有人知道我如何使用 Power Query 根據上一個日期時間讀數和當前日期時間讀數之間的差距對傳感器事件進行分組嗎?抱歉,我不知道如何表達這個問題,這可能就是為什么我對谷歌不走運的原因。
我想要做的是根據當前讀數和上一個讀數之間的差距,按開始和結束日期時間對一些資料進行分組。
如果您考慮以下資料:
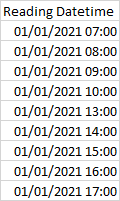
像這樣分組很容易:

但這實際上是兩個離散事件,而不是一個 - 如果您注意到 10:00 和 13:00 之間的間隔,我假設這些事件需要在兩個小時內彼此分組,例如:

編輯 - 所以,要清楚的是,如果閱讀發生在最后一次之后兩個多小時,那么它可以被視為一個新事件。
在 Power Query 中是否可能有一個有效的解決方案?正如您可能想象的那樣,當涉及到日期時間讀數和傳感器時,有大量的資料。
我可以并且愿意(并且確實)撰寫代碼來在其他情況下執行此操作,但是此報告已經通過 Power Query 按最小和最大日期時間進行分組,因此如果我可以添加額外的時間削減,作業量會少得多 -關閉組邏輯。
謝謝你的幫助!
菲爾。
編輯 - 我已經看到了一個解決方案,你添加一個索引并減去日期來為日期(不是日期時間)創建島嶼組,但我不認為(雖然我可能是錯的)這會在這里作業,因為讀數不不是完全固定的時間間隔(它們可能是每 1 小時 2 分鐘或每 58 分鐘等)。
uj5u.com熱心網友回復:
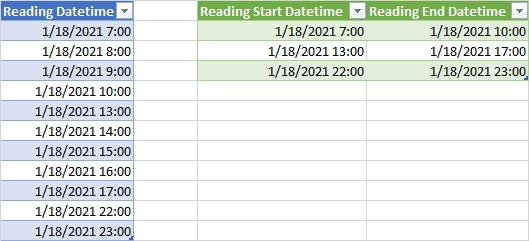
看看這是否有幫助。是的,我正在使用索引創建島嶼群
將每行上方的行合并到相鄰列中
取兩列之間的持續時間
添加索引
如果持續時間> 2,則放入索引
填寫
按索引分組并取最小值/最大值
let Source = Excel.CurrentWorkbook(){[Name="Table1"]}[Content],
// stolen from Imke Feldman via Ron Rosenfeld, great way to combine list next to itself, offset
shiftedList = {null} & List.RemoveLastN(Source[Reading Datetime],1),
custom1 = Table.ToColumns(Source) & {shiftedList},
custom2 = Table.FromColumns(custom1,Table.ColumnNames(Source) & {"Previous Row"}),
#"Added Index" = Table.AddIndexColumn(custom2, "Index", 0, 1),
// copy over index when duration > 2 hours between columns
#"Added Custom" = Table.AddColumn(#"Added Index", "Custom", each if [Previous Row]=null then [Index] else if Number.From([Reading Datetime]-[Previous Row])*24 >2 then [Index] else null),
#"Filled Down" = Table.FillDown(#"Added Custom",{"Custom"}),
#"Grouped Rows" = Table.Group(#"Filled Down", {"Custom"}, {{"Reading Start Datetime", each List.Min([Reading Datetime]), type datetime}, {"Reading End Datetime", each List.Max([Reading Datetime]), type datetime}}),
#"Removed Columns" = Table.RemoveColumns(#"Grouped Rows",{"Custom"})
in #"Removed Columns"
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/328287.html
下一篇:PySpark-創建新鑰匙