我試圖從這個網站的超鏈接中提取 URL: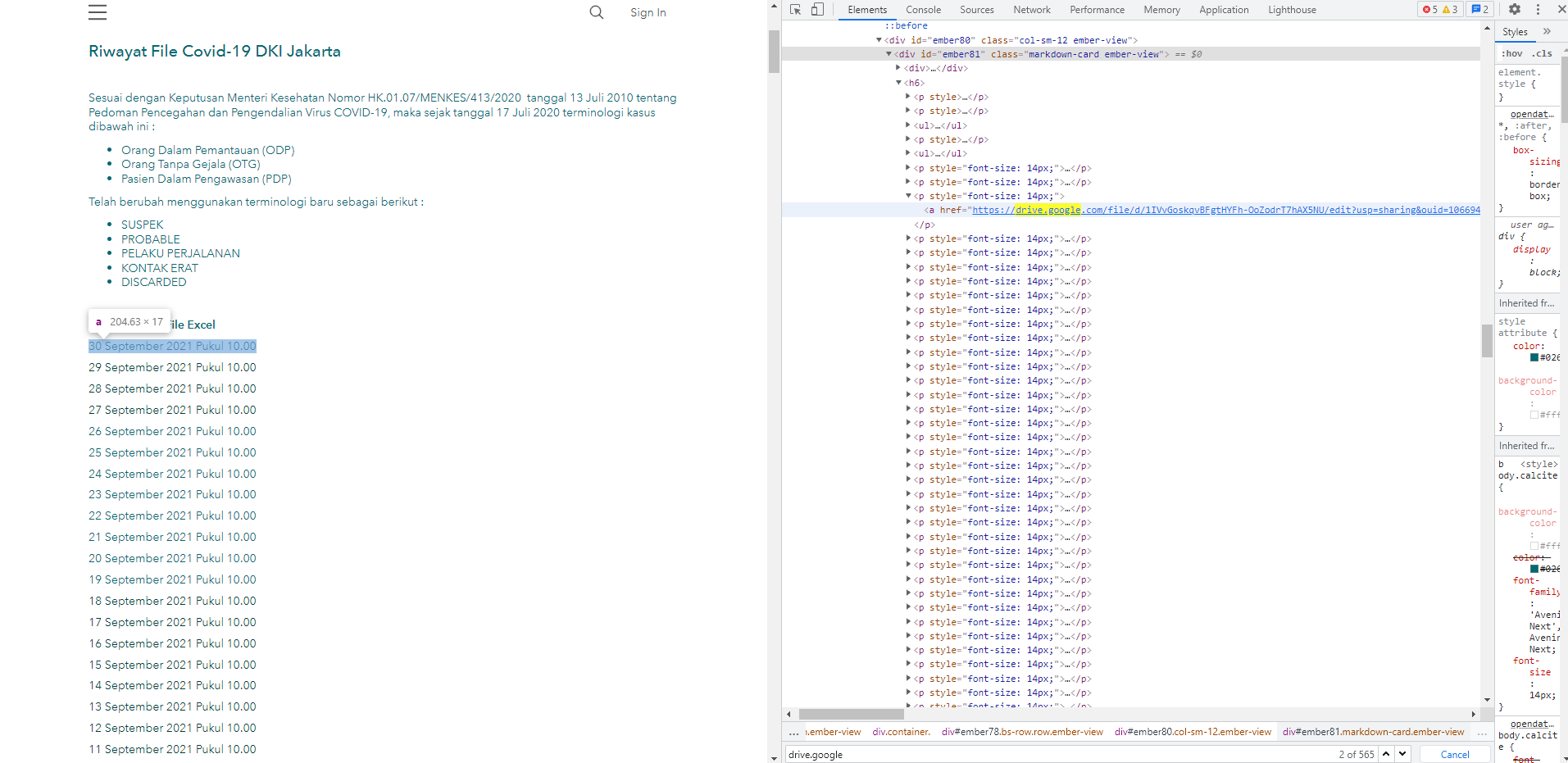
uj5u.com熱心網友回復:
您無法決議它,因為資料是動態加載的。如下圖所示,當您下載 HTML 源代碼時,寫入頁面的 HTML 資料實際上并不存在。JavaScript 稍后會決議window.__SITE變數并從中提取資料:

但是,我們可以在 Python 中復制它。下載頁面后:
import requests
url = "https://riwayat-file-covid-19-dki-jakarta-jakartagis.hub.arcgis.com/"
req = requests.get(url)
您可以使用re(regex) 來提取編碼的頁面源:
import re
encoded_data = re.search("window\.__SITE=\"(.*)\"", req.text).groups()[0]
之后,您可以使用urllibURL 解碼文本,并json決議 JSON 字串資料:
from urllib.parse import unquote
from json import loads
json_data = loads(unquote(encoded_data))
然后,您可以決議 JSON 樹以獲取 HTML 源資料:
html_src = json_data["site"]["data"]["values"]["layout"]["sections"][1]["rows"][0]["cards"][0]["component"]["settings"]["markdown"]
此時,您可以使用自己的代碼來決議 HTML:
soup = BeautifulSoup(html_src, 'html.parser')
print(soup.prettify())
links = soup.find_all('a')
for link in links:
if "href" in link.attrs:
print(str(link.attrs['href']) "\n")
如果你把它們放在一起,這是最終的腳本:
import requests
import re
from urllib.parse import unquote
from json import loads
from bs4 import BeautifulSoup
# Download URL
url = "https://riwayat-file-covid-19-dki-jakarta-jakartagis.hub.arcgis.com/"
req = requests.get(url)
# Get encoded JSON from HTML source
encoded_data = re.search("window\.__SITE=\"(.*)\"", req.text).groups()[0]
# Decode and load as dictionary
json_data = loads(unquote(encoded_data))
# Get the HTML source code for the links
html_src = json_data["site"]["data"]["values"]["layout"]["sections"][1]["rows"][0]["cards"][0]["component"]["settings"]["markdown"]
# Parse it using BeautifulSoup
soup = BeautifulSoup(html_src, 'html.parser')
print(soup.prettify())
# Get links
links = soup.find_all('a')
# For each link...
for link in links:
if "href" in link.attrs:
print(str(link.attrs['href']) "\n")
uj5u.com熱心網友回復:
鏈接是由 javascript 代碼動態生成的,資料可以在下面的結構中找到。
<script id="site-injection">
window.__SITE="your data is here"
</script>
所以你需要抓取這個script元素并決議它的值window.__SITE
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/323620.html
上一篇:如何自動下載網頁以供離線查看?
下一篇:從URL匯入資料時單列中的NaN