是存盤系統能以較高層的速度運行,但卻有較低層的成本和容量,我們可以通過撰寫有良好空間和時間區域性的程式來顯著地改行程式的運行時間,例如,可以利用基于SRAM的高速快取存盤器,主要原因是從高速快取取資料的程式比主要從記憶體取資料的程式運行得快得多,
??養成習慣,先贊后看!如果覺得寫的不錯,歡迎關注,點贊,轉發,謝謝!
有任何問題,均可通過公告中的二維碼聯系我
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/247027.html
標籤:嵌入式