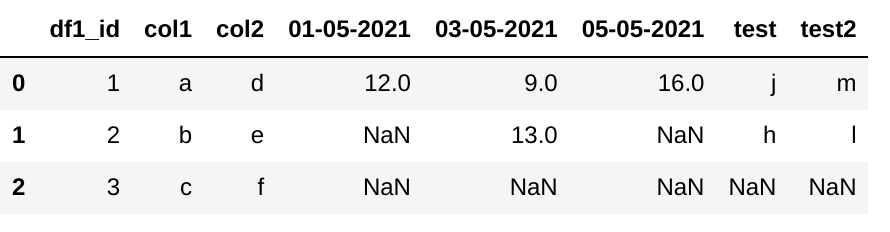
表1
df1 = pd. DataFrame({'df1_id':['1','2','3'],'col1': ["a"/span>,"b"/span>,"c"/span>],'col2'/span>: ["d"/span>,"e"/span>,"f"/span>]})
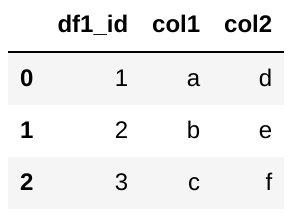
表2
df2 = pd. DataFrame({'df1_id': ['1','2','1','1'], 'date': ['01-05-2021','03-05-2021','05-05-2021','03-05-2021'],'資料'/span>。 [12,13,16,9],'test': ['g','h','j','i'],'test2': ['k','l','m','n']})
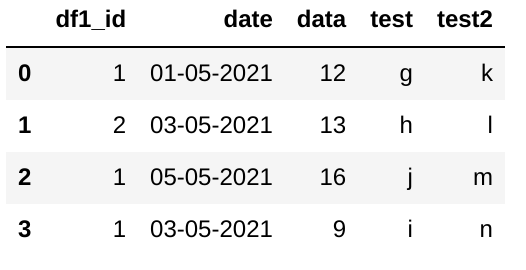
結果表

結果表
關于如何創建結果表的簡要說明: 我有兩個資料框架,我想根據一個 結果表的日期列將是第二個表的最小日期和最大日期之間的范圍 。
結果表中的日期列值將來自第二個表中的 同時,第二個表中的 我希望這很清楚。如果您對此有任何建議或幫助,我們將不勝感激。
我已經嘗試在第二個表上使用透視,然后試圖合并透視的第二個表 注意:我正試圖使用矢量化來解決這個問題,不想連續決議每一行 uj5u.com熱心網友回復: 你需要將 因此你得到的 uj5u.com熱心網友回復: 下面是問題的解決方案: 我首先將其進行分類。
我首先根據 然后我根據 然后我對 。
然后我用
然后我與 注意:我還沒有弄清楚如何獲得01-05-2021和05-05-2021之間的整個日期范圍,并將空值顯示為NaN。如果有人能提供幫助,請編輯答案
標籤:
df_id來合并它們。但是第二張表中的date列應該被轉置到結果表中。
data列。
test列將只取其結果表中的最新日期的值df1,但它不作業。我不知道如何為測驗的最新值只得到一條記錄。
pivot你的df2分成兩個獨立的表,因為我們需要data和test值,然后將兩個產生的pivot表與df1合并df1 = pd. DataFrame({'df1_id':['1','2','3'],'col1': ["a"/span>,"b"/span>,"c"/span>],'col2'/span>: ["d"/span>,"e"/span>,"f"/span>]})
df2 = pd. DataFrame({'df1_id': ['1','2','1','1'], 'date': ['01-05-2021','03-05-2021','03-05-2021','05-05-2021'],'資料'/span>。 [12,13,9,16],'test'。 ['g','h','i','j']})
test_piv = df2.pivot(index=['df1_id'],columns=['date'], values=['test'] )
data_piv = df2.pivot(index=['df1_id'],columns=['date'], values=['data'])
max_test = test_piv['test'].ffill(axis=1).iloc[:,-1].rename('test')
final = df1.merge(data_piv['data'],left_on=df1.df1_id, right_index=True, how='left')
final = final.merge(max_test,left_on=df1.df1_id, right_index=True, how='left')
final資料框架如下|| df1_id | col1 | col2 | 01-05-2021 | 03-05-2021 | 05-05-2021 | test
|---:|---------:|:-------|:-------|-------------:|-------------:|-------------:|:-------|
| 0 | 1 | a | d | 12 | 9 | 16 | j !
| 1 | 2 | b | e | nan | 13 | nan | h !
2 | 3 | c | f | nan | nan | nan | nan | n
df1_id和date對df2進行排序,以確保表項的順序。
df_id洗掉重復的資料,并選擇最后一行以確保我擁有test和test2的最新值。
df2進行透視,以獲得相應的date作為列,data作為其值df2_pivoted合并該表,以合并test和test2的最新值df1 合并,以獲得結果表df1 = pd. DataFrame({'df1_id':['1','2','3'],'col1': ["a"/span>,"b"/span>,"c"/span>],'col2'/span>: ["d"/span>,"e"/span>,"f"/span>]})
df2 = pd. DataFrame({'df1_id': ['1','2','1','1'], 'date': ['01-05-2021','03-05-2021','05-05-2021','03-05-2021'],'資料'/span>。 [12,13,16,9],'test': ['g','h','j','i'],'test2': ['k','l','m','n']})
df2=df2.sort_values(by=['df1_id','date'] )
df2_latest_vals = df2.drop_duplicates(subset=['df1_id'],keep='last')
df2_pivoted = df2.pivot_table(index=['df1_id'],columns=['date'], values=['data'] )
df2_pivoted = df2_pivoted.droplevel(0,axis=1) .reset_index()
df2_pivoted = pd.merge(df2_pivoted,df2_latest_vals, on='df1_id')
df2_pivoted = df2_pivoted.drop(columns=['date','data'] )
result = pd.merge(df1,df2_pivoted,on='df1_id', how='left')
結果