一天的好時光。
uj5u.com熱心網友回復:
我不推薦迭代,但是每一個連續的計算都依賴于前一個計算的結果,這使得向量復雜化。
您可以使用 apply,這在某種程度上是在您的行上回圈,或者您可以明確地在您的行上回圈,并使用 .loc 進行計算。
考慮一下你的DF的前4行:
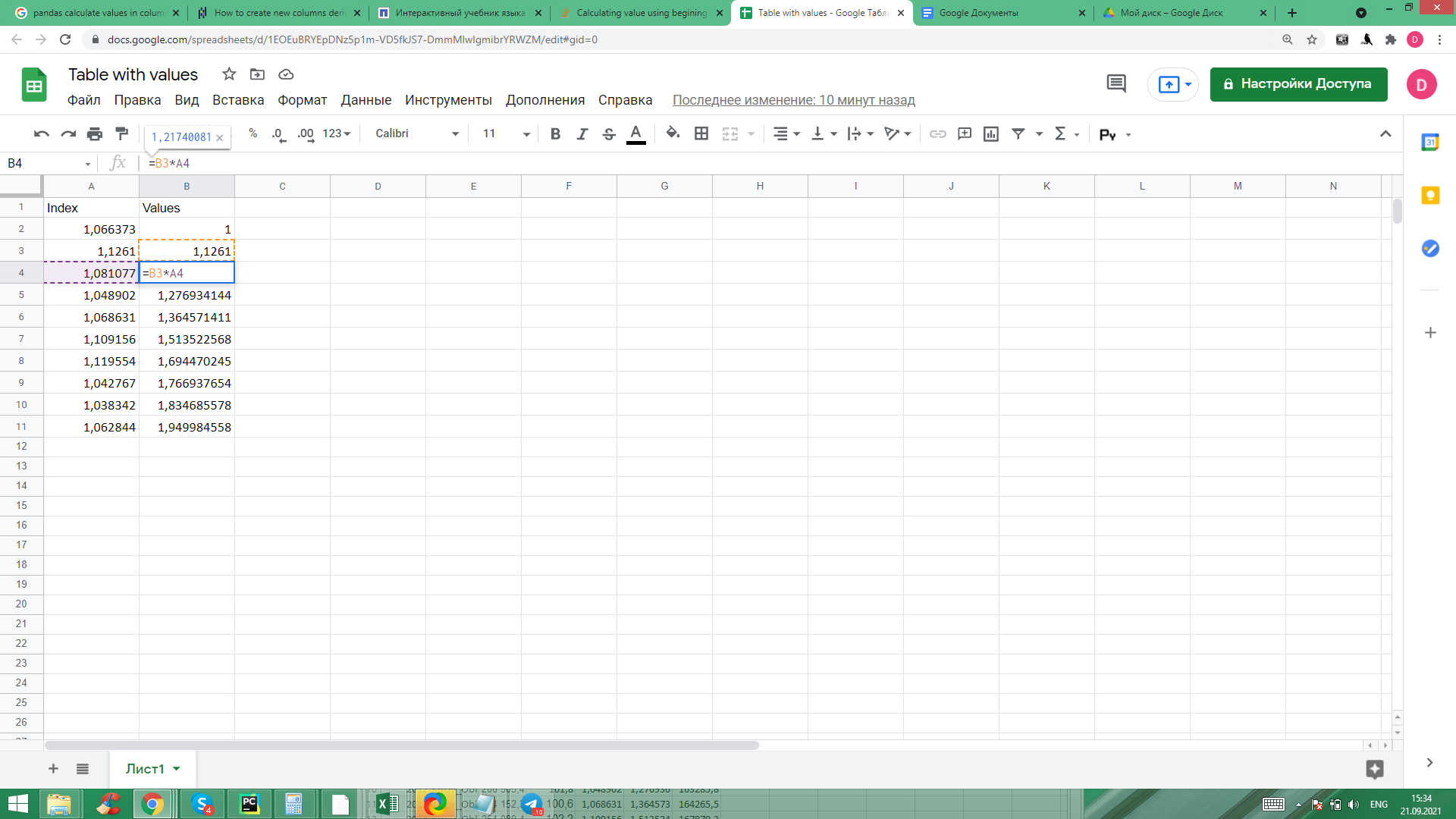
>>> df
索引值
0 1.066373 1.0
1 1.126100 NaN
2 1.081077 NaN
3 1.048902 NaN
4 1.068631 NaN
for i in range(1, len(df))。
df.loc[i, 'Values'] = df.loc[i-1, 'Values'] 。* df.loc[i, 'Index']
將你的DF中的Values列更新為:
索引值
0 1.066373 1.000000
1 1.126100 1.126100[/span]。
2 1.081077 1.217401[/span]。
3 1.048902 1.276934[/span]。
4 1.068631 1.364571[/span
一些評論:
- 確保你的 "索引 "列是一個列,而不是你的索引。
range(1,...)確保你的loop從index1開始,而不是0。- 我認為如果你的
DF很大的話,這將會很慢 。
uj5u.com熱心網友回復:
你可以在Index值上使用cumprod(累積乘積)方法,在用1替換第一個值之后:
import pandas as pd
df = pd.DataFrame({'Index': [1.066373, 1. 126100, 1.081077, 1.048902, 1.068631]})
df['Values'] = df.Index
df.Values[0] = 1.
df.Values = df.Values.cumprod()
df
索引值
0 1.066373 1.000000[/span
1 1.126100 1.126100[/span]。
2 1.081077 1.217401[/span]。
3 1.048902 1.276934[/span]。
4 1.068631 1.364571[/span
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/326388.html
標籤: