大家好,我是痞子衡,是正經搞技術的痞子,今天痞子衡給大家介紹的是在串口波特率識別實體里逐步展示i.MXRT上提升代碼執行性能的十八般武藝,
恩智浦 MCU SE 團隊近期一直在加班加點趕 SBL 專案(解決客戶產品 OTA 需求),這個專案里集成了 ISP 本地升級(UART/USB)功能,其中 UART 口下載升級實作里加入了自動波特率識別支持,具體識別方法見 《串口(UART)自動波特率識別程式設計與實作(中斷)》 一文,這一套 ISP 代碼其實是移植于 i.MXRT Flashloader(更早期的時候叫 KBOOT),
ISP 代碼放在 SBL 工程里會出現高波特率(比如115200)無法識別的問題,但在低波特率的情況下(比如9600,19200),ISP 代碼是功能正常的,說明代碼本身并不存在邏輯缺陷,但高波特率下就例外了,大概率是遇到了代碼執行性能瓶頸,今天痞子衡就嘗試在 i.MXRT 上使用各種方法去提升性能來解決這個高波特率無法識別問題:
一、SBL專案里ISP串口高波特率識別問題
SBL 專案是支持全系列 i.MXRT 平臺的,為了具體化問題,我們就選取 i.MXRT1062 型號為例,官方配套 MIMXRT1060-EVK 板子上搭配了一顆四線串行 NOR Flash(芯成IS25WP064A)用于存放代碼,
SBL 程式主體是 XIP 執行的,區域分涉及 IAP 操作的代碼被分散加載到了 RAM 里,SBL 中 ISP 功能代碼主體當然也是 XIP 為主,且在 SBL 程式里是最先執行的(本地升級超時后才進入 SBL 主體),SBL 工程里跟串口波特率識別相關的源檔案一共如下三個:
microseconds_pit.c -- 存放 PIT 計時函式
autobaud_irq.c -- 存放 GPIO 中斷回呼、波特率識別計算函式
pinmux_utility_imxrt_series.c -- 存放 GPIO 配置與中斷處理函式
MIMXRT1060-EVK 板子上串口是 GPIO1[13:12],其中 RXD - GPIO1[13] 是核心的用于波特率識別的引腳,為了便于直觀地感受代碼執行性能,我們用另一個 GPIO1[12] 來輔助,將其配置為 GPIO 輸出模式,初值為高電平,在 GPIO 中斷處理函式里保持低電平來標示執行總時間:
- Note :下述代碼里中斷處理函式實際上有點小缺陷,《中斷處理函式(IRQHandler)的標準流程》 一文里給出了改進方法,但這里為了觀察中斷處理代碼是否能在下一次中斷來臨前執行完畢特意舍棄了文中 2.2.2 小節里的改進)
void GPIO1_Combined_0_15_IRQHandler(void)
{
// ****輔助除錯:進入中斷時拉低 GPIO1[12],標志執行時間起點
GPIO1->DR &= (uint32_t)~(1U << 12);
uint32_t interrupt_flag = (1U << 13);
// 僅當 GPIO1[13] 下降沿中斷發生時
if ((GPIO_GetPinsInterruptFlags(GPIO1) & interrupt_flag) && s_pin_irq_func)
{
// 執行一次回呼函式
s_pin_irq_func();
// 清除 GPIO1[13] 中斷標志
GPIO_ClearPinsInterruptFlags(GPIO1, interrupt_flag);
__DSB();
}
// ****輔助除錯:退出中斷時拉高 GPIO1[12],標志執行時間結束
GPIO1->DR |= (1U << 12);
}
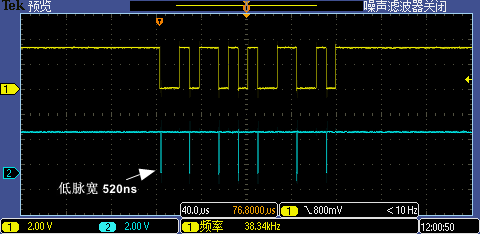
現在我們用示波器同時抓取 GPIO1[13:12] 信號,分別測驗 9600 低波特率(下圖一)和 115200 高波特率(下圖二)下實際波形,根據測量第一次 GPIO 中斷處理執行時間大概是 32.8us(7 次中斷因代碼分支執行不同略有區別),這個時間對于 9600 波特率下單 bit 傳輸耗時約 104us 的情況來說是足夠快的,但是對于 115200 波特率下單 bit 傳輸耗時約 8.68us 的情況來說就顯得有點慢了(最小的下降沿之間間隔是 2bit 傳輸耗時 17.36us ),這也是 115200 無法被識別的原因,因為有 4 個下降沿中斷被漏掉了,
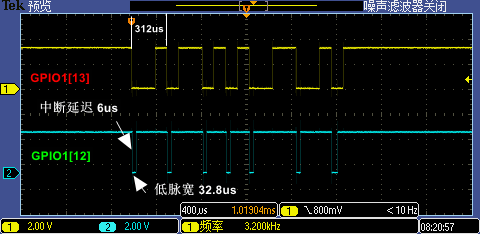
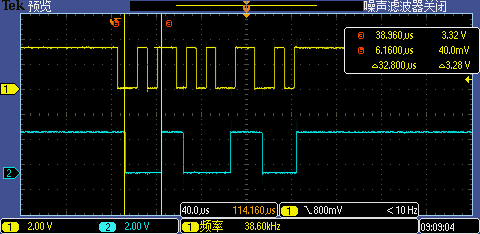
- Note: ISP 功能代碼里配置的系統環境是:396MHz CPU 主頻、不使能 L1 Cache、100MHz Flash 作業頻率,普通 SPI 下 Fast Read Quad I/O SDR Non-Continuous 作業模式,并且使能了 FlexSPI 的 Prefetch 特性(AHB RX Buffer 為 1KB),
二、提升代碼性能的多種方法
既然代碼執行性能不夠,那就努力提升性能,文章標題叫十八般武藝,這只是一種夸張說法,不過痞子衡確實收集了如下六種提升性能的方法,讓我們一一嘗試吧,注意下述結果都是疊加前面方法而得的(所有測驗均是在 115200 波特率下進行),
Level 1:提升CPU主頻
ISP 功能代碼里配置的 CPU 主頻是 396MHz,實際上這是根據 BootROM 默認運行配置而來的,而 i.MXRT1062 是可以跑到 600MHz 主頻的,將 SDK 代碼里 armPllConfig_BOARD_BootClockRUN.loopDivider 由 66 調大到 100 即可,
const clock_arm_pll_config_t armPllConfig_BOARD_BootClockRUN = {
.loopDivider = 100, /* PLL loop divider, Fout = Fin * 50 */
.src = https://www.cnblogs.com/henjay724/p/0, /* Bypass clock source, 0 - OSC 24M, 1 - CLK1_P and CLK1_N */
};
void BOARD_BootClockRUN(void)
{
//...
CLOCK_SetDiv(kCLOCK_AhbDiv, 0);
CLOCK_SetDiv(kCLOCK_ArmDiv, 1);
CLOCK_InitArmPll(&armPllConfig_BOARD_BootClockRUN);
CLOCK_SetMux(kCLOCK_PrePeriphMux, 3);
CLOCK_SetMux(kCLOCK_PeriphMux, 0);
//...
}
CPU 主頻提升后第一次 GPIO 中斷處理執行時間從 32.8us 下降到了 32.2us,性能僅有微小提升,看來此時主要性能瓶頸不在 CPU 主頻上,應該是 Flash 訪問性能在拖后腿,
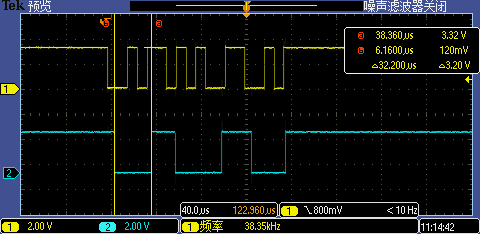
Level 2:提升Flash訪問速度
SBL 工程里啟動頭 FDCB 配置的是 100MHz Flash 作業頻率,但 MIMXRT1060-EVK 板載 Flash(芯成IS25WP064A)最大作業頻率是 133MHz,所以我們可以提升 Flash 作業頻率,修改 qspiflash_config.memConfig.serialClkFreq 為 kFlexSpiSerialClk_133MHz 即可,不了解 FDCB 結構體作業機制的可以翻閱痞子衡舊文 《從頭開始認識i.MXRT啟動頭FDCB里的lookupTable》 ,
const flexspi_nor_config_t qspiflash_config = {
.memConfig =
{
.tag = FLEXSPI_CFG_BLK_TAG,
.version = FLEXSPI_CFG_BLK_VERSION,
.readSampleClkSrc = https://www.cnblogs.com/henjay724/p/kFlexSPIReadSampleClk_LoopbackFromDqsPad,
.csHoldTime = 3u,
.csSetupTime = 3u,
.sflashPadType = kSerialFlash_4Pads,
// .serialClkFreq = kFlexSpiSerialClk_100MHz,
.serialClkFreq = kFlexSpiSerialClk_133MHz,
.sflashA1Size = 8u * 1024u * 1024u,
.lookupTable =
{
FLEXSPI_LUT_SEQ(CMD_SDR, FLEXSPI_1PAD, 0xEB, RADDR_SDR, FLEXSPI_4PAD, 0x18),
FLEXSPI_LUT_SEQ(DUMMY_SDR, FLEXSPI_4PAD, 0x06, READ_SDR, FLEXSPI_4PAD, 0x04),
},
},
.pageSize = 256u,
.sectorSize = 4u * 1024u,
.blockSize = 64u * 1024u,
.isUniformBlockSize = false,
};
Flash 作業頻率提升后第一次 GPIO 中斷處理執行時間從 32.2us 下降到了 27.8us,這次的性能提升算有點明顯了,但是還是不夠,解決不了問題,
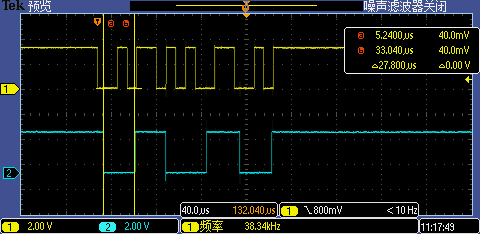
Level 3:配置FlexSPI至最優模式
讓我們繼續從 Flash 傳輸模式上做文章,ISP 功能代碼里配置的是普通 SPI 下 Fast Read Quad I/O SDR Non-Continuous 作業模式,這個模式已經算是非常高效的傳輸模式了,如果還想改進,要么是切換到 QPI 模式(將 CMD 子序列也從一線變到四線)要么是使能 Continuous Read(除了第一個 CMD 子序列,其后 CMD 子序列全部省掉),綜合考慮應該是使能 Continuous Read 性能提升更大一些,具體方法參考 《在i.MXRT啟動頭FDCB里使能串行NOR Flash的Continuous read模式》,
const flexspi_nor_config_t qspiflash_config = {
.memConfig =
{
//...
.lookupTable =
{
FLEXSPI_LUT_SEQ(CMD_SDR, FLEXSPI_1PAD, 0xEB, RADDR_SDR, FLEXSPI_4PAD, 0x18),
// FLEXSPI_LUT_SEQ(DUMMY_SDR, FLEXSPI_4PAD, 0x06, READ_SDR, FLEXSPI_4PAD, 0x04),
// 插入 JUMP_ON_CS 子序列
FLEXSPI_LUT_SEQ(MODE8_SDR, FLEXSPI_4PAD, 0xA0, DUMMY_SDR, FLEXSPI_4PAD, 0x04),
FLEXSPI_LUT_SEQ(READ_SDR, FLEXSPI_4PAD, 0x04, JMP_ON_CS, FLEXSPI_1PAD, 0x01),
},
},
// ...
};
使能 Flash Continuous Read 后第一次 GPIO 中斷處理執行時間從 27.8us 下降到了 27.4us,性能僅有微小提升,這應該跟我們使能了 FlexSPI prefetch 特性有關,1KB AHB RX Buffer 的存在導致 CMD 子序列在總傳輸時序中占比不明顯,不過有點識訓的是漏掉的下降沿中斷從 4 個減少到了 3 個,
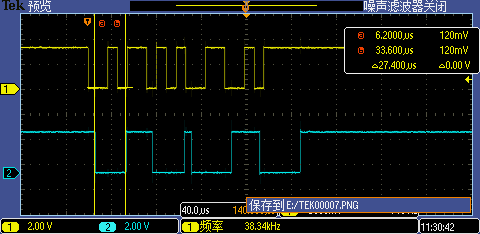
Level 4:打開L1 Cache
對于 XIP 工程來說,不開 L1 I-Cache 加速性能是非常吃虧的一件事,i.MXRT1062 內部有 32KB I-Cache,不把這個 Cache 用起來簡直是暴殄天物,雖然工程 SystemInit() 函式里會執行一次 SCB_EnableICache(),但這只是一個 Cache 總開關,要想 Cache 對 Flash 映射地址(0x60000000 之后)產生作用還得借助 BOARD_ConfigMPU() 函式來具體配置 MPU,關于 Cache 對 Flash 讀取的性能提升見 《實抓Flash信號波形來看i.MXRT的FlexSPI外設下AHB讀訪問情形(全加速)》 ,
int main(void)
{
// 將 MPU 配置提到 ISP 代碼之前
BOARD_ConfigMPU();
#if (defined(COMPONENT_MCU_ISP))
bool isInfiniteIsp = false;
isp_boot_main(isInfiniteIsp);
#endif
// BOARD_ConfigMPU();
// ...
}
使能 Cache 后第一次 GPIO 中斷處理執行時間從 27.4us 下降到了 19us,后面的 GPIO 中斷執行耗時更是大大縮短(原因是中斷處理函式相關代碼在第一次中斷觸發執行時被順便放到 Cache 里了),這時候 115200 高波特率已經能夠被正常識別了,
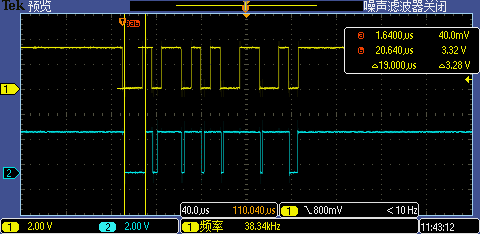
到這里問題已經解決了,但我們還沒有榨干 MCU 最后一滴血,優化繼續,上圖波形里第一次 GPIO 中斷處理執行時間相比其后面的 6 次中斷執行耗時要明顯長,這還是有風險的,比如再高的波特率 256000 還是無法正常識別(至少第一次識別會失敗,后面上位機再重復發暗號做第二次識別就可以了),為了讓第一次 GPIO 中斷處理時間也大大縮短,我們可以在系統初始化的時候故意呼叫一下這些中斷處理相關函式,將這些代碼事先裝載到 I-Cache里,
void autobaud_init(void)
{
s_transitionCount = 0;
s_firstByteTotalTicks = 0;
s_secondByteTotalTicks = 0;
s_lastToggleTicks = 0;
s_ticksBetweenFailure = microseconds_convert_to_ticks(kMaximumTimeBetweenFallingEdges);
enable_autobaud_pin_irq(pin_transition_callback);
// 故意呼叫一下,讓 I-Cache 事先將代碼 Cache 住
GPIO1_Combined_0_15_IRQHandler();
pin_transition_callback(); // 即第一節代碼中的 s_pin_irq_func()
}
將中斷處理函式相關代碼預裝載到 I-Cache 后第一次 GPIO 中斷處理執行時間從 19us 銳降到了 2.12us,跟其他中斷處理執行差不多的耗時,現在即使是 256000 高波特率也能一次識別成功,
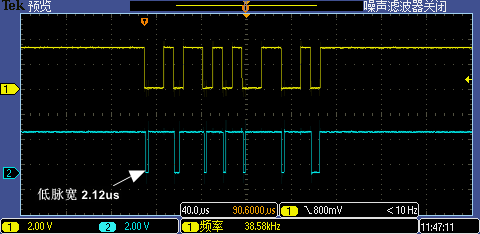
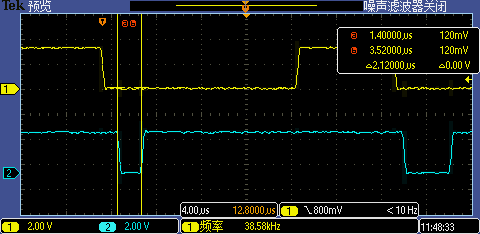
Level 5:拷貝到TCM里
靠 Cache 這種無法精準控制的優化策略始終讓我們無法放心,還是將中斷處理相關代碼直接放到 TCM 里更可靠,我們在工程鏈接檔案(MIMXRT1062xxxxx_flexspi_nor.icf)里做如下修改將第一節里列出了三個源檔案全部弄到 RAM 區里執行(對于 XIP 工程來說,RAM 區是 DTCM, 當然對于代碼來說 ITCM 效率要更高,不過 DTCM 也夠用了),
initialize by copy {
readwrite,
/* Place in RAM flash and performance dependent functions */
object microseconds_pit.o,
object autobaud_irq.o,
object pinmux_utility_imxrt_series.o,
// ...
section .textrw
};
do not initialize { section .noinit };
將中斷處理函式相關代碼重定位到 DTCM 執行后第一次 GPIO 中斷處理執行時間從 2.12us 再降到了 520ns,這下 1M 超高波特率也能被識別了,
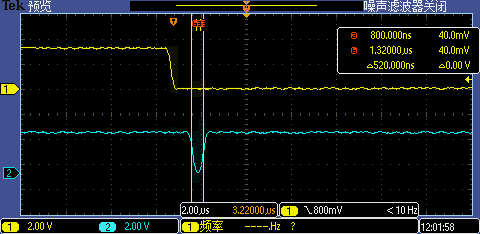
Level 6:指定函式地址以八位元組對齊
性能提升結束了嗎?痞子衡還有一招,參見 《鏈接函式到8位元組對齊地址或可進一步提升i.MXRT1xxx內核執行性能》 一文,將中斷處理相關函式全部鏈接到八位元組對齊地址還可以再利用 Cortex-M7 內核指令雙發射特性,我們查看下工程映射檔案(sbl.map),三個相關函式僅有計時函式 microseconds_get_ticks() 被自動分配到了八位元組對齊的地址,其他兩個函式不是,所以還有提升空間,
Entry Address Size Type Object
;---- ------- ---- ---- ------
GPIO1_Combined_0_15_IRQHandler
0x2000'0b2f 0x3e Code Gb pinmux_utility_imxrt_series.o [1]
pin_transition_callback 0x2000'0175 0x8e Code Gb autobaud_irq.o [1]
microseconds_get_ticks 0x2000'08e9 0x22 Code Gb microseconds_pit.o [1]
將非八位元組地址對齊的中斷處理相關函式調整到八位元組地址對齊后(具體方法這里就不展開介紹了),第一次 GPIO 中斷處理執行時間從 520ns 降到了 480ns,這幾乎是性能極限了,
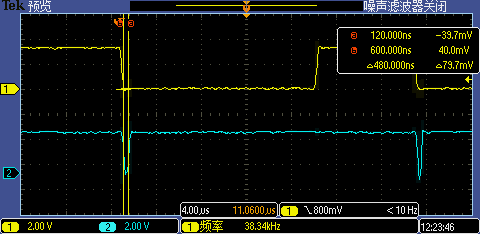
至此,在串口波特率識別實體里逐步展示i.MXRT上提升代碼執行性能的十八般武藝痞子衡便介紹完畢了,掌聲在哪里~~~
歡迎訂閱
文章會同時發布到我的 博客園主頁、CSDN主頁、知乎主頁、微信公眾號 平臺上,
微信搜索"痞子衡嵌入式"或者掃描下面二維碼,就可以在手機上第一時間看了哦,

轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/288926.html
標籤:嵌入式