前言
做為一個性能測驗工程師,每當我們發現計算機變慢的時候,我們通常的標準姿勢就是執行 uptime 或 top 命令,來了解系統的負載情況,
比如像下面這樣,我在命令列里輸入了 uptime 命令,系統會回傳一行資訊,
-
appletekimbp:~ apple$ uptime -
20:44 up 21 days, 6:41, 2 users, load averages: 2.85 2.33 2.91
但我想問的是,各位同學知道以上每列輸出的含義嗎?
-
20:44 # 當前時間 -
up 21 days, 6:41 # 系統運行時間 -
2 users # 正在登錄用戶數 -
-
# 系統的平均負載,分別是1分鐘、5分鐘、15分鐘內系統的平均負載 -
load averages: 2.85 2.33 2.91
這行資訊的后半部分,顯示 "load average",它的意思是"系統的平均負載",里面有三個數字,我們可以從中判斷系統負載是大還是小,
什么是系統平均負載?
我猜一定會有同學會說,平均負載不就是單位時間的 CPU 使用率嗎?上面 2.85,就代表 CPU 使用率是 285%,其實不是這樣的,
CPU 負載值在 Linux 系統中表示正在運行,處于可運行狀態的平均作業數(讀取一組與流程執行執行緒對應的機器語言的程式指令),或者非常重要,休眠但不可中斷(不可交錯的休眠狀態)),也就是說,要計算 CPU 負載的值,只考慮正在運行或等待分配 CPU 時間的行程,不考慮正常的休眠程序(休眠狀態),僵尸或停止的程序,
簡單來說,平均負載是指單位時間內,系統處于可運行狀態和不可中斷狀態的平均行程數,也就是平均活躍行程數,它和 CPU 使用率并沒有直接關系,
行程狀態代碼 R 正在運行或可運行(在運行佇列中) D 不間斷休眠(通常為IO) S 可中斷休眠(等待事件完成) Z 失效/僵尸,終止但未被其父 T 停止,由作業控制停止信號或因為它被追蹤 [...]
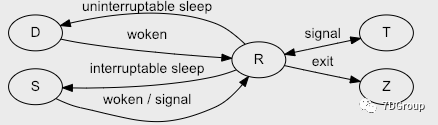
這里先解釋下,可運行狀態和不可中斷狀態,
可運行狀態的行程,指的是正在使用CPU或者正在等待CPU的行程,也就是我們常用 ps 命令看到處于 R 狀態(Running 或 Runnable)的行程,
不可中斷狀態的行程,指的是正處于內核態關鍵流程中的行程,并且這些流程是不可打斷的,比如常見是等待硬體設備的 I/O 回應,也就是我們在Ps 命令看到的D狀態(Uninterruptible Sleep,也稱為 Disk Sleep)的行程, 比如,當一個行程向磁盤讀寫資料時,為了保證資料的一致性,在得到磁盤回復前,它是不能被其他行程或者中斷打斷的,這個時間的行程就處于不可中斷狀態,如果此時的行程被打斷,就容易出現磁盤資料與行程資料不一致的問題,
所以,不可中斷狀態實際上是系統對行程和硬體設備的一種保護機制,
因此,我們可以簡單理解為,平均負載其實就是平均活躍行程數,平均活躍行程數,直觀上的理解就是單位時間內的活躍行程數, 既然平均的是是活躍行程數,那么理想的是,每個CPU上都剛好運行著一個行程,這樣每個CPU都得到了充分利用,
以下是單核處理器計算機中不同負載值的含義:
-
0.00:沒有任何作業正在運行或等待 CPU 執行,即 CPU 完全空閑,因此,如果正在運行的程式(行程)需要執行任務,它會向 CPU 請求作業系統,并立即為該行程分配 CPU 時間,因為沒有其他行程在競爭它,
-
0.50:沒有任何作業在等待,但 CPU 正在處理以前的作業,并且它正在以 50% 的容量進行處理,在這種情況下,作業系統還可以立即將 CPU 時間分配給其他行程,而無需將其置于保持狀態,
-
1.00:佇列中沒有作業,但 CPU 正在以 100% 的容量處理先前的作業,因此如果新行程請求 CPU 時間,則必須將其保留到另一個作業完成或當前 CPU 插槽時間(例如,CPU tick)到期,作業系統決定哪一個是下一個給定的行程優先級,
-
1.50:CPU 作業在其容量的 100%,15個作業中有5個請求CPU時間,即 33.33%,必須排隊等待其他人耗盡他們分配的時間,因此,一旦超過1.0 的閾值,就可以說系統過載,因為它不能立即處理所請求的 100% 的作業,
那么很顯然,"load average"的值越低,比如等于0.2或0.3,就說明服務器的作業量越小,系統負載比較低,
一個類比
上面還看太懂怎么辦?沒事,我們來看一個簡單的類比例子,
先假設最簡單的情況,你的計算機只有一個 CPU,所有的運算都必須由這個 CPU 來完成,
那么,我們不妨把這個 CPU 想象成一座大橋,橋上只有一根車道,所有車輛都必須從這根車道上通過,(很顯然,這座橋只能單向通行,)
系統負載為 0,意味著大橋上一輛車也沒有,

系統負載為 0.5,意味著大橋一半的路段有車,

系統負載為 1.0,意味著大橋的所有路段都有車,也就是說大橋已經"滿"了,但是必須注意的是,直到此時大橋還是能順暢通行的,

系統負載為 1.7,意味著車輛太多了,大橋已經被占滿了(100%),后面等著上橋的車輛為橋面車輛的 70%,以此類推,系統負載 2.0,意味著等待上橋的車輛與橋面的車輛一樣多;系統負載 3.0,意味著等待上橋的車輛是橋面車輛的 2 倍,總之,當系統負載大于 1,后面的車輛就必須等待了;系統負載越大,過橋就必須等得越久,

CPU 的系統負載,基本上等同于上面的類比,大橋的通行能力,就是CPU 的最大作業量;橋梁上的車輛,就是一個個等待 CPU 處理的行程(process),
如果CPU 每分鐘最多處理100個行程,那么系統負載0.2,意味著CPU在這 1 分鐘里只處理 20 個行程;系統負載 1.0,意味著 CPU 在這 1 分鐘里正好處理 100 個行程;系統負載 1.7,意味著除了 CPU 正在處理的100 個行程以外,還有 70 個行程正排隊等著CPU處理,
為了計算機順暢運行,系統負載最好不要超過 1.0,這樣就沒有行程需要等待了,所有行程都能第一時間得到處理,很顯然,1.0 是一個關鍵值,超過這個值,系統就不在最佳狀態了,你要動手干預了,
多處理器和多核系統
在具有多個處理器或核心(多個邏輯 CPU)的系統中,CPU 負載值的含義取決于系統中存在的處理器數量,因此,具有4 個處理器的計算機在達到4.00的負載之前將不會以100%使用,因此在解釋由 top,htop 或正常運行時間等命令提供的3個負載值時,你必須要做的第一件事 就是將它們分開,系統中存在的邏輯CPU數量,并從中得出結論,
舉個例子,如果你的計算機裝了 2 個 CPU,會發生什么情況呢? 2 個 CPU,意味著計算機的處理能力翻了一倍,能夠同時處理的行程數量也翻了一倍, 還是用大橋來類比,兩個 CPU 就意味著大橋有兩根車道了,通車能力翻倍了

所以,2 個CPU表明系統負載可以達到 2.0,此時每個 CPU 都達到 100%的作業量,推廣開來,n 個 CPU 的計算機,可接受的系統負載最大為n.0,
芯片廠商往往在一個 CPU 內部,包含多個CPU核心,這被稱為多核CPU,
在系統負載方面,多核 CPU 與多 CPU 效果類似,所以考慮系統負載的時候,必須考慮這臺計算機有幾個 CPU、每個 CPU 有幾個核心,然后,把系統負荷除以總的核心數,只要每個核心的負荷不超過 1.0,就表明計算機正常運行, 怎么知道PC有多少個 CPU 核心呢?
CPU使用率
如果我們觀察在給定時間間隔內通過 CPU 的不同行程,則利用率百分比將表示相對于 CPU 執行與每個行程相對應的指令的那個時間間隔的時間部分,但這種計算只運行的行程,而不是那些正在等待,無論它們是在佇列(可運行狀態)還是休眠但不可中斷(例如在等待輸入/輸出操作的結束)被認為, 因此,這個指標可以讓我們了解哪些行程最大程度地擠壓 CPU,但是如果系統狀態過載或者未充分利用,則不能給出真實的系統狀態圖,
現實作業中,我們經常容易把平均負載和 CPU 使用率混淆,從上面我們知道平均負載是指單位時間內,處于可運行狀態和不可中斷狀態的行程數,所以,它不僅包括正在使用 CPU 的行程,還包括等待 CPU 和等待I/O 的行程,而 CPU使用率,從上面的解釋我們知道是單位時間內繁忙程度,跟平均負載并不一定完全對應,比如:
-
CPU 密集型行程,使用大量 CPU 會導致平均負載升高,這時候兩者是一致的,
-
I/O 密集型行程,等待 I/O 也會導致平均負載升高,但 CPU 使用率不一定很高,
-
大量等待 CPU 的行程調度也會導致平均負載很高,此時的 CPU 使用率也會比較高,
注意輸入/輸出(I / O)操作
在本文反復強調了不間斷休眠狀態非常重要 (第一張圖中的D),因為有時你可以在計算機中找到非常高的負載值,然而不同的運行程序使用率相對較低,如果你不考慮這種狀態,你會發現情況莫名其妙,你將不知道如何處理它,當行程等待某個資源的釋放并且其執行不能被中斷時,例如當它等待不可中斷的 I/O 操作時,行程處于此狀態完成(并非所有都是不可中斷的),通常,這種情況是由于磁盤故障,網路檔案系統(如NFS故障)或大量使用非常慢的設備(例如USB 1.0 Pendrive)而發生的,
在這種情況下,我們將不得不使用替代工具,如 iostat 或 iotop,它們將指示哪些行程正在執行更多的 I/O 操作,以便我們可以殺死這些行程或為它們分配較少的優先級(nice命令)能夠為其他更關鍵的行程分配更多的CPU 時間,
一些技巧
系統過載并超過1.0的負載值有時不是問題,因為即使有一些延遲,CPU也會處理佇列中的作業,負載將再次降低到1.0以下的值,但是如果系統的持續負載值大于1,則意味著它無法吸收執行中的所有負載,因此其回應時間將增加,系統將變得緩慢且無回應,高于1的高值,尤其是最后5分鐘和15分鐘的負載平均值是一個明顯的癥狀,要么我們需要改進計算機的硬體,通過限制用戶可以對系統的使用來節省更少的資源,或者除以多個相似節點之間的負載,
因此,我們提出以下建議:
-
>=0.70:沒有任何反應,但有必要監控 CPU 負載,如果在一段時間內保持這種狀態,就必須在事情變得更糟之前進行調查, -
>=1.00:存在問題,您必須找到并修復它,否則系統負載的主要高峰將導致您的應用程式變慢或無回應, -
>=3.00:你的系統變得 非常慢,甚至很難從命令列操作它來試圖找出問題的原因,因此修復問題需要的時間比我們之前采取的行動要長,你冒的風險是系統會更飽和并且肯定會崩潰, -
>=5.00:你可能無法恢復系統,你可以等待奇跡自發降低負載,或者如果你知道發生了什么并且可以負擔得起,你可以在控制臺中啟動kill-9<process_name>之類的命令 ,并祈求它運行在某些時候,以減輕系統負荷并重新獲得其控制權,否則,你肯定別無選擇,只能重新啟動計算機, -
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/288483.html
標籤:其他