要求只使用regex來搜刮評級鏈接,并且總共有250個評級鏈接,然后將其保存到txt檔案。
網站。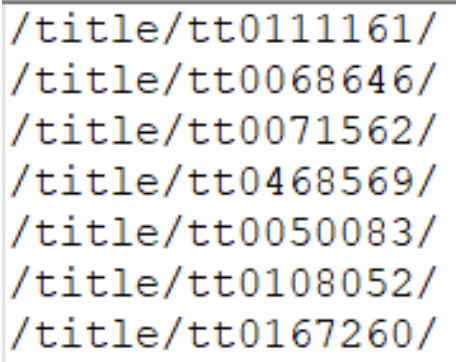 在最后應該看起來像這樣
在最后應該看起來像這樣
我之前嘗試過使用beautifulsoup4,但當時要求只使用正則運算式來提取,所以我不確定。我是否要使用re.findall來尋找所有的鏈接?
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = 'https://www.imdb.com/chart/top'/span>
html = urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
count = 0
all_urls = list()
for tdtag in soup.find_all(class_ = "titleColumn") 。
url = tdtag.a['href']
all_urls.append(url)
count = 1 1
print('total of {} urls'.format(count) >)
data = np.array(all_urls)
print(data)
np.savetxt('urls.txt', data, fmt = '%s', encoding = 'utf-8')
uj5u.com熱心網友回復:
這是我在這方面的笨拙嘗試:
from re import compile
from requests import get
BASE = 'https://www.imdb.com/chart/top'/span>
page = get(BASE)
pattern = compile(r'<a href="/title/([a-z0-9] )/')
URLs = pattern.findall(page.text)
try:
f = open('urls.txt'/span>, 'x'/span>, encoding='utf-8'/span>)
except FileExistsError as e:
print(e)
else:
for i in set(URLs)。
f.write(f'/title/{i}/
')
f.close()
。requests.get(URL)是一個回應物件。所以,你需要requests.get(URL).text來讓regex對它起作用https://regex101.com/是一個方便的網站,你可以用它來建立和測驗regex
。try,except,else可以用來處理如果url.txt檔案已經存在的錯誤f-strings是超級方便的,我強烈建議你學習和使用它們
。
uj5u.com熱心網友回復:
使用re.findall:
替換:
all_urls = list()
for tdtag in soup.find_all(class_ = "titleColumn") 。
url = tdtag.a['href']
all_urls.append(url)
count = 1 通過:
import re
text = html.read().decode('utf-8')
all_urls = list(set(re.findall(r'/title/ttd '/span>, text))
count = len(all_urls)
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/319526.html
標籤: