字串1:
[ impro:0,grp:00, time:0xac, magic:0x00ac] CAR<7:5>|BIKE<4。 0>,original:0x8c,new:0x97。
字串2:
[ impro:0, grp: 00,time:0xbc, magic:0x00bc] CAKE<4:0>, orig:0x0d, new:0x17]
在字串1中,我想提取CAR<7:5和BIKE<4:0,
在字串2中,我想提取CAKE<4:0
在Python中,有任何關于這個的詞條嗎?
uj5u.com熱心網友回復:
你可以使用w <[^>]
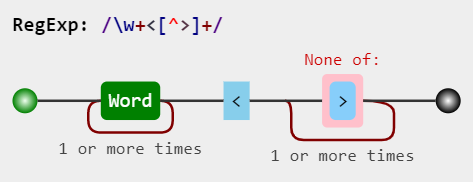
- w 匹配任何單詞字符(相當于[a-zA-Z0-9_])
- 盡可能多地匹配前一個令牌,并根據需要給予回饋(貪婪)。
- <匹配字符< 。
- [^>] 匹配串列中不存在的單個字符 。
- 匹配前一個令牌的次數在1到無限之間,盡可能多的次數,根據需要給予回報(貪婪)
uj5u.com熱心網友回復:
我們可以在這里使用re.findall的模式(w .*?)>:
inp = ["[ impro:0,grp:00,time:0xac,magic:0x00ac] CAR<7: 5>|BIKE<4:0>,orig:0x8c,new:0x97", "[impro:0,grp:00,time:0xbc,magic:0x00bc] CAKE<4:0> , orig:0x0d,new:0x17"]
for i in inp:
matches = re.findall(r'(w <.*?)> ', i)
print( matches)
這個列印:
['CAR<7:5', 'BIKE<4:0']
['CAKE<4:0']
uj5u.com熱心網友回復:
在第一個例子中,BIKE部分沒有前導空格,而是一個管道字符。
更精確一點的匹配可能是斷言左邊的空格或管道,并匹配由冒號分隔的數字,斷言右邊的>。
(?<=[ |]) [A-Z] <d :d (?=>)
在部分內容中,模式匹配:
(?<=[ |])正面看后面,直接在左邊斷言一個空格或一個管道[A-Z]匹配1 字母A-Z<d :d匹配<和:之間的1個以上數字 。
(?=>)正向查找,斷言>直接向右
或者捕獲組的變體:
(?:[ |])([A-Z] <d :d)>
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/307879.html
標籤: