大家好,我是痞子衡,是正經搞技術的痞子,今天痞子衡給大家介紹的是恩智浦i.MX RT1xxx系列EVK在串行NOR Flash除錯的原理,
本文是i.MXRT硬體那些事系列第二篇的續集,在第二篇首集中痞子衡給大家詳細介紹了EVK板載除錯器用法,有了除錯器在手,從此除錯不用愁,從除錯代碼所在目標存盤器類別上來分,除錯一般分為在SRAM除錯和在Flash除錯,在SRAM除錯實作比較簡單,程式直接從JTAG/SWD口灌進RAM即可;在Flash除錯,則相對復雜一點,因為首先需要有Flash下載演算法,下載成功后才能除錯,
通常的Cortex-M內核MCU一般都會內嵌并行NOR Flash,這個并行NOR Flash是直接掛在Cortex-M內核高性能AHB總線上的,知名IDE如果支持這款MCU,也都會同時集成對應Flash的下載演算法,方便用戶直接在IDE里下載代碼進Flash和XIP除錯,但是i.MXRT內部并沒有Flash,用戶需要自己外接Flash,那該怎么辦?還能在線XIP除錯么?別著急,i.MXRT可以支持外接并行NOR和串行NOR實作XIP,從節省管腳數的角度,最常見的做法是將串行NOR Flash掛在i.MXRT FlexSPI總線上,FlexSPI支持XIP特性,所以原理上可以實作在線除錯,今天痞子衡就為大家介紹i.MXRT上在外部串行Flash除錯的原理:
一、ARM CoreSight除錯架構
要實作在串行Flash除錯,首先要能對內核進行除錯,i.MXRT芯片是基于Cortex-M內核的,而Cortex內核的除錯和跟蹤,當然離不開CoreSight,它是ARM公司于2004年推出的一種新的除錯體系結構,也是內核授權的一部分,
CoreSight功能非常強大,其包含了很多除錯組件(即各種協議),下圖來自于 CoreSight技術簡介手冊,圖中標出了CoreSight架構下的各種除錯組件之間的聯系,這么多組件一下子看起來會有點暈,如果我們按功能將這些組件分組,它們可以被分成如下三組:
- 源部件(Source):芯片上跟蹤資料的來源,產生跟蹤資料發送到ATB(AMBA Trace Bus),比如STM和ETM都屬于Source部分,
- 控制訪問部件(Sink):配置和控制資料流的產生,但是不產生資料流,即那些可以保持從Source過來資料的模塊,比如DAP和ECT(包含CTI和CTM)都屬于Sink部分,
- 匯聚點(Link):芯片上跟蹤資料的終點,用于引導從Source到Sink程序中的類似于通道作用的模塊,比如TPIU、ETB和SWO都屬于匯聚點,
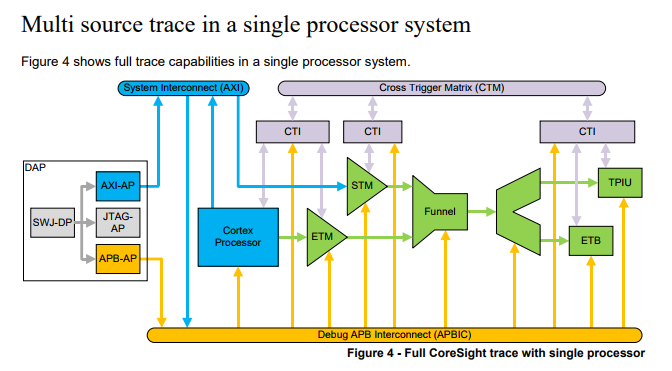
本文主要是概述性地介紹i.MXRT在外部串行Flash除錯的原理,并不想深入探析CoreSight,因此對于CoreSight,我們只需要知道是它完成了主要的除錯作業,而CoreSight唯一的依賴就是要保證能通過DAP組件從AMBA總線實時訪問系統記憶體和外設暫存器(當然包括外部串行Flash中的代碼),
二、i.MXRT FlexSPI外設特性
要實作在串行Flash除錯,其次是代碼要能在串行Flash中XIP(原地執行),即CPU要能實時從串行Flash中任意位置取指令和資料,本文講的串行Flash一般指SPI介面的NOR Flash,SPI模式可以是Single/Dual/Quad/Octal,無論是哪種SPI模式,這種介面的Flash本質上都屬于串行Flash,地址線和資料線不僅共享而且是串行的,而按照通常的理解,要能夠實作XIP,Flash應該是并行總線介面掛在AMBA上,這個并行總線應有獨立的地址線和資料線,且地址線寬度跟Flash大小相對應,那么串行Flash為什么能在i.MXRT上實作XIP呢?答案就是FlexSPI外設,
讓我們打開RT1050參考手冊,找到FlexSPI外設章節,可以看到如下FlexSPI模塊框圖,框圖右邊是FlexSPI與外部串行Flash的信號連接,框圖左邊是FlexSPI與i.MXRT系統內部總線連接,總線連接分為兩種,分別是32bit IPS BUS(即手動操作FlexSPI暫存器發送Flash讀寫命令),64bit AHB BUS(由FlexSPI翻譯AHB訪問地址并自動發送相應Flash讀寫命令),串行Flash能夠XIP的奧秘就在FlexSPI外設的AHB BUS連接,
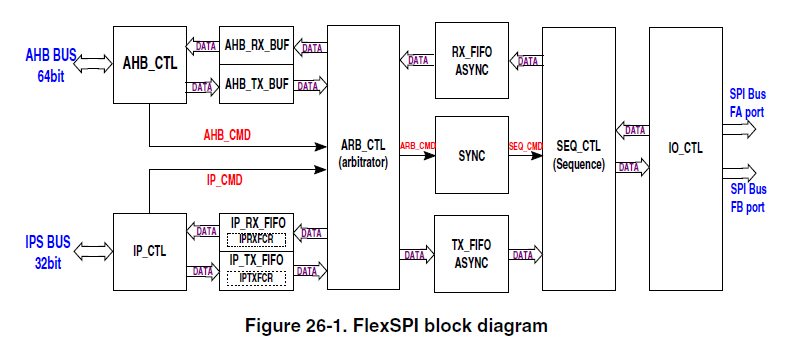
關于這個64bit AHB BUS連接,我們可以FlexSPI特性里的Memory mapped read/write access by AHB Bus一欄找到更多細節,i.MXRT為FlexSPI外設在系統記憶體里分配了AHB訪問地址映射(對于XIP除錯來說主要是讀訪問),當CPU取指到FlexSPI AHB地址映射空間時,FlexSPI外設會自動完成從外部串行Flash讀取指令資料的作業,并將指令資料存放到AHB RX buffer里(一共8個),CPU直接從AHB RX buffer里獲取指令去執行,AHB RX buffer可以有效降低讀延時,
- AHB RX Buffer implemented to reduce read latency. Total AHB RX Buffer size: 128 x 64 Bits
- 16 AHB masters supported with priority for read access
- 8 flexible and configurable buffers in AHB RX Buffer
- AHB TX Buffer implemented to buffer all write data from one AHB burst. AHB TX Buffer size: 8 x 64 Bits
- All AHB masters share this AHB TX Buffer. No AHB master number limitation for Write Access.
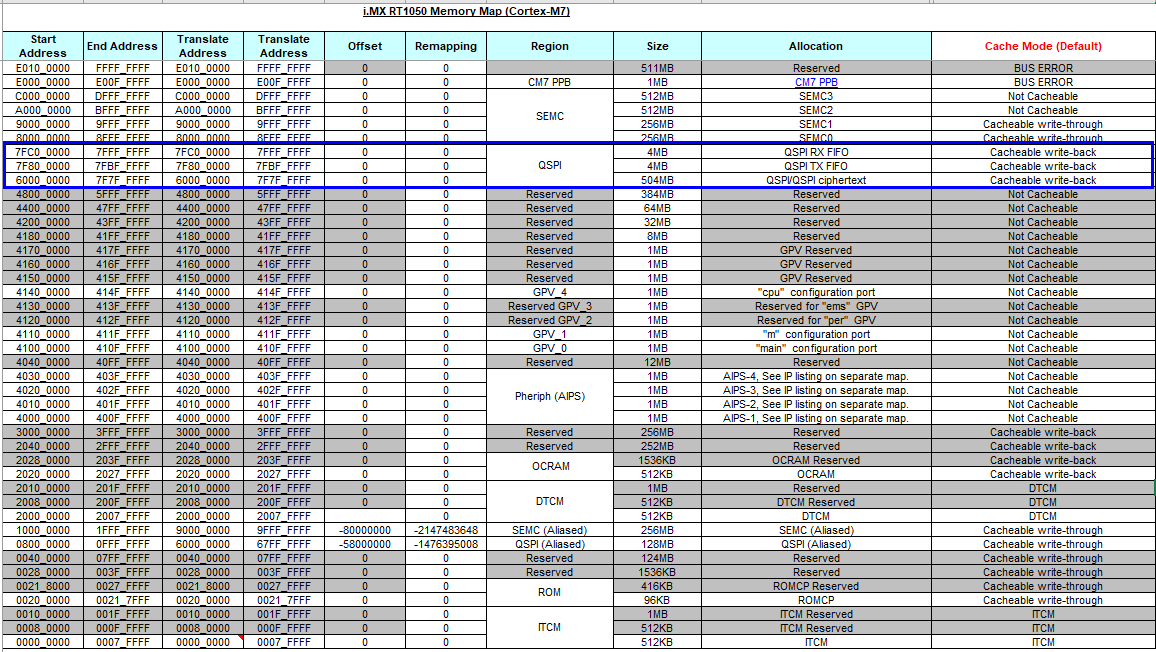
關于FlexSPI AHB地址映射,可見下面的RT1050 memory map表,AHB映射起始地址為0x60000000,最大支持504MB的空間(適用RT1010/RT1020/RT1050/RT1060),如果是RT1064,AHB映射起始地址改為0x70000000;如果是RT1170,除了0x60000000映射地址外還新增了0x30000000的地址映射,FlexSPI AHB映射地址讀訪問包含以下特點:
- Cachable and Non-Cachable access
- Prefetch Enable/Disable
- Burst size: 8/16/32/64 bits
- All burst type: SINGLE/INCR/WRAP4/INCR4/WRAP8/INCR8/WRAP16/INCR16
三、串行NOR Flash下載演算法
要實作在串行Flash除錯,最后要確保代碼被成功下載到串行Flash中,串行Flash的讀寫不像訪問RAM那樣簡單,是需要一套專門的FlexSPI NOR Flash驅動的,即所謂的Flash下載演算法,
串行Flash種類很多,雖然大多都符合JESD216標準,但是具體到某個廠家生產的Flash,還是有細微區別的,有的Flash下載演算法力求支持盡可能多的Flash,而有的Flash下載演算法則僅針對某個系列Flash,不管是哪種Flash下載演算法,對于i.MXRT這樣沒有內部Flash的芯片而言,Flash下載演算法都是要跟具體的i.MXRT開發板相關聯的,因為開發板決定了Flash連接的pinmux,Flash下載演算法里FlexSPI管腳初始化要與開發板相匹配,
每個IDE的Flash下載演算法設計不盡相同,本文暫不詳細介紹具體Flash下載演算法,后續文章會對常見IDE的Flash下載演算法設計進行詳解,
四、在串行Flash除錯程序
CoreSight架構,FlexSPI特性,NOR Flash下載演算法都介紹過了,在串行Flash除錯的充分條件都有了,現在痞子衡為大家綜合介紹一下除錯程序,下面是痞子衡特地畫的簡圖,其實除錯程序概述起來并不復雜,當你啟動IDE除錯時,預先放在IDE里的Flash下載演算法(可執行檔案)會首先通過除錯器下載到i.MXRT內部FlexRAM中,下載演算法需要提供FlexSPI外設初始化和NOR Flash擦除、燒寫功能API,然后除錯器繼續將應用程式代碼(二進制機器碼)分段快取在FlexRAM里,并呼叫Flash下載演算法API去完成應用程式的燒寫(從FlexRAM到Flash中),應用程式完全下載結束之后,便由CoreSight開始接管除錯作業,此時CPU已經可以通過AHB總線訪問掛在FlexSPI外設上的串行Flash里的應用程式代碼資料,所以CoreSight當然可以完成實時代碼運行控制與跟蹤,你在IDE里也就可以進行單步除錯啦,
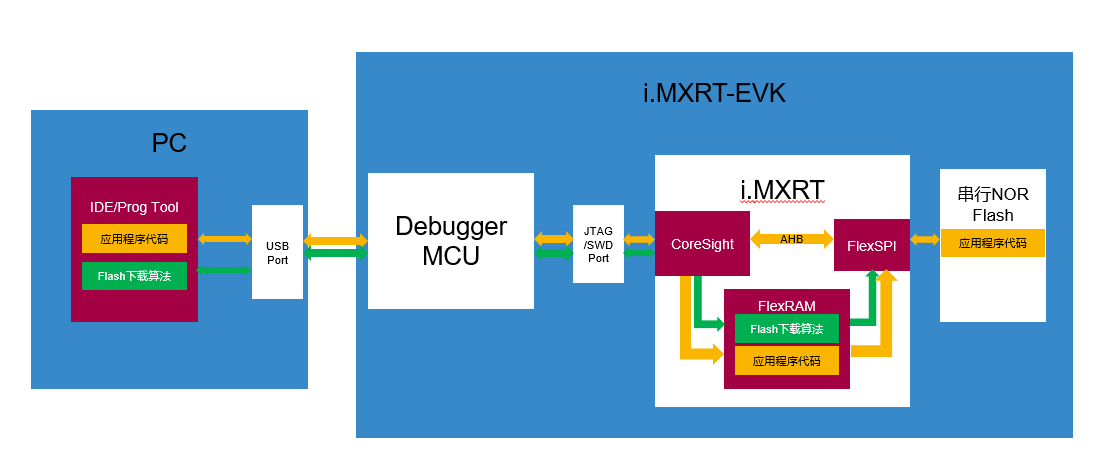
至此,恩智浦i.MX RT1xxx系列EVK在串行NOR Flash除錯的原理痞子衡便介紹完畢了,掌聲在哪里~~~
歡迎訂閱
文章會同時發布到我的 博客園主頁、CSDN主頁、微信公眾號 平臺上,
微信搜索"痞子衡嵌入式"或者掃描下面二維碼,就可以在手機上第一時間看了哦,

轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/27177.html
標籤:嵌入式