我只是在 for 內部執行 for 使用以下代碼從不同的 csv 檔案讀取到 R 中的元素串列,我是從兩個不同的變數中獲取的,頻率型別freq <- c('4', '8', '13', '38','N_4','N_8','N_13','N_38')和值型別typ <- c('PE','QS')。這兩個字串變數用于在相應的 csv 中命名,如圖所示。
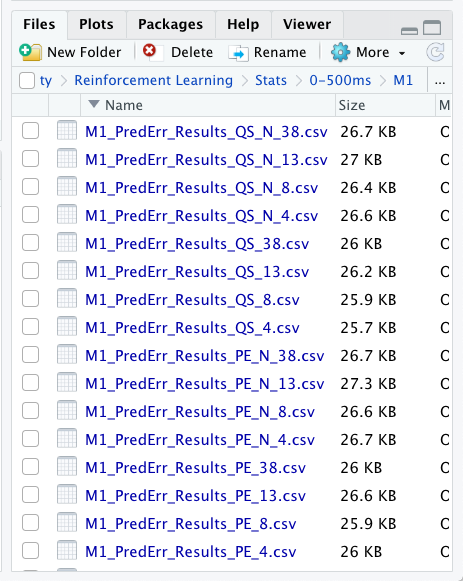
我正在使用以下代碼從同一目錄中讀取。
#Prepare data options
freq <- c('4', '8', '13', '38','N_4','N_8','N_13','N_38')
typ <- c('PE','QS')
dataintra <- list()
for (j in 1:2){
for (k in 1:8){
dataintra[[j*k]] <- read.csv(sprintf('M1_PredErr_Results_%s_%s.csv', typ[j], freq[k]), sep=',', header=TRUE)
}
}
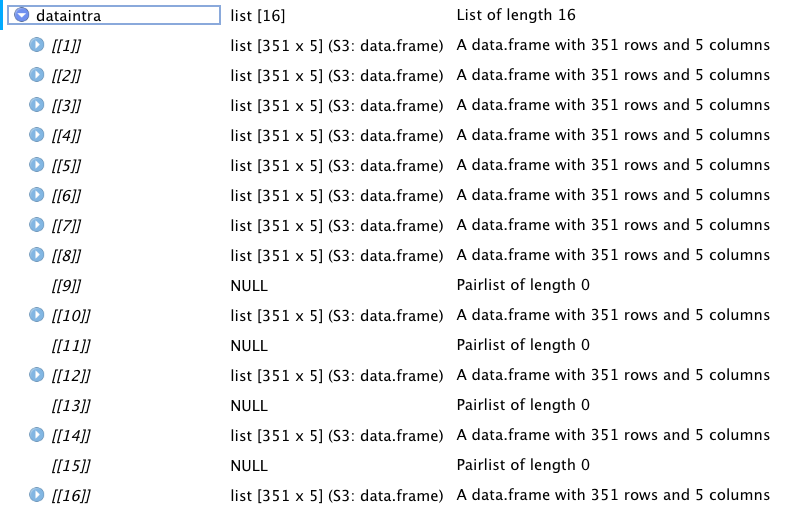
問題是雖然我期待完整串列的串列,但我發現不同的串列編號為 NULL,如下面的螢屏截圖所示。
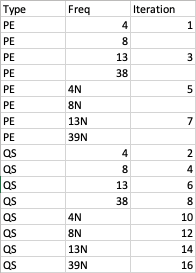
試圖理解迭代背后的邏輯,for-for 以奇數與偶數相比以一種奇怪的方式跳躍,這使得從 9 到 15 的賠率無法完成。我正在附加串列中每個元素的迭代順序。
我想了解為什么 for-for 中的 R 有這種不穩定的行為,以及這樣做的正確方法是什么。我可以考慮其他效率較低的方法,例如制作一個帶有兩個特征的索引向量iteration <- c('PE_4', 'PE_8', 'PE_13', 'PE_38','PE_N_4','PE_N_8','PE_N_13','PE_N_38','QS_4', 'QS_8', 'QS_13', 'QS_38','QS_N_4','QS_N_8','QS_N_13','QS_N_38'),但如果有人可以提供幫助,我真的很想了解邏輯。
提前致謝!
uj5u.com熱心網友回復:
#Prepare data options
freq <- c('4', '8', '13', '38','N_4','N_8','N_13','N_38')
typ <- c('PE','QS')
我建議使用命名串列(我們可以使用檔案名作為標識)
dataintra <- list()
for (this_freq in freq){
for (this_typ in typ){
this_name <- sprintf('M1_PredErr_Results_%s_%s.csv', this_typ, this_freq)
dataintra[[this_name]] <- read.csv(this_name, sep=',', header=TRUE)
}
}
或者,如果您更喜歡數字索引:
index <- 1
for (this_freq in freq){
for (this_typ in typ){
this_name <- sprintf('M1_PredErr_Results_%s_%s.csv', this_typ, this_freq)
dataintra[[index]] <- read.csv(this_name, sep=',', header=TRUE)
index <- index 1
}
}
uj5u.com熱心網友回復:
您的問題在于 List 元素的索引:
dataintra[[j*k]]
例如 9 只能由 3x3 組成,因此永遠不會填充串列的索引 9。因為你只是乘以 (1:2)x(1:8)
您還可以覆寫多個索引,例如索引 8 是 (1,8) 和 (4,2)。
我認為使用 R 已經提供的一些函式會更容易,而不是使用 for 回圈:
#Prepare data options
freq <- c('4', '8', '13', '38','N_4','N_8','N_13','N_38')
typ <- c('PE','QS')
# get all combinations of typ and freq
input<- expand.grid(typ,freq)
## get a List of all the adresses
# mapply iterates over two vectors (Var1 and Var2 of the input dataframe)
# and performs a function on them
csv_adresses <- mapply(function(x,y){sprintf('M1_PredErr_Results_%s_%s.csv',x,y)},
input$Var1,input$Var2)
# read all the csv files of the adresses
dataintra <- sapply(csv_adresses,read.csv,header=TRUE)
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/311491.html
上一篇:如何在python中對包含相同id的字典進行重復資料洗掉
下一篇:將字典值與串列進行比較并回傳鍵