KubeSphere 開源社區的小伙伴們,大家好,我是微眾銀行大資料平臺的工程師周可,接下來給大家分享的是基于 WeDataSphere 和 KubeSphere 這兩個開源社區的產品去構建一個云原生機器學習平臺 Prophecis,
Prophecis 是什么?
首先我介紹一下什么是 Prophecis (Prophecy In WeDataSphere)?它的中文含義就是預言的意思,
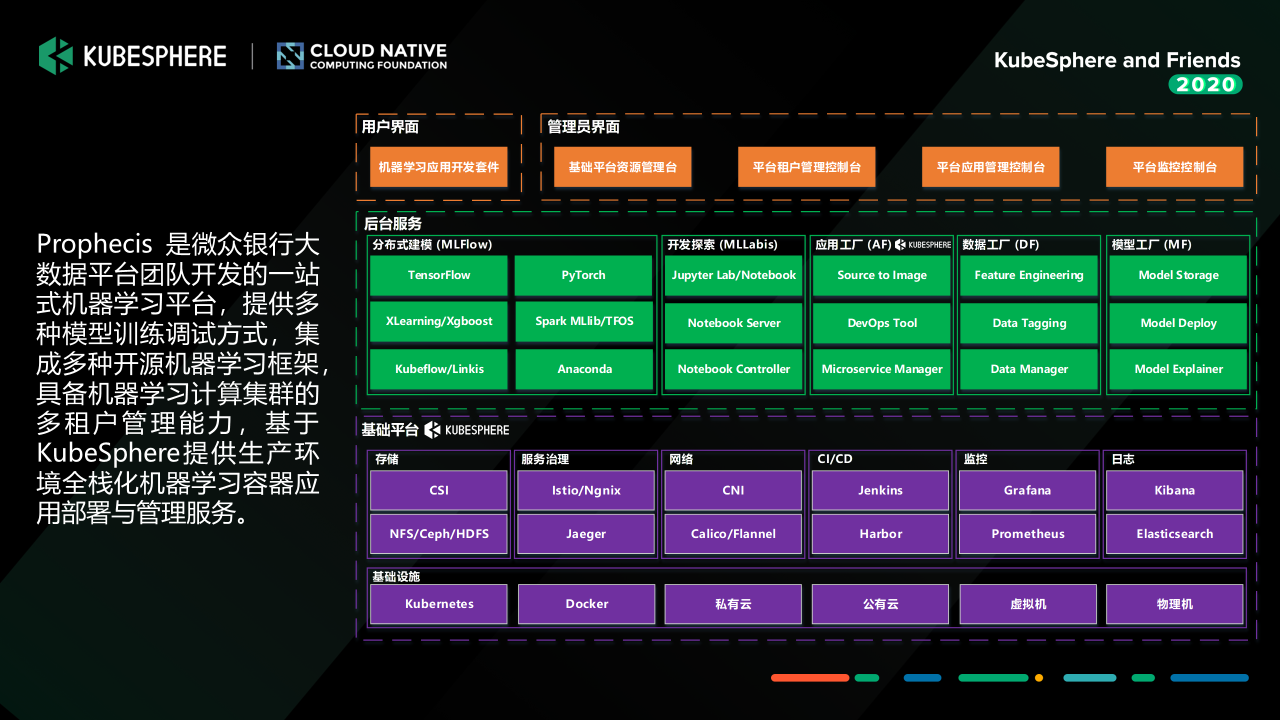
Prophecis 是微眾銀行大資料平臺團隊開發的一站式機器學習平臺,我們是基于KubeSphere管理的這一套多租戶的容器化的高性能計算平臺之上,搭建了我們提供給資料科學和演算法工程師,以及我們的IT運維去使用的機器學習平臺,
在互動界面層,大家可以看到最上面我們是有面向普通用戶的一套機器學習應用開發界面,以及面向我們運維管理員的一套管理界面,其中管理員的界面基本上就是基于 KubeSpehre 之上做了一些定制和開發;中間的服務層是我們機器學習平臺的幾個關鍵服務,主要為:
- Prophecis Machine Learning Flow:機器學習分布式建模工具,具備單機和分布式模式模型訓練能力,支持Tensorflow、Pytorch、XGBoost等多種機器學習框架,支持從機器學習建模到部署的完整Pipeline;
- Prophecis MLLabis:機器學習開發探索工具,提供開發探索服務,是一款基于Jupyter Lab的在線IDE,同時支持GPU及Hadoop集群的機器學習建模任務,支持Python、R、Julia多種語言,集成Debug、TensorBoard多種插件;
- Prophecis Model Factory:機器學習模型工廠,提供機器學習模型存盤、模型部署測驗、模型管理等服務;
- Prophecis Data Factory:機器學習資料工廠,提供特征工程工具、資料標注工具和物料管理等服務;
- Prophecis Application Factory:機器學習應用工廠,由微眾銀行大資料平臺團隊和AI部門聯合共建,基于青云(QingCloud)開源的 KubeSphere 定制開發,提供 CI/CD 和 DevOps 工具,GPU 集群的監控及告警能力,
最底層的基礎平臺就是 KubeSphere 管理的高性能容器化計算平臺,
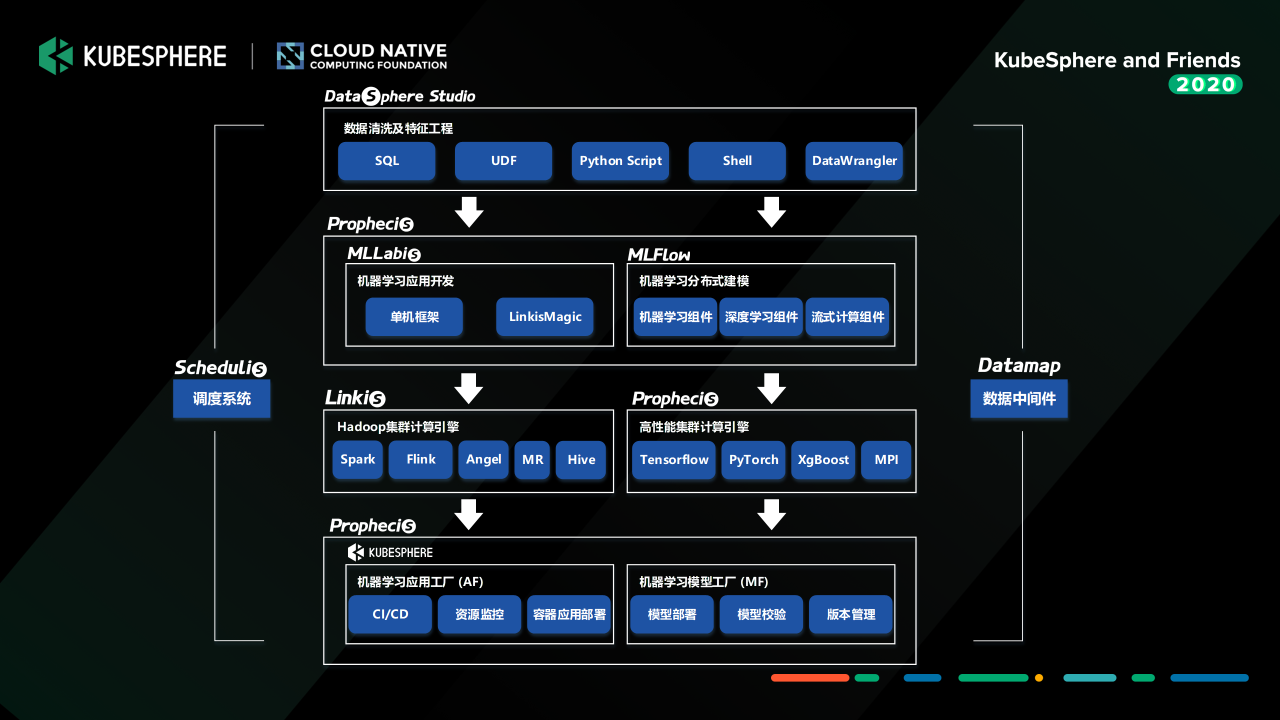
我們去構建這樣一套面向我們當前金融場景或者互聯網場景的機器學習平臺的時候,我們有兩個考慮的點:
第一個點是一站式,就是工具要全,從整個機器學習應用開發的整體的Pipeline去提供一個完整的生態鏈工具給到用戶去使用;
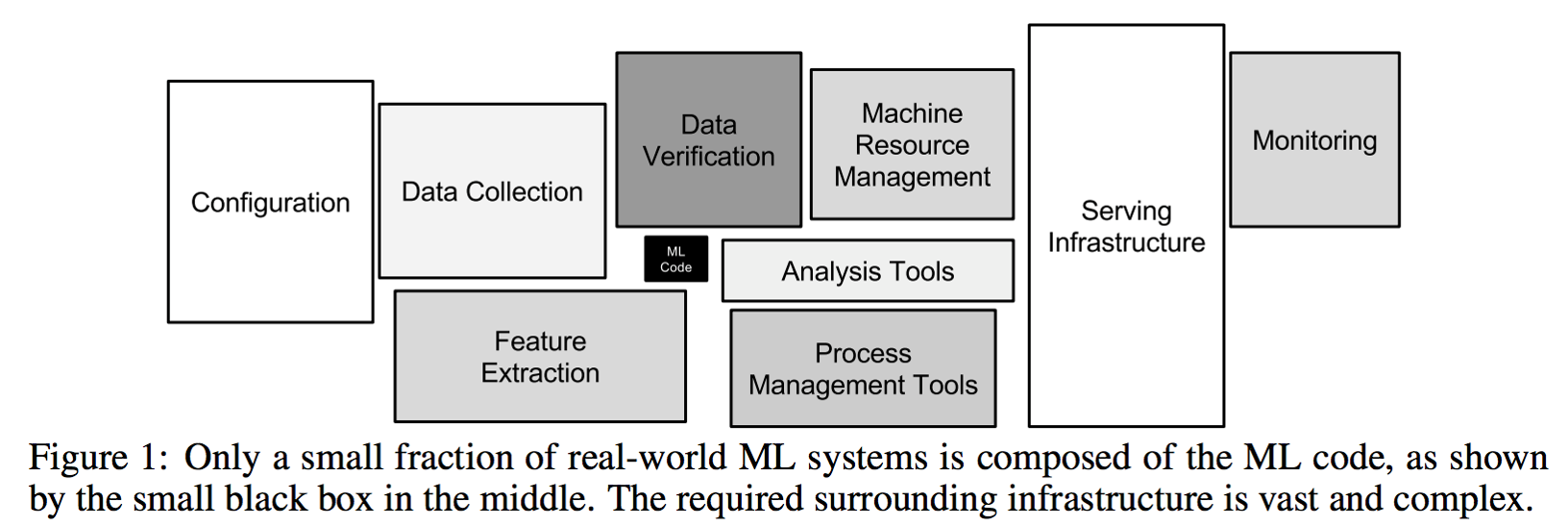
另外一個關注點是全聯通,我們去做我們去做機學習應用開發的時候有一個很大的痛點,大家可能之前看到 Google 有一張圖,可能 90% 的作業都是在做機器學習之外的作業,然后真正去做模型調參這些東西的時候,可能就 10% 的作業,
因為前面的資料處理其實是有很大作業量的,我們去做的一個作業就是,通過插件化接入的方式把我們的 Prophecis 的服務組件,跟我們 WeDataSphere 上面目前已經提供的調度系統 Schedulis、資料中間件 DataMap、計算中間件 Linkis、還有面向資料應用開發門戶的 DataSphere Stduio 這一整套工具鏈進行打通,構建一個全聯通的機器學習平臺,
Prophecis 功能組件簡介
接下來,簡單介紹一下我們機器學習平臺 Prophecis 的各個組件的功能,
第一個是我們目前已經放到開源社區的組件叫 MLLabis,其實跟 AWS 的提供給機器學習開發人員去用的 SageMaker Studio 差不多,
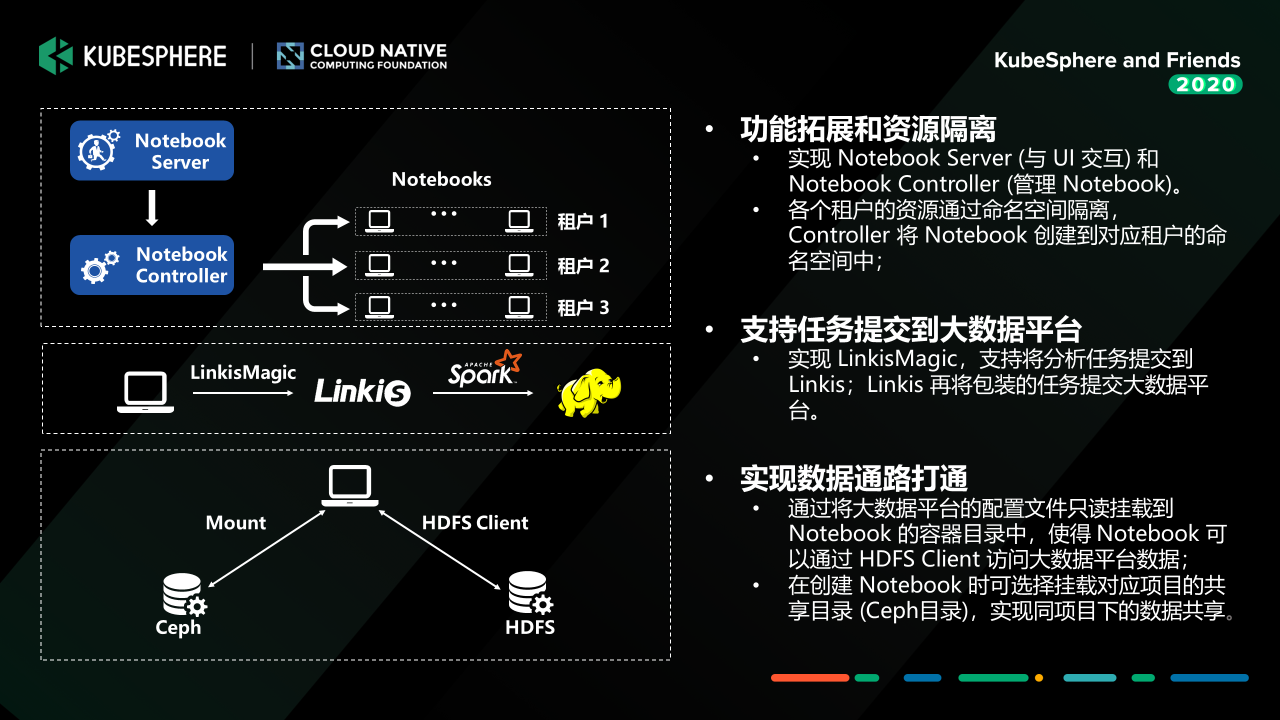
我們在 Jupyter Notebook 做了一些定制開發,總體的架構其實就是左上角的這張圖,其實主要的核心有兩個組件,一個是 Notebook Server (Restful Server),提供 Notebook 生命周期管理的各種API介面;另外一個是 Notebook Controller (Jupyter Notebook CRD),管理 Notebook 的狀態,
用戶創建 Notebook 的時候,他只需要選擇有權限的命名空間 (Kubernetes Namespace),然后去設定 Notebook運行時需要的一些引數,比如說 CPU、記憶體、 GPU 或者是它要掛載的存盤,如果一切正常,這個 Notebook 容器組就會在對應的 Namespace 啟動并提供服務,
我們在這里做了一個比較加強的功能,就是提供一個叫 LinkisMagic 的組件,如果了解到我們的 WeDataSphere 開源產品的話,有個組件叫 Linkis,它提供大資料平臺計算治理能力,打通各個底層的計算、存盤組件,然后給到上層去構建資料應用,
我們的 LinkisMagic 通過呼叫 Linkis 的介面,就可以將 Jupyter Notebook 中寫好的資料處理的代碼提交到大資料平臺上去執行;我們可以把處理好的特征資料通過 Linkis 的資料下載介面拉到 Notebook 的掛載存盤中去,這樣我們就可以在我們的容器平臺里面用 GPU 去做一些加速的訓練,
存盤方面,目前 MLLabis 提供兩種資料存盤,一種是 Ceph;一種是我們的大資料平臺 HDFS,關于 HDFS 這里提一句,我們其實就是把 HDFS Client 和 HDFS 的組態檔通過 Mount 到容器中,并且控制好權限,就可以在容器內跟 HDFS 互動了,
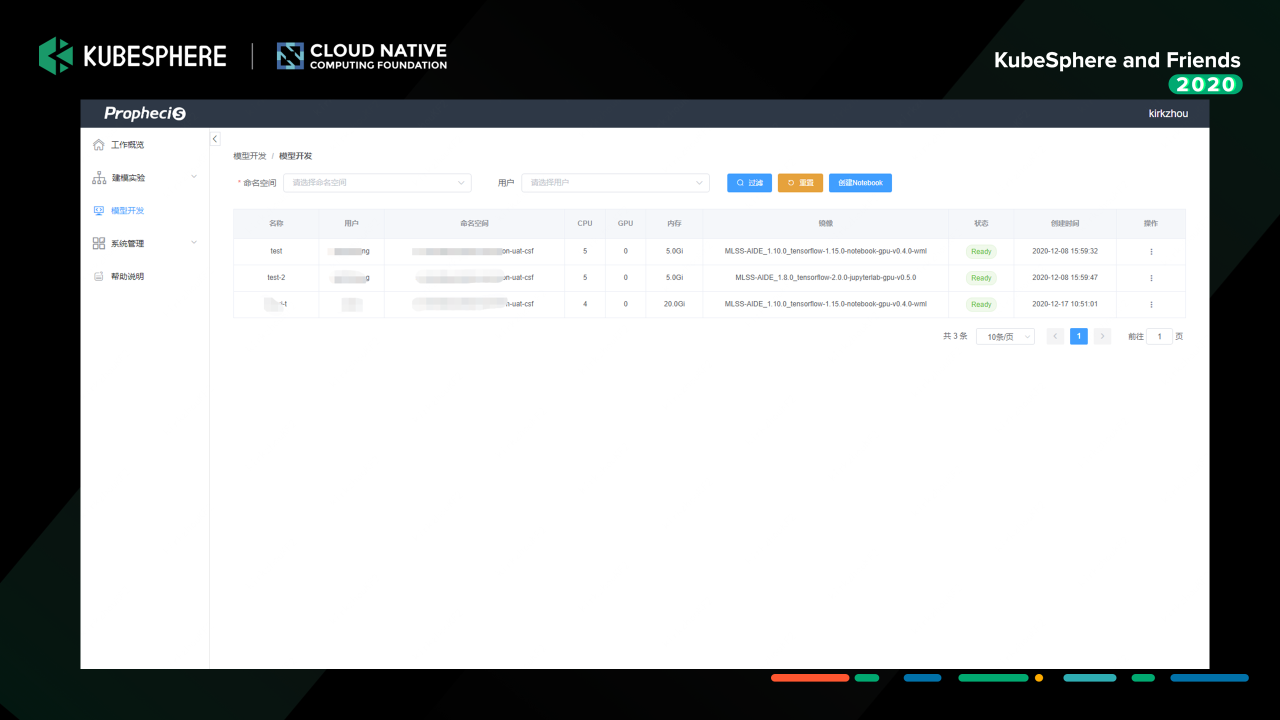
這是我們 MLLabis 的 Notebook 串列頁面;

這是我們從串列頁面進到 Notebook 的界面,
接下來,介紹我們另外一個組件 MLFlow,
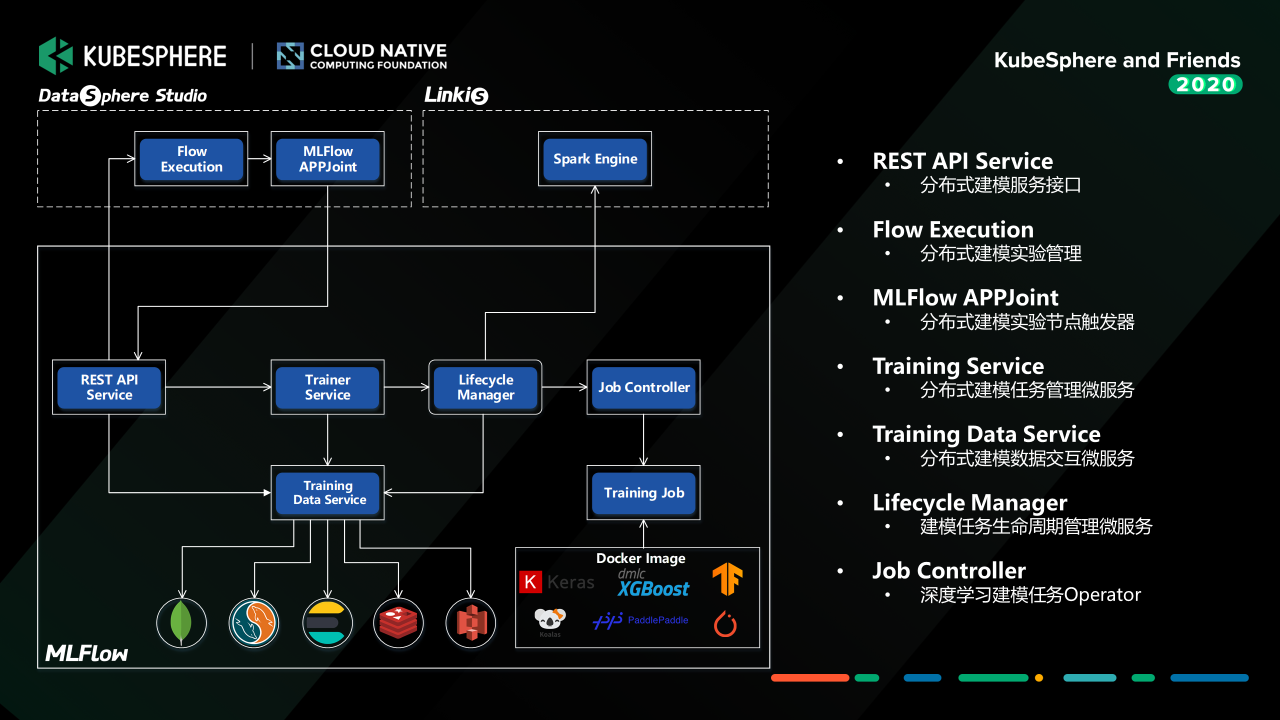
我們構建了一個分布式的機器學習實驗管理服務,它既可以管理單個建模任務,也可以通過跟我們 WeDataSphere 一站式資料開發門戶 DataSphere Studio 打通,構建一個完整的機器學習實驗,這里的實驗任務通過 Job Controller (tf-operator、pytorch-operator、xgboost-operator 等)管理運行在容器平臺上,也可以通過 Linkis 提及到資料平臺運行,
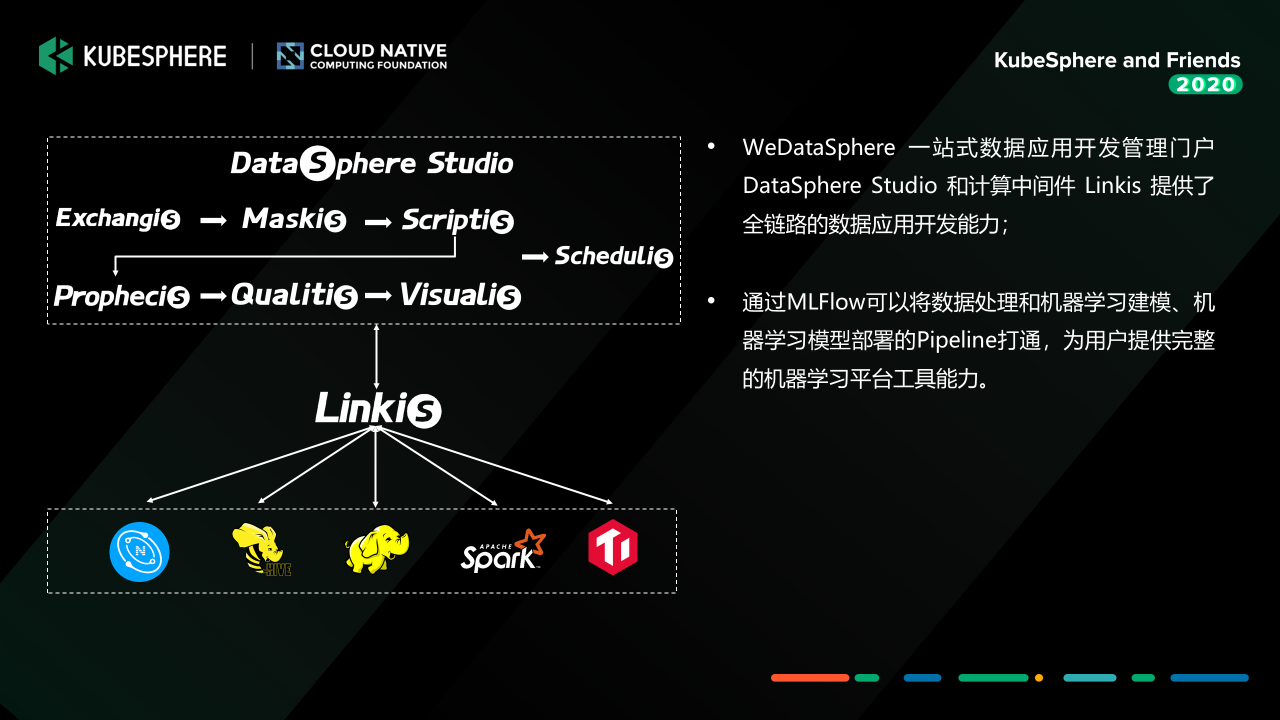
這里再說明一下,MLFlow 與 DataSphere Studio 之間通過 AppJoint 的方式互動,這樣既可以復用 DSS 已經提供的作業流管理能力,又可以將 MLFlow 實驗作為子作業流接入到 DSS 這個大的資料作業流中去,這樣構建一個從資料預處理到機器學習應用開發的 Pipeline,
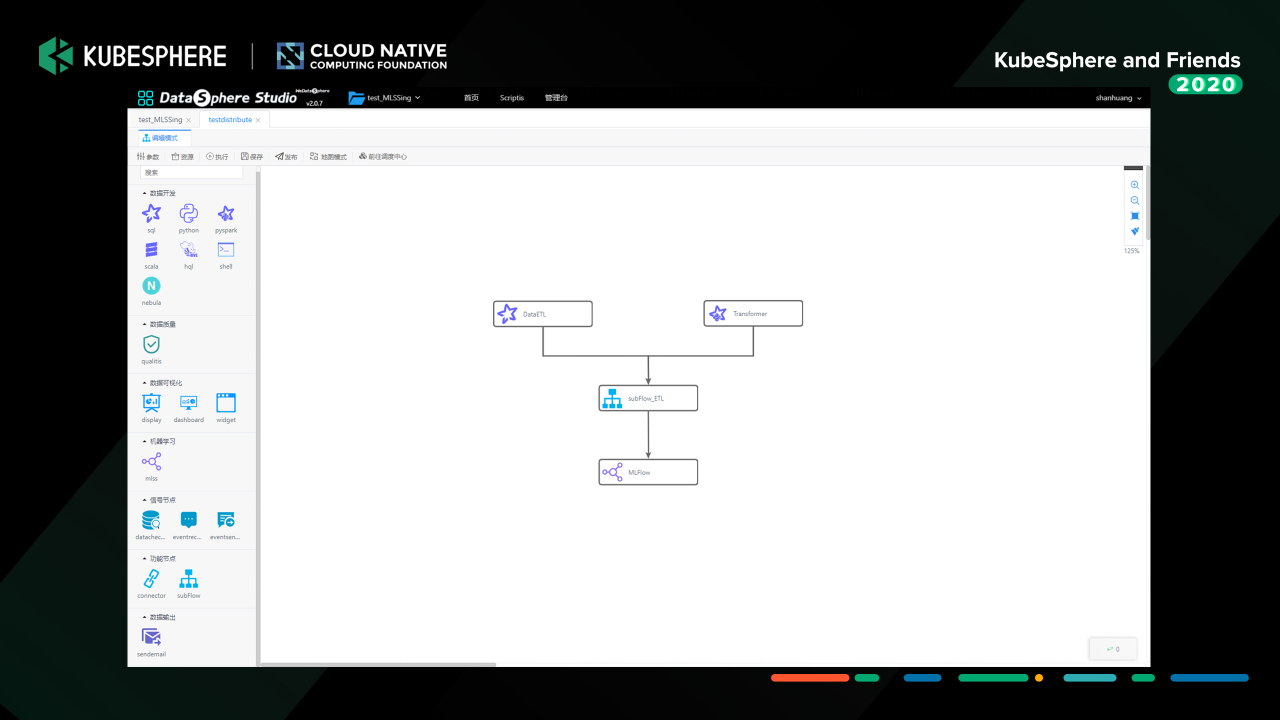
這個是我們資料處理和機器學習實驗組成的完成資料科學作業流,
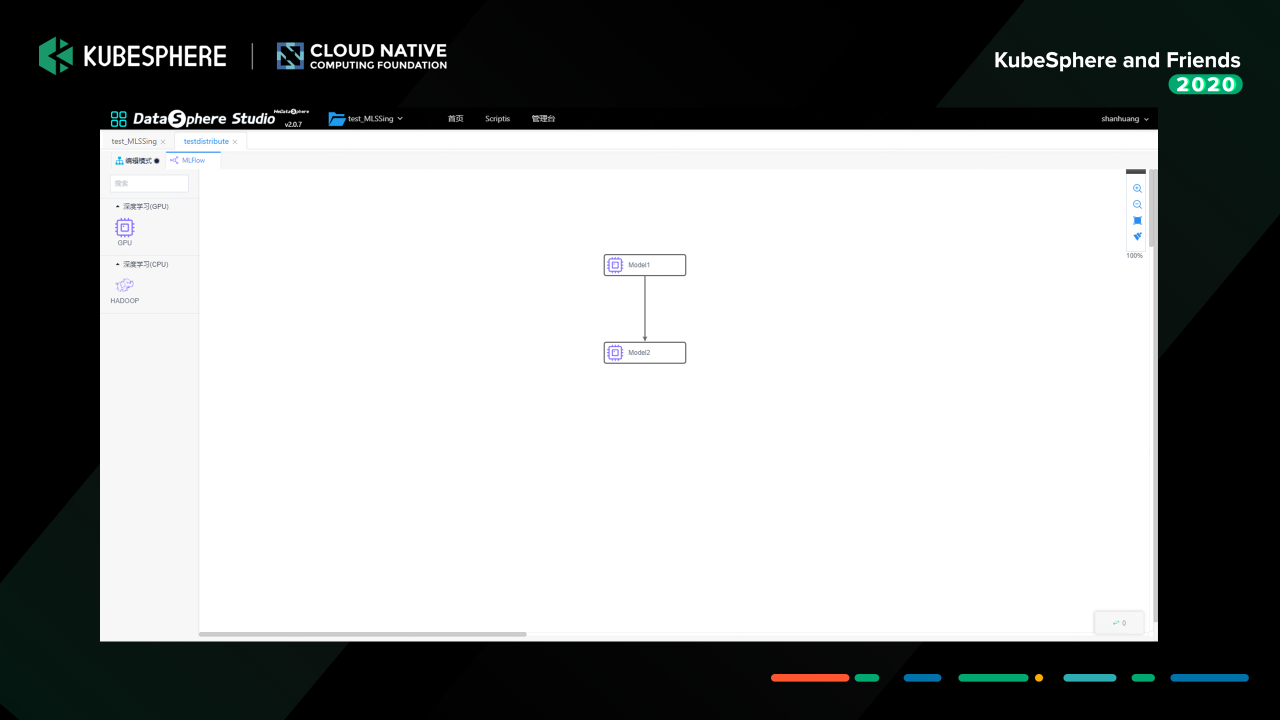
這個是 MLFlow 的機器學習實驗 DAG 界面,目前提供 GPU 和 CPU 兩種任務型別,支持 TensorFlow、PyTorch、xgboost 等機器學習框架任務的單機和分布式執行,
接下來給大家介紹我們的機器學習模型工廠:Model Factory,我們模型建好之后,我們怎么去管理這些模型,它的模型的版本怎么管理,它的部署怎么管理,模型的校驗怎么做,我們用的就是 Model Factory,
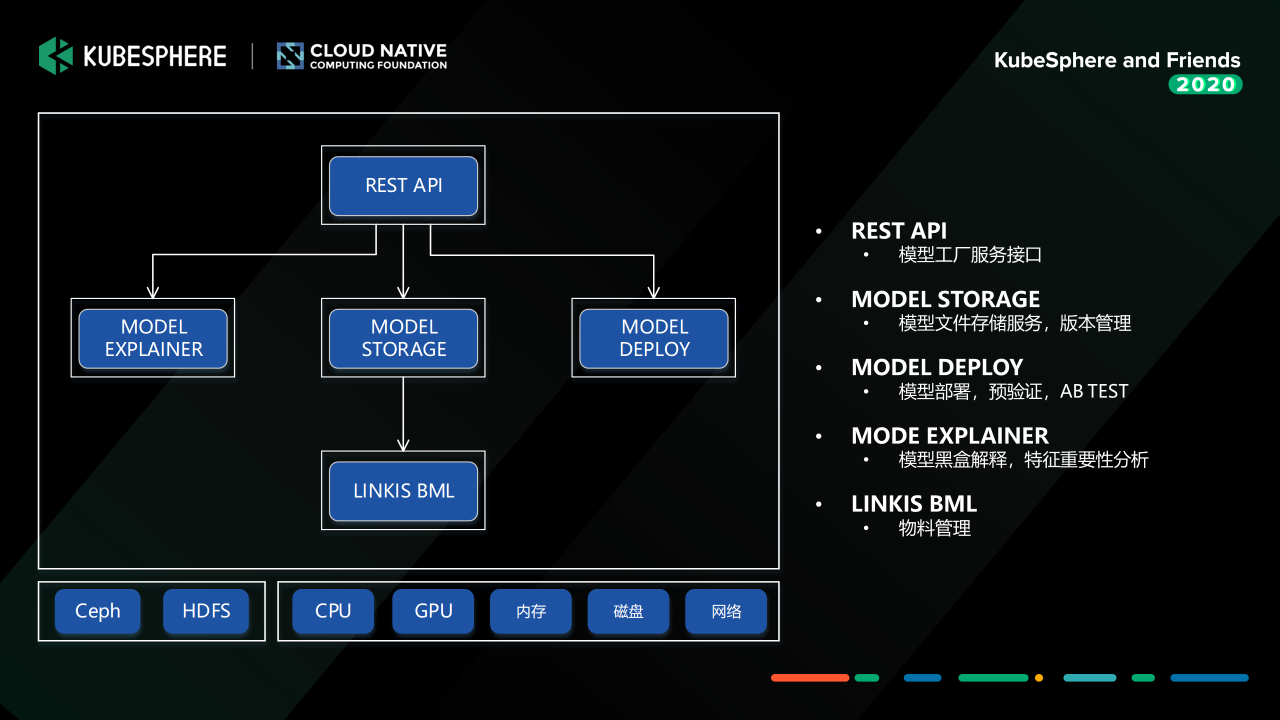
這個服務我們主要是基于 Seldon Core 進行二次開發,提供模型解釋、模型存盤、模型部署三塊的能力,要強調的一點是這一塊的服務介面我們也可以接入到 MLFlow 中去,作為一個 Node 接入到機器學習實驗中,這樣訓練好的模型,可以通過界面配置快速部署,然后進行模型驗證,
另外一個要說明的是,如果我們只是單模型的驗證,我們主要是使用MF提供的基于 Helm 的部署能力,如果是構建一個復雜的生產可用的推理引擎,我們還是會用 KubeSphere提供的 CI/CD、微服務治理能力去構建和管理模型推理服務,
接著要介紹的組件是我們資料工廠 Data Factory,
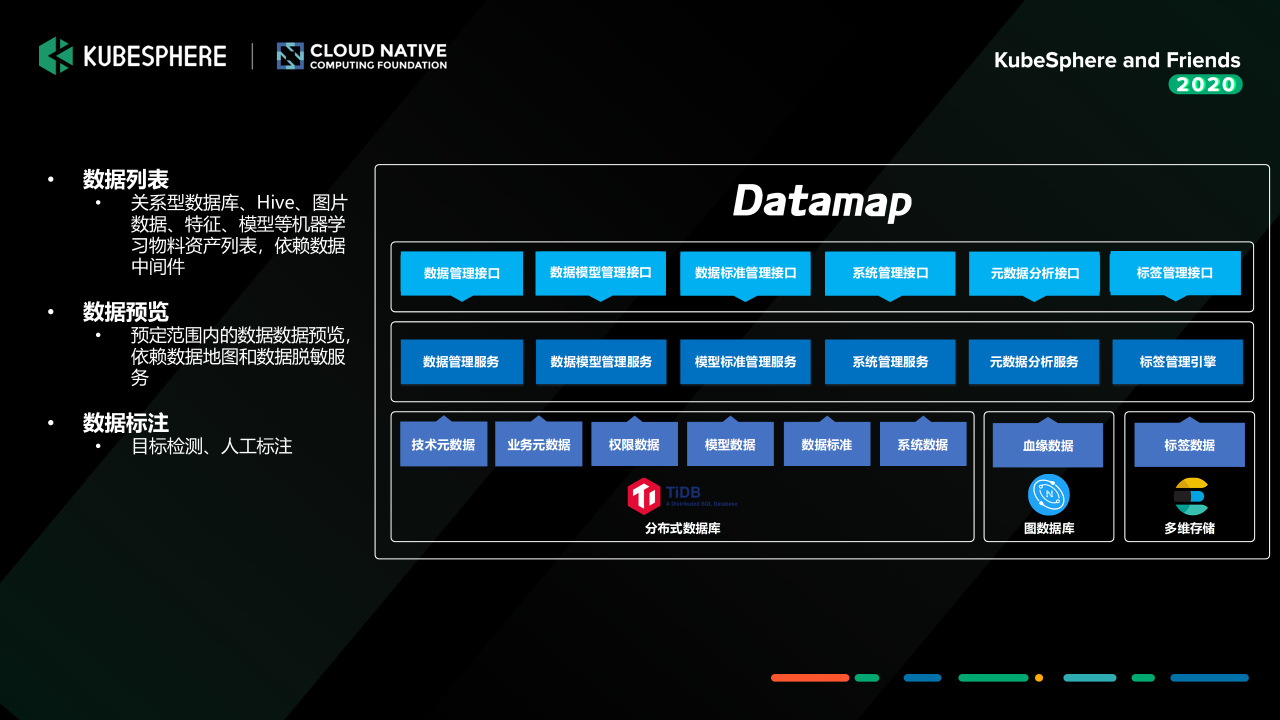
我們這個資料工廠的話,我們通過資料發現服務從 Hive、MySQL、HBase、Kafka 等資料組件中獲取基礎的元資料,并提供資料預覽和資料血緣分析能力,告訴我們資料科學和建模人員,他要使用的資料是長什么樣子的,可以怎么用,未來也會提供一些資料標注的工具,或者是資料眾包的工具,讓我們的資料開發同學來完成資料標注的這塊的作業,
最后一個要介紹的組件,就是機器學習應用工廠 Application Factory,
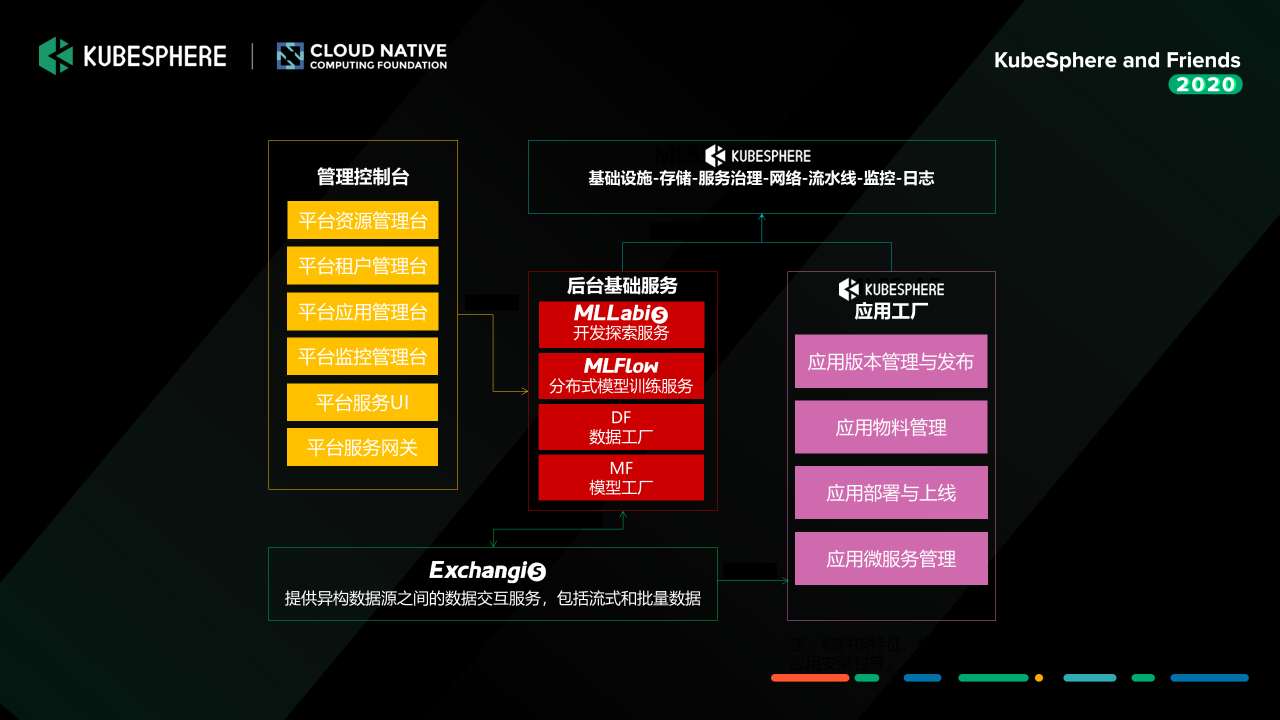
就是剛才說的,我們如果對一些復雜的模型去構建一些復雜的 Inference Sevice 的時候,其實我們用一個簡單的單容器服務其實是不夠的,我們要去構成一整套的類似于 DAG 的一個推理的程序,這個時候其實我們就需要更復雜的容器應用的管理的能力,
Application Factory 這一塊我們就是基于 KubeSphere 去做的,我們在前面做好這些模型的準備之后,我們會使用 KubeSphere 提供的 CI/CD 作業流去完成整體的模型應用發布流程,模型服務上線之后,使用 KubeSphere 提供的各種 OPS 工具去運維和管理各個業務方的服務,
KubeSphere應用實踐
接下來進入到 KubeSphere 在我們微眾銀行應用實踐部分,

我們在引入 KubeSphere 之前,其實我們面對的問題,主要還是一些運維的問題,當時,我們內部也有用我們自己寫的一些腳本或者是 Ansible Playbook 去管理我們這一套或者幾套 K8s 集群,包括我們在公有云上面的開發測驗集群,以及行內私有云的幾套生產K8s集群,但是這一塊的話,因為我們的運維人力有限,去管理這塊東西的時候其實是非常復雜的;我們的建好的模型是面向銀行業務使用,有的是跟風控相關的,對于整體服務的可用性的要求還是很高的,我們如何做好各個業務方的租戶管理、資源使用管控、以及怎么去構成一個完整的監控體系,也是我們去需要重點關注的;還有就是本身 Kubernetes Dashboard 基本上沒什么可以管理的能力,所以我們還是希望有一套好用的管理界面給了我們的運維人員,讓他們的運維效率更高一些,
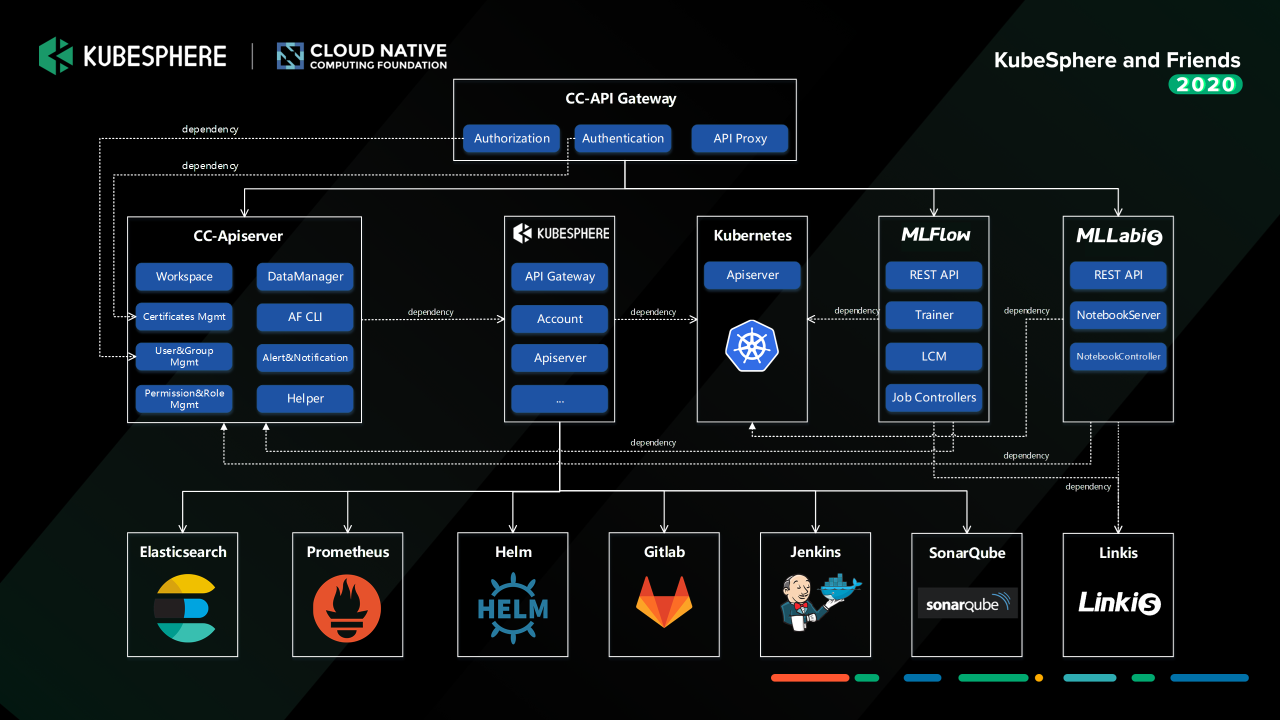
因此,我們構建這樣一個基于 KubeSphere 為基礎運維管理基座的機器學習容器平臺,
整體的服務架構基本是跟 KubeSphere 當前的 API 架構差不多,用戶的請求進來之后,它通過 API Gateway 定位要訪問服務,這些服務就是剛才介紹那些組件,Gateway 將請求分發到對應的微服務當中去,各個服務依賴的那些容器平臺的管理,就是 KubeSphere 這一套能力去給我們提供的能力:CI/CD、監控、日志管理,還有代碼掃描工具等,然后我們在這一套解決方案之上做了一些改造點,但總體來說改造的東西也不是特別多,因為當前開源的 KubeSphere 提供的這些能力基本上能滿足我們的需求,
我們內部使用的版本是 KubeSphere 的 v2.1.1,我們改造主要如下:
-
監控和告警:我們把 KubeSphere Notification 和我們行內的監控告警心態進行了打通,同時將容器實體的配置資訊和我們的 CMDB 系統中管理的業務資訊進行關聯,這樣某個容器出現例外就可以通過我們告警資訊發出告警訊息,并告訴我們影響的是哪個業務系統;
-
資源管理:我們在 KubeSphere Namespace 資源配額管理上做了一點小小的拓展,支持 Namespace 的 GPU 資源配額管理,可以限制各個租戶可以用使用的基礎 GPU 資源和最大 GPU 資源;
-
持久化存盤:我們將容器的內的關鍵服務存盤都掛載到我們行內的高可用的分布式存盤 (Ceph) 和資料庫 (MySQL) 上,保障資料存盤的安全性和穩定性,
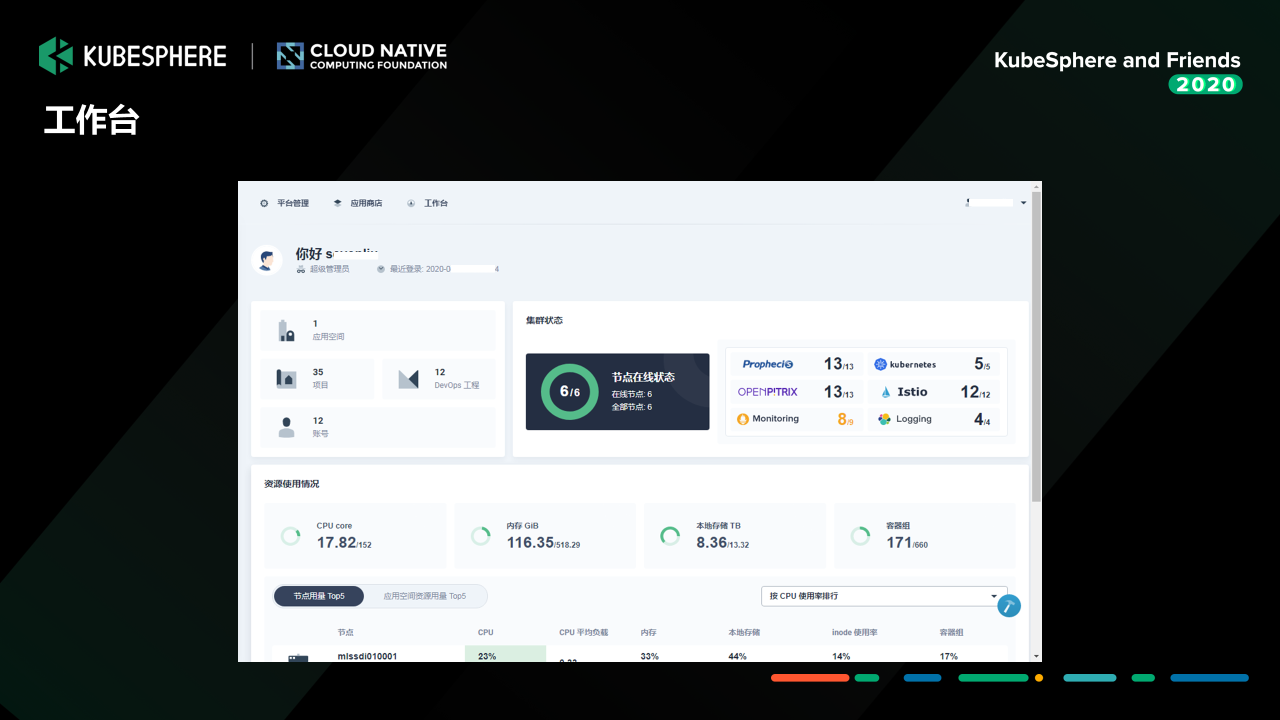
這是我們測驗環境的一個管理界面,
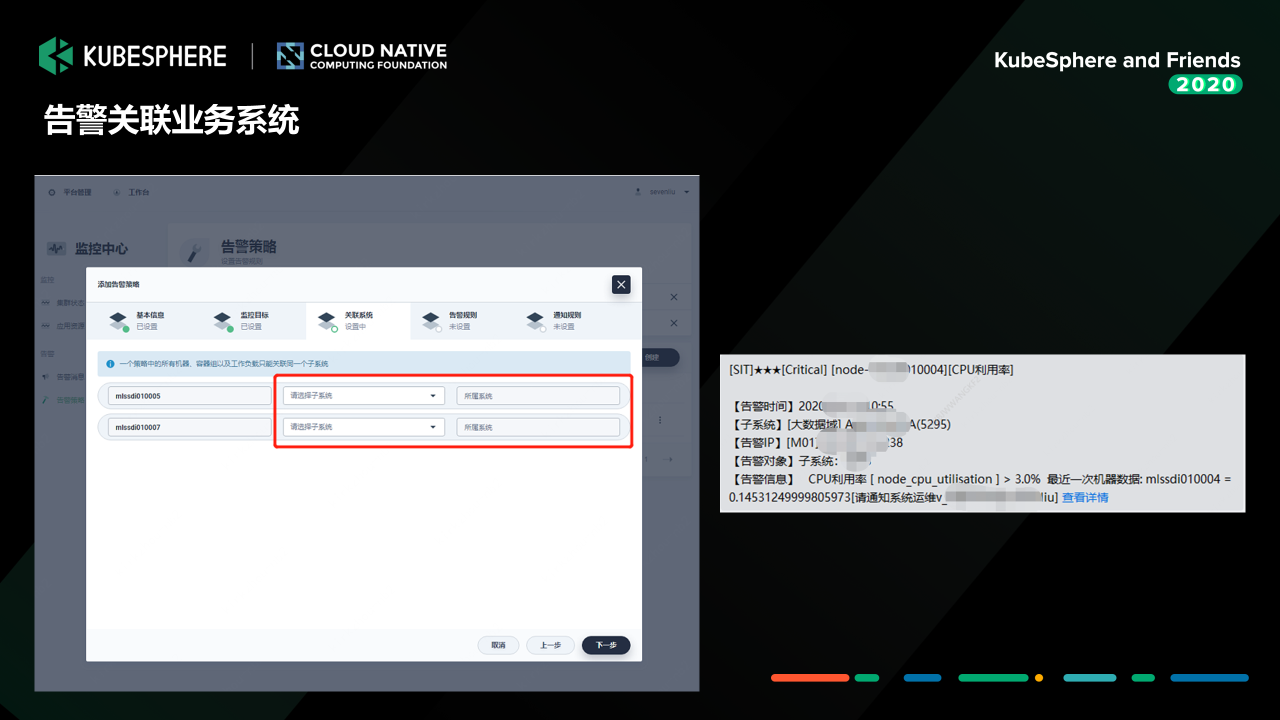
然后這個是我們剛才說的,其實我們這一塊的話做兩個事情,一個事情是說我們把整個監控的物件跟我們行內的這一套 CMDB 系統進行一個結合,告警的時候,我們通過跟這套 CMDB 系統去做配置關聯的,我們可以知道這一個告警實體它影響了的業務系統是哪些,然后一旦出現例外的時候,我們就會通過呼叫我們的告警系統,這里是一個企業微信的一個告警資訊,當然它也可以發微信,也可以打電話,也可以發郵件,
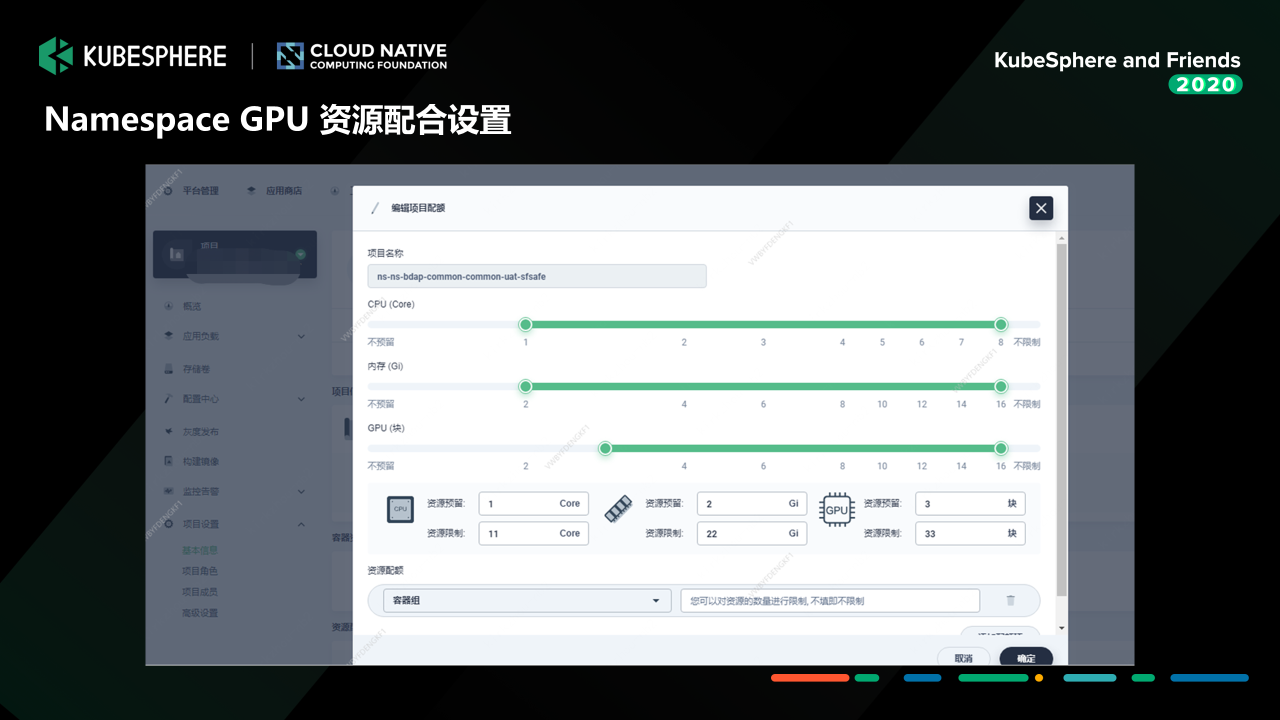
以上這一塊是我們做的 GPU 資源配額定制,
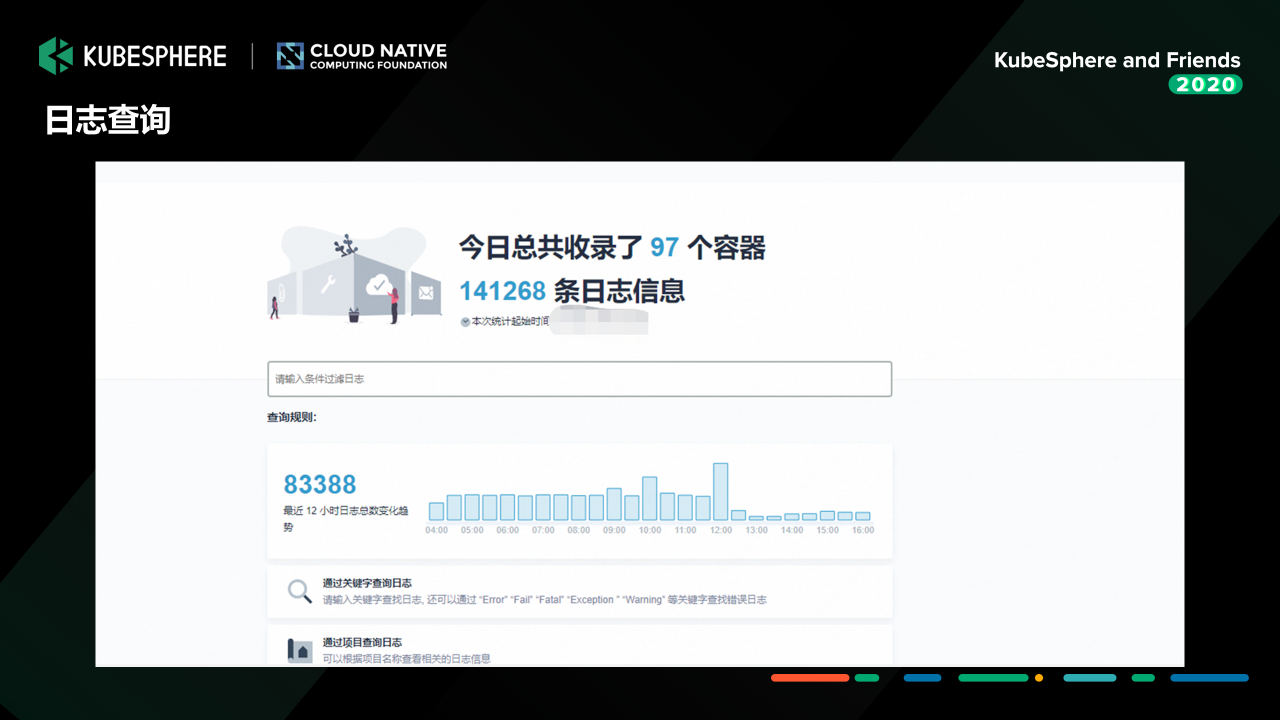
這一塊是我們基于 KubeSphere 的日志查詢界面,

接下來說下未來的展望,其實說到這里的話,我們當前因為我們人力非常有限,然后各個組件開發的壓力也比較大,然后目前的話我們還是基于之前的 KubeSphere v2.1.1 的版本去做的,我們接下來的話會去考慮會把 KubeSphere 3.0 這塊的東西去跟我們現有開發的一些能力做結合和適配,
第二,目前 KubeSphere還是沒有 GPU 監控和統計指標管理的一些能力,我們也會考慮去把我們之前做的一些東西或者一些界面能力遷移到 KubeSphere Console 里面去,
最后一個是我們整個 WeDataSphere 各個的組件基于 KubeSphere 的容器化適配和改造,我們最終是希望各個組件都完成容器化,進一步降低運維管理成本和提升資源利用率,
關于 WeDataSphere
說到這里,我就簡單再介紹一下我們微眾銀行大資料平臺 WeDataSphere,
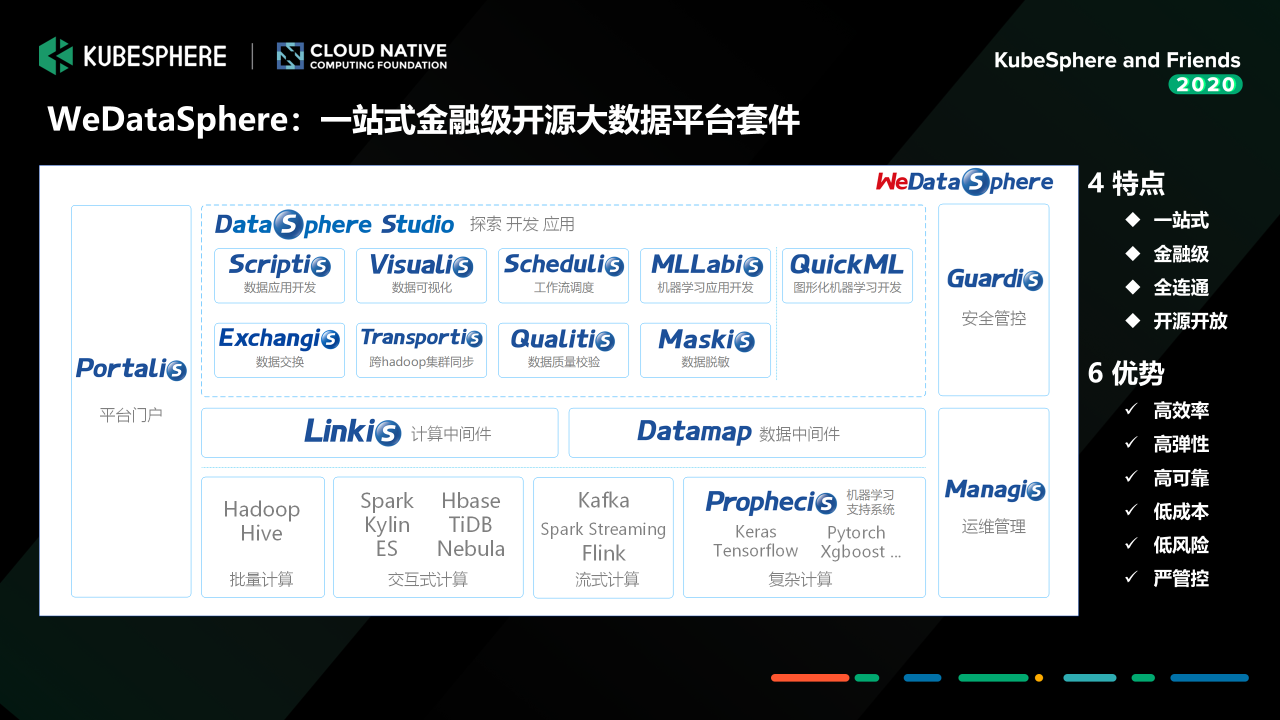
WeDataSphere 是我們大資料平臺實作的一整套金融級的一站式機器學習大資料平臺套件,它提供從資料應用開發、到中間件、在到底層的各個組件功能能力,還有包括我們的整個平臺的運維管理門戶、到我們的一些安全管控、還有運維支持的這塊一整套的運營管控能力,

目前的話,這些組件當中沒有置灰的這部分已經開源了,如果大家感興趣的話可以關注一下,

再展望一下,我們 WeDataSpehre 跟 KubeSphere 的未來,目前我們兩個社區已經官宣開源合作,
我們計劃把我們 WeDataSphere 大資料平臺這些組件全部能容器化,然后貢獻到 KubeSpehre 應用商店中,幫助我們用戶去快速和高效的完成我們這些組件與應用的生命周期管理、發布,

歡迎大家關注我們 Prophecis 這個開源專案以及我們 WeDataSphere 開源社區助手,如果大家對這套開源的云原生機器學習平臺有任何問題,可以跟我們進一步交流,謝謝大家,
關于 KubeSphere
KubeSphere 是在 Kubernetes 之上構建的容器混合云,提供全堆疊的 IT 自動化運維的能力,簡化企業的 DevOps 作業流,
KubeSphere 已被 Aqara 智能家居、本來生活、新浪、中國人保壽險、華夏銀行、浦發硅谷銀行、四川航空、國藥集團、微眾銀行、紫金保險、Radore、ZaloPay 等海內外數千家企業采用,KubeSphere 提供了運維友好的向導式操作界面和豐富的企業級功能,包括多云與多集群管理、Kubernetes 資源管理、DevOps (CI/CD)、應用生命周期管理、微服務治理 (Service Mesh)、多租戶管理、監控日志、告警通知、存盤與網路管理、GPU support 等功能,幫助企業快速構建一個強大和功能豐富的容器云平臺,
KubeSphere 官網:https://kubesphere.io/
KubeSphere GitHub:https://github.com/kubesphere/kubesphere

本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/257639.html
標籤:Linux
上一篇:Linux重定向用法詳解