目錄
- 混沌歲月
- 左右橫跳
- 各自為王
- 拆分王權
- 管理的煩惱
- 分配策略
- 一些有趣的方式
- 沒有規矩,不成方圓
- 撥云見日
- 塵埃落地
混沌歲月
開天辟地之初,早期的記憶體并沒有什么復雜的抽象,物理記憶體簡單粗暴,
想要寫什么?給,物理地址給你,隨便搞,這樣的作業系統并沒有擔負起它該有的責任,反而更像一個函式庫,給了你一些系統呼叫之類的函式,開發人員很自由,
過了一段時間,多程式時代來臨,怎么讓這些程式有條不紊地運行,成為了一個必須考慮的問題,例如是給一個程式所有地址空間還是一部分,地址空間如何分配,如果有程式不小心或惡意訪問、修改其他程式該怎么辦?作業系統,起來干活了!
CPU利用了時分共享來應對多程式時代,每個程式跑一段時間,自動讓出CPU,或者時鐘中斷之后CPU切換到作業系統,作業系統來呼叫程式,應用一系列策略來決定下一個時間片誰使用CPU,
問題到了記憶體這里,記憶體又將采用何種策略應對新的時代?
左右橫跳
一種方法是輪到哪個行程就把全部的記憶體都給它,結束之后將所有記憶體,暫存器全部保存到硬碟,然后把記憶體給下一個程式使用,問題在于,磁盤很慢,以前的機械硬碟更慢,
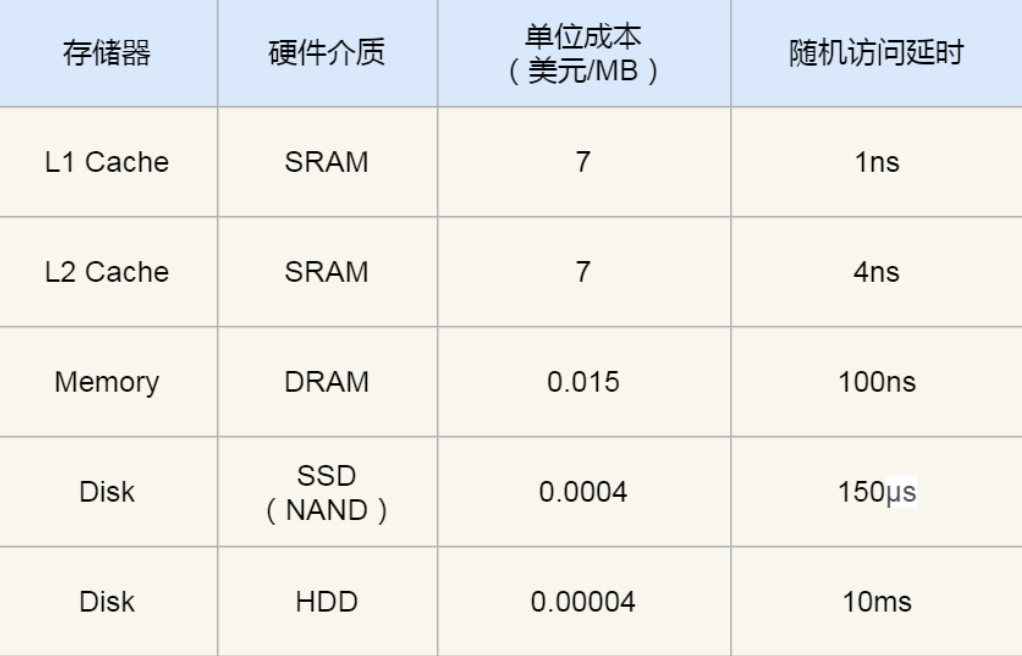
記憶體和機械硬碟差了五個數量級,在記憶體和磁盤之間橫跳太慢了,
各自為王
與上一種方法作對比,很明顯,也可以一個行程只占用部分記憶體,每個行程可以在各自記憶體區間里進行活動,
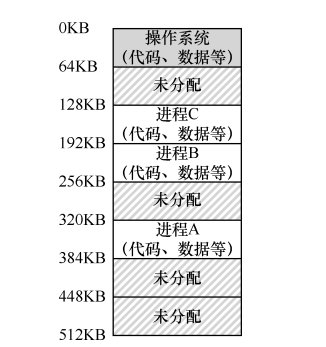
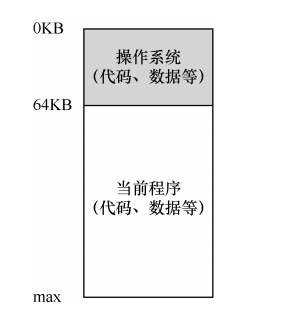
目前,我們的問題就到了程式這里了,不是占用整個記憶體了,而是由作業系統給你分配記憶體區間,那寫程式地址怎么辦?如上圖的行程C,如果C妄圖攻打行程B的地址區間怎么辦?CPU提供了兩個暫存器來解決,基址暫存器和界限暫存器,基址暫存器負責提供行程從哪開始,界限暫存器負責監督行程超界了沒有,超界了由CPU進行對應的處理,一般是直接掛掉它,上圖中,程式只需要當做自己的64KB地址是從0開始的就好,地址轉換由硬體進行,
上面的硬體地址轉換看起來不錯,可是仍舊有個問題:64KB對于有的行程太大了怎么辦?豈不是造成了記憶體浪費,記憶體可是十分昂貴的,經不起浪費啊!
64KB對于現在的行程來說太小了,那是因為現在記憶體相對之前便宜了,我們都被慣壞了,一張圖片都可以幾兆,鼎鼎大名的《超級馬里奧》才40KB,
行程及其地址空間如下:
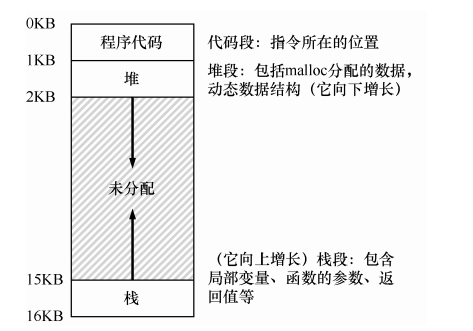
堆和堆疊之間可能存在大量的間隙沒有用到,但是在物理記憶體里卻占用了位置,這種浪費稱為記憶體碎片,所以我們需要更復雜的機制,來更好地利用記憶體,
拆分王權
典型地址空間有三個邏輯不同的段:代碼,堆,堆疊,既然堆、堆疊之間的未分配區域造成了記憶體碎片,那就更細化一點,不是將行程地址整個映射到物理地址,而是將不同的段分別映射到物理地址,當然,MMU(memory management unit)也就需要不止一對基址和界限暫存器,
那么,硬體地址轉換如何知道參考了哪個段呢?可以在虛擬地址里面加兩個標志位來表明;也可以通過地址產生方式來確定段,如是指令獲取,或者堆疊指標,或者其他(堆),
一個分配的例子如下:
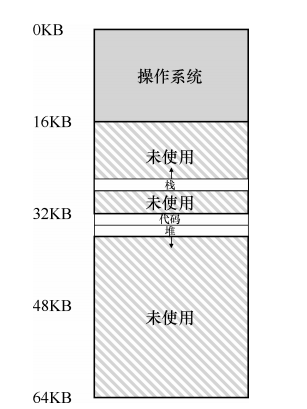
這里面,堆疊的硬體地址轉換有所區別,因為它是反向增長,
為了節省記憶體(任何時候都是有必要的,記憶體在增加,但是應用的記憶體占用也在增加),出現了代碼共享,這也就需要硬體提供保護位,來標識程式是否能都讀寫或者執行,同時不破壞隔離的思想,
作業系統在任務切換時需要負責保存各個暫存器的內容,新的地址空間被創建時,作業系統需要在物理記憶體中為它的段找到空間,碎片問題依然存在,這里稱為外部碎片,
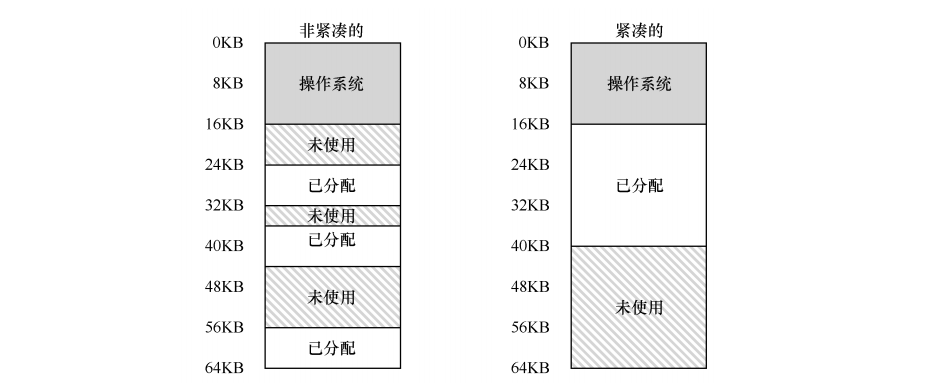
如果要分配一個20KB的段,左圖明明有空間,卻無法分配,
一種方法是:CPU負責整理,將他們的資料復制到連續記憶體區域,改變段暫存器值,如右圖,但是這個操作成本很高,
更簡單的方法就是通過空閑串列管理演算法實作,嘗試保留更大的記憶體塊,具體的演算法很多,但都無法完全消除外部碎片,
管理的煩惱
就像去餐館吃飯,每個四人桌都坐了一個人,來了四個人一起吃飯,一看空位幾十個,但是就是沒有空閑的四人桌,啪的一下心情就不愉悅了,
所以這一節的主題就是如何管理空閑空間,
堆疊是自動管理的,壓進彈出不需要我們操心,我們要關心的是堆,在堆上管理空閑空間的資料結構就是上文提到的空閑串列,
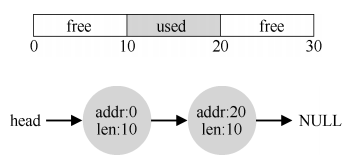
會堆空間的申請釋放都會體現在空閑串列上,當上圖used釋放時,串列會表現為三段空閑的區域,這個時候很自然的一個策略是合并相鄰空閑塊,記住,我們的總體目標是要有盡可能大的連續空閑區域,
分配策略
記憶體的分配釋放是任意的,記憶體可能會被搞得稀碎,理想的分配程式應該保證快速和碎片最小化,一個記憶體分配請求來了,該如何分配記憶體?
- 最優分配:遍歷整個空閑鏈表,找到符合要求的地址區間最小的,避免了空間浪費,但是性能差,
- 首次匹配:遍歷,找到了符合條件的地址區間就結束,空閑串列開頭會被分裂成很多小塊,
- 下次匹配:比首次匹配多維護一個指標,指向上一次查找結束的位置,就是為了避免首次匹配空閑串列開頭頻繁分割的問題,
一些有趣的方式
-
分離空閑串列
對于應用程式頻繁申請的一種或幾種大小的記憶體空間,用一個獨立的串列來管理,其他的給通用記憶體分配程式,
-
伙伴系統
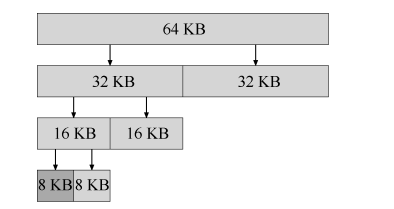
這個是為了合并空閑記憶體更加簡單,思路就是將空閑空間一分為二,直到找到小的不能再小的地址區間,回傳給用戶,合并的時候只要查看相鄰區間,就可以直到是否可以合并,
沒有規矩,不成方圓
分段將空間切成不同大小的分片之后,空間會碎片化,再想合回來就難了,一種對應的解決方法是將空間分割成固定長度的分片,稱為分頁,

作業系統為每個行程保存一個資料結構,來記錄地址空間虛擬頁在物理記憶體的位置,稱為頁表,主要用來進行地址轉換,
上圖的例子中,地址空間為64位元組,所以虛擬地址需要6位,頁大小為16位元組,所以頁面號要兩位,偏移量4位,
進行地址轉換的時候就根據頁面號和偏移量查找頁表項,找到期望的物理幀號(PFN),
如x86頁表項如下:

20位的物理幀號,4KB的頁面,正好32位,頁表項后面幾位則是標志位,如讀寫為R/W,訪問位A等,
頁表放在哪里?當然是放在記憶體里,那樣每一個記憶體參考都要執行一個額外的記憶體參考來從頁表獲取地址轉換,時間翻倍!而且頁表記憶體占用很大,算一筆賬,以上面的x86為例,一個頁表項32位,4個位元組,一個頁幀4KB,那樣就有2的20次方個頁幀,一個頁幀對應一個頁表項,也就是2的24次方位元組,就是4MB,系統后臺可能有上百個行程,光是頁表就占了400MB以上,這河貍嗎?

問題擺在這,后面討論如何解決,
撥云見日
使用分頁作為核心機制來實作虛擬記憶體,性能開銷較大,那如何加速地址轉換呢?
軟體上想不通的,就要由硬體來提供幫助,而且很多時候硬體的一些略微的改變,會帶來巨大的性能提升,這里就是要增加地址轉換旁路緩沖存盤器(translation-lookaside buffer, TLB),或者稱為地址轉換快取,還記的上面的訪問速度圖嗎,cache超快的,每次記憶體訪問,先看一下TLB,如果有就很快完成轉換,不再訪問頁表,沒有就需要去查頁表了,redis和傳統資料庫的組合不就是很像這個做法嗎?
初學編程的時候,老師告訴你,記憶體最好是連續訪問,例如二維陣列,你應該a[0][0],a[0][1],a[0][2]這樣遍歷,而不是a[0][0],a[1][0],a[2][0]這樣去遍歷,現在你知道原因了嗎?就是和地址轉換快取的命中率有關,
典型的TLB有32項、64項或者128項,硬體會并行查找期望的轉換映射,
同樣,頁表,TLB都只是對一個行程有效,背景關系切換時會進行切換,一種方法是簡單清空TLB,如有效位置0,如果作業系統頻繁切換行程,這種每次行程運行都會觸發TLB未命中,
或者增加硬體支持,增加行程識別符號,這樣就不用了清零了,那新快取來了,替換哪一個呢?
一種常見的策略是替換最少使用的項(LRU),另一種典型策略就是隨機替換,來防止極端情況,
速度問題有了解決辦法,那空間問題呢?4MB的問題還是存在啊!
之前我們默認說的都是線性頁表,一種方法是采用更大的頁,很明顯,頁更大了,頁表里面的項就更少了,記憶體占用也就少了,但是頁太大會造成內部碎片,空間浪費,
古語有言:取其精華去其糟粕,結合分頁和分段機制也是一種方法,這種方法就是拋去了堆和堆疊之間的空閑區域,不再映射物理記憶體,也沒有頁表,來節省空間,
資料結構的強大之處來了,線性串列解決不了,換個結構試試,出現了多級頁表,類似樹的結構,
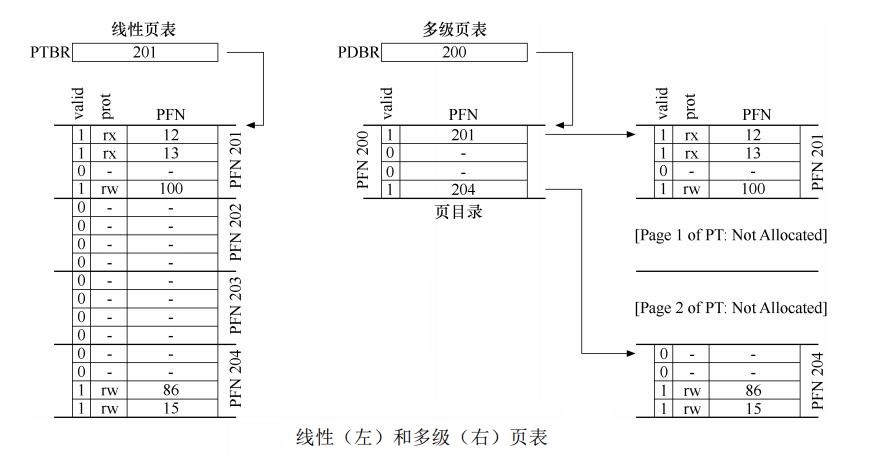
多級頁表增加了頁目錄的概念,用來標記一個頁是否是無效頁,無效就沒有頁表項,成本就是TLB未命中時需要從記憶體加載兩次,一次頁目錄,一次PTE,
頁目錄還是太大怎么辦?再加一層頁目錄,,,
更極端一點,有反向頁表,他就是一個頁表記錄所有行程的地址映射,無效的不記錄,頁表項里標識哪個行程或哪些行程在用這個地址映射,線性查找自然不現實,這種做法的查找應該是建立散串列來加速查找,
之前說過一句:頁表放在哪?當然是記憶體,這句話也不絕對,對于大部分記憶體都不絕對,記憶體不夠用時,作業系統會將一部分不常用的記憶體放入磁盤,稱為交換空間,
塵埃落地
至此,虛擬記憶體的大致脈絡已經清晰,它是軟硬體,資料結構,演算法的結合,是空間和時間的權衡,
本文同步發布于orzlinux.cn
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/308092.html
標籤:其他
上一篇:bash是什么?