我有一個PySpark資料框架,我想獲得ORDERED_TIME的第二高值(DateTime Field yyyy-mm-dd格式),在應用于2列的groupBy之后,即CUSTOMER_ID和ADDRESS_ID。
一個客戶可以有許多與地址相關的訂單,我想獲得(customer,address)對的第二個最新的訂單
我的方法是做一個視窗,根據CUSTOMER_ID和ADDRESS_ID進行磁區,按ORDERED_TIME進行排序。
sorted_order_times = Window. partitionBy("CUSTOMER_ID", "ADDRESS_ID").orderBy(col('ORDERED_TIME') 。
df2 = df2.withColumn("second_recent_order", (df2.select("ORDERED_TIME").collect()[1]).over(sorted_order_times))
但是,我得到一個錯誤,說ValueError: 'over' is not in list
誰能建議一下解決這個問題的正確方法?
如果需要任何其他資訊,請讓我知道
。示例資料
----------- ---------- -------------------
|customer_id|address_id| ordered_time|
----------- ---------- -------------------
| 100| 158932441|2021-01-02 13: 35: 57|
| 100| 158932441|2021-01-14 19: 14:08|
100| 158932441|2021-01-03 13: 33: 52|
| 100| 158932441|2021-01-04 09:36:10|
| 101| 281838494|2020-05-07 13: 35: 57|
| 101| 281838494|2021-04-14 19: 14:08|
----------- ---------- -------------------
預期輸出
----------- ---------- ------------------- -------------------
|CUSTOMER_ID|ADDRESS_ID|ORDERED_TIME|second_recent_order
----------- ---------- ------------------- -------------------
| 100| 158932441| 2021-01-02 13: 35:57|2021-01-04 09:36:10.
| 100| 158932441| 2021-01-14 19: 14:08|2021-01-04 09:36:10.
| 100| 158932441|2021-01-03 13: 33:52|2021-01-04 09:36:10.
| 100| 158932441| 2021-01-04 09:36: 10|2021-01-04 09:36: 10
|101|281838494|2020-05-07 13:35: 57|202005-07 13:35:57
|101|281838494|2021-04-14 19: 14:08|2020-05-07 13:35:57.
----------- ---------- ------------------- -------------------
uj5u.com熱心網友回復:
一個解決方案是創建一個查找表,其中包含CUSTOMER_ID和ADDRESS_ID的所有夫婦的第二最近的訂單,然后將其與原始資料框架連接起來。
我假設你的ORDERED_TIME列已經是一個timestamp型別。
import pyspark.sql.function as F
from pyspark.sql.window import Window
# define window[/span
w = Window().partitionBy('CUSTOMER_ID', 'ADDRESS_ID') .orderBy(F.desc('ORDERED_TIME')
# 創建查找表。
second_highest = df
.withColumn('rank', F.dense_rank() .over(w))
.filter(F.col('rank') == 2)
.select('CUSTOMER_ID'/span>, 'ADDRESS_ID'/span>, 'ORDERED_TIME'/span>)
# join with original dataframe[/span]。
df = df.join(second_highest, on=['CUSTOMER_ID'/span>, 'ADDRESS_ID'/span>], how='left'/span>)
df.show()
----------- ---------- ------------------- -------------------
|customer_id|address_id| ordered_time| ordered_time|
----------- ---------- ------------------- -------------------
|100| 158932441|2021-01-02 13: 35: 57|2021-01-04 09:36:10|
| 100| 158932441|2021-01-14 19: 14:08|2021-01-04 09:36:10|
| 100| 158932441|2021-01-03 13: 33:52|2021-01-04 09:36:10|
| 100| 158932441| 2021-01-04 09:36: 10|2021-01-04 09:36:10|
101| 281838494|2020-05-07 13:35: 57|2020-05-07 13:35:57|
| 101| 281838494|2021-04-14 19: 14:08|202005-07 13:35:57|
----------- ---------- ------------------- -------------------
注意:在你的預期輸出中,你為 uj5u.com熱心網友回復: 這里是另一種方法。使用 uj5u.com熱心網友回復: 你可以在這里以如下方式使用window,但是如果一個組中只有一行,你會得到空值
標籤:CUSTOMER_ID == 101寫了2021-04-14 19:14:08,但它實際上是2020-05-07 13:35:57,因為它是在2020年。
collect_listimport pyspark.sql.function as F
from pyspark.sql import Window
sorted_order_times = Window.partitionBy("CUSTOMER_ID"/span>, "ADDRESS_ID"/span>)。 orderBy(F.col('ORDERED_TIME').desc()).rangeBetween(Window.unboundedPreceding, Windows.unboundedFollowing)
df2 = (
df
.withColumn("second_recent_order", (F.collect_list(F.col("ORDERED_TIME")).over(sorted_order_times)) [1]
)
df2.show()
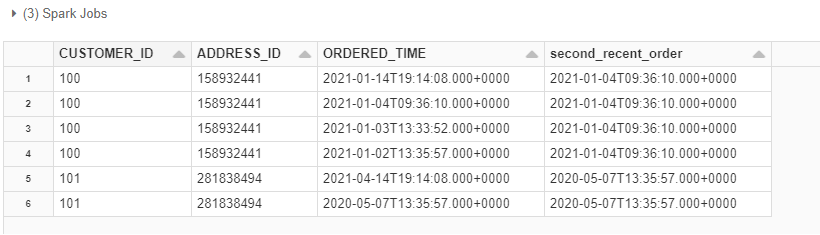
。
sorted_order_times = Window.partitionBy("CUSTOMER_ID", "ADDRESS_ID").orderBy(desc('ORDERED_TIME') ).rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing
df2 = df2.withColumn(
"second_recent_order",
collect_list("ORDERED_TIME").over(sorted_order_times) .getItem(1)
)