代碼
from __future__ import uniticode_literals
import youtube_dl
import pandas as pd
import csv
import re
# 讀取csv檔案 匯入 re
number_of_rows = pd.read_csv('single.csv')
# Initialize YouTube-DL Array
ydl_opts = {}
all_scrapes = []
twitter_list = []
# Scrape在線產品
def run_scraper() 。
# 讀取CSV到串列。
with open("single.csv"/span>, "r"/span>) as f:
csv_reader = csv.reader(f)
next(csv_reader)
# Scrape Data From Store[/span]。
for csv_line_entry in csv_reader:
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
meta = ydl.extract_info(csv_line_entry[0], download=False)
channel = meta['channel']
title = meta['title']
description = meta['description']
print('Channel :'/span>, channel)
print('Title :', title)
#print('description :', description)/span>
get_links(description)
print("-"/span> * 120)
print()
print('Demo:'/span>, twitter_list)
# Make a tuple with the relevant information of the current YouTube Scrapes.
current_scrapes = (channel, title, twitter_list)
all_scrapes.append(current_scrapes)
print('All Scrapes:'/span>, all_scrapes)
print()
def get_links(description)。
# 查找描述中的URLs。
description_urls = re.findall(r'(https?://[^s] )'/span>, description)
#print('List Before :', description_urls, '
')
# Twitter資源。
if 'twitter.com' in description。
for item in description_urls:
#print('Print All URLs:', item)。
if 'twitter.com' in item:
print('- Twitter URL Found:'/span>, item)
twitter_list.append(item)
run_scraper()
CSV檔案
Videos
https://www.youtube.com/watch?v=kqtD5dpn9C8
https://www.youtube.com/watch?v=rfscVS0vtbw
上面的代碼從CSV檔案中提取YouTube的URL,然后列印頻道和標題資訊。 此外,通過get_links函式,它從YouTube描述中提取了Twitter的URL。
問題
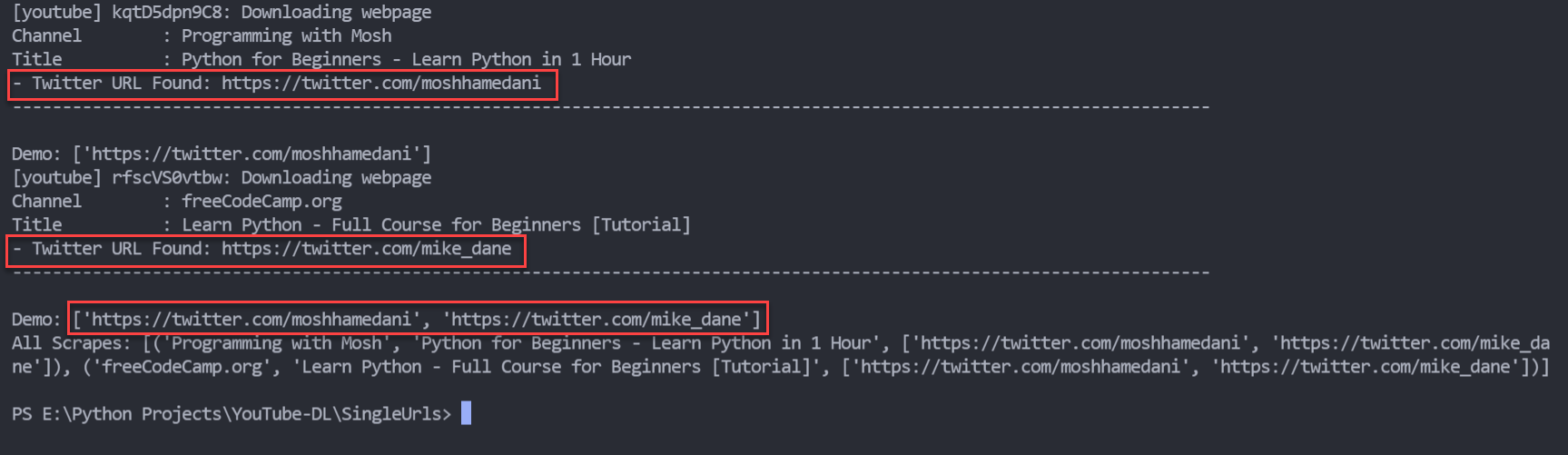
當我在get_links函式(第61行)中列印捕獲的Twitter Url時
print('- Twitter URL Found:'/span>, item)
結果是正確顯示了每個用戶各自的Twitter條目。
我無法將這些資訊拉入Tuple current_scrapes,而無法看到所有捕獲的Twitter Urls填充到每個tuple條目中。
如果有任何幫助,我們將不勝感激。
uj5u.com熱心網友回復:
通過一點點重組你的代碼:
import re
import youtube_dl
import pandas as pd
# Scrape Online Product as pd
def run_scraper():
ydl_opts = {}
all_scrapes = []
# Read CSV to List: ydl_opts = {} all_scrapes = [].
with open("single.csv"/span>, "r"/span>) as f:
csv_reader = csv.reader(f)
next(csv_reader)
# Scrape Data From Store[/span]。
for csv_line_entry in csv_reader:
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
meta = ydl.extract_info(csv_line_entry[0], download=False)
channel = meta["channel"]
title = meta["標題"]
description = meta["描述"]
twitter_list = get_links(description, "twitter.com")
print("Channel :"/span>, channel)
print("Title :", title)
print("Twitter URLs :"/span>, twitter_list)
print("-" * 120)
print()
all_scrapes.append((channel, title, twitter_list))
return all_scrapes
def get_links(description, link)。
out = []
# Find URLs in description: out = []
description_urls = re.findall(r"(https?://[^s] )"/span>, description)
for item in description_urls:
if link in item:
out.append(item)
return out
df = pd.DataFrame(run_scraper(), columns=["channel"/span>, "title"/span>, "twitter URLs"/span>] )
print(df)
列印:
[youtube] kqtD5dpn9C8: 正在下載網頁
頻道:與莫什編程
標題 : Python初學者--1小時內學會Python
Twitter URLs : ['https://twitter.com/moshhamedani']
------------------------------------------------------------------------------------------------------------------------
[youtube] rfscVS0vtbw: 下載網頁
頻道 : freeCodeCamp.org
標題 : 學習Python - 初學者的完整課程 [教程] 。
Twitter URLs : ['https://twitter.com/mike_dane']
------------------------------------------------------------------------------------------------------------------------
頻道標題 twitter URLs
0 用Mosh Python初學者編程--1小時內學會Python [https://twitter.com/moshhamedani]
1 freeCodeCamp.org學習Python--初學者的全部課程[教程] [https://twitter.com/mike_dane]
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/320270.html
標籤: