是否有一種tidyverse的方式來組合同一組的行,替換某些值:
我不想要一個pivot的解決方案!
這是我的資料框架:
df < -結構(list(A = c(1L。 1L, 2L。 3L, 4L。 5L)。 B = c("a"/span>。 "a",
"b", "c"。 "d", "e")。 C = c("u"。 "t"。 "t", "u",。 "t")。 D = c("t",
"u", "u"。 "t",/span> "u"。 "u")。 E = c("t"。 "t", "u", "u"。 "u"。 "u")),
class = "data.frame", 行。 names = c(NA。 -6L))
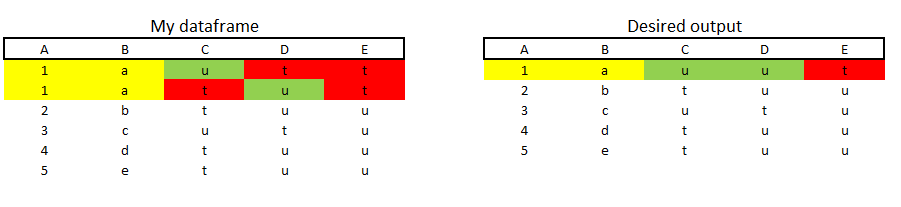
A B C D E
1 1 a u t t
2 1 a t u t
3 2 b t u u
4 3 c u t u
5 4 d t u u
6 5 e t u u
我想要的輸出:
A B C D E
1 1 a u u t
2 2 b t u u
3 3 c u t u
4 4 d t u u
5 5 e t u u
第1行和第2行分別為 "#"和 "#
第1行和第2行有相同的組1和a(列A和B)->
這個組應該是1和a。
這一組應合并為一行 1 a 替換 t 由u在C列至E
所學課程:
。uj5u.com熱心網友回復:
我們可以通過'A'、'B'分組,總結 跨列,排序值,以便'u'將在其他值之前回傳,并選擇第一個元素
library(dplyr)
df %>%。
group_by(A,B) %>%
總結(across(everything),
~ first(.[order(. ! = 'u')])。 . groups = 'drop') 。
輸出
# A tibble: 5 x 5
A B C D E
<int> <chr> < chr> <chr> > <
1 1 a u u t
2 2 b t u u
3 3 c u t u
4 4 d t u u
5 5 e t u u
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/306875.html
標籤: