我正在嘗試使用 Scrapy 和 PyCharm 對房地產網站進行網路抓取,但失敗了。
預期結果:
- 抓取 1 個基本 URL (

當前的 Scrapy 代碼:這是我目前所擁有的。當我使用scrapy crawl unegui_apts 時,我似乎無法得到我想要的結果。我很失落。
# -*- coding: utf-8 -*- # Import library import scrapy from scrapy.crawler import CrawlerProcess from scrapy import Request # Create Spider class class UneguiApartments(scrapy.Spider): name = 'unegui_apts' allowed_domains = ['www.unegui.mn'] custom_settings = {'FEEDS': {'results1.csv': {'format': 'csv'}}} start_urls = [ 'https://www.unegui.mn/l-hdlh/l-hdlh-zarna/oron-suuts-zarna/1-r/,' 'https://www.unegui.mn/l-hdlh/l-hdlh-zarna/oron-suuts-zarna/2-r/' ] headers = { 'user-agent': "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36" } def parse(self, response): self.logger.debug('callback "parse": got response %r' % response) cards = response.xpath('//div[@]') for card in cards: name = card.xpath('.//meta[@itemprop="name"]/text()').extract_first() price = card.xpath('.//meta[@itemprop="price"]/text()').extract_first() city = card.xpath('.//meta[@itemprop="areaServed"]/text()').extract_first() date = card.xpath('.//*[@]/text()').extract_first().strip().split(', ')[0] request = Request(link, callback=self.parse_details, meta={'name': name, 'price': price, 'city': city, 'date': date}) yield request next_url = response.xpath('//li[@]/a/@href').get() if next_url: # go to next page until no more pages yield response.follow(next_url, callback=self.parse) # main driver if __name__ == "__main__": process = CrawlerProcess() process.crawl(UneguiApartments) process.start()uj5u.com熱心網友回復:
您的代碼有很多問題:
- 該
start_urls串列包含無效鏈接 - 您
user_agent在headers字典中定義了字串,但在產生requests時沒有使用它 - 您的 xpath 選擇器不正確
- 在
next_url不正確,因此不會產生下一個頁面的新要求
我已更新您的代碼以解決上述問題,如下所示:
import scrapy from scrapy.crawler import CrawlerProcess # Create Spider class class UneguiApartments(scrapy.Spider): name = 'unegui_apts' allowed_domains = ['www.unegui.mn'] custom_settings = {'FEEDS': {'results1.csv': {'format': 'csv'}}, 'USER_AGENT': "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36"} start_urls = [ 'https://www.unegui.mn/l-hdlh/l-hdlh-zarna/oron-suuts-zarna/' ] def parse(self, response): cards = response.xpath( '//li[contains(@class,"announcement-container")]') for card in cards: name = card.xpath(".//a[@itemprop='name']/@content").extract_first() price = card.xpath(".//*[@itemprop='price']/@content").extract_first() date = card.xpath("normalize-space(.//div[contains(@class,'announcement-block__date')]/text())").extract_first() city = card.xpath(".//*[@itemprop='areaServed']/@content").extract_first() yield {'name': name, 'price': price, 'city': city, 'date': date} next_url = response.xpath("//a[contains(@class,'red')]/parent::li/following-sibling::li/a/@href").extract_first() if next_url: # go to next page until no more pages yield response.follow(next_url, callback=self.parse) # main driver if __name__ == "__main__": process = CrawlerProcess() process.crawl(UneguiApartments) process.start()python <filename.py>由于您運行的是獨立腳本而不是完整的專案,因此您可以通過執行命令來運行上述蜘蛛程式。示例 csv 結果如下圖所示。您需要使用
pipelinesscrapyitem類清理資料。有關更多詳細資訊,請參閱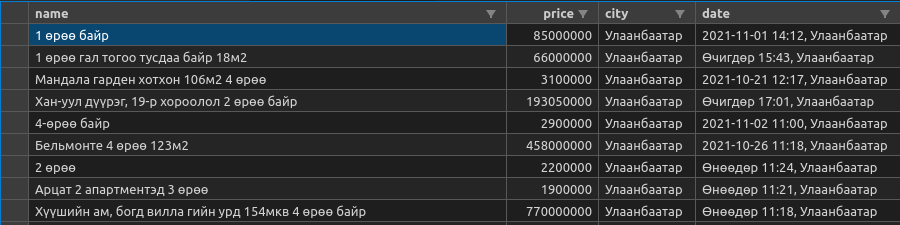
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/347302.html上一篇:檢查復選框時出現問題
- 該