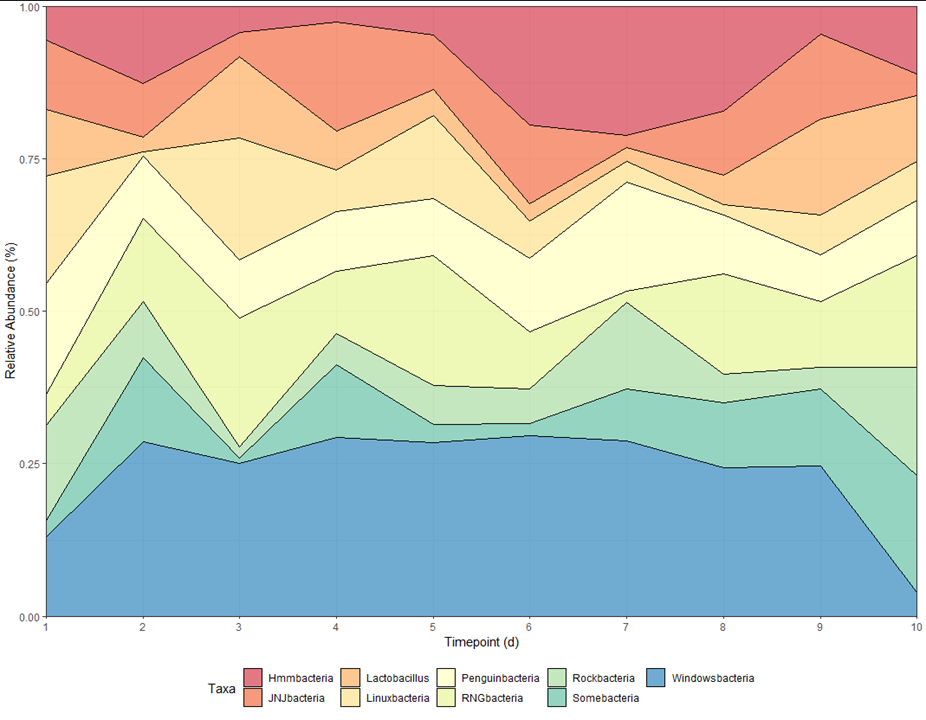
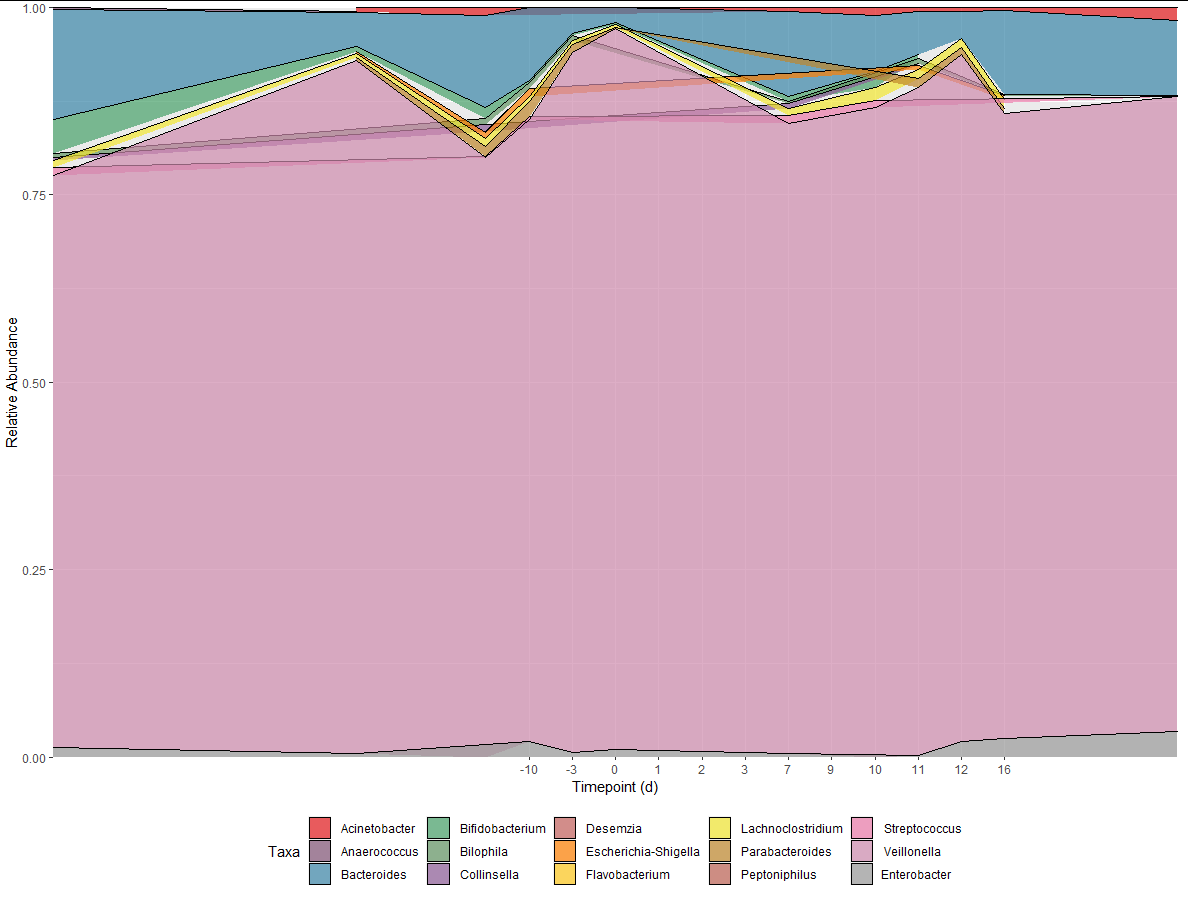
我正在嘗試創建一個比例堆積面積圖,如下所示在我的模擬資料中(圖 1)。當我嘗試使用真實資料執行此操作時,結果如圖 2 所示。
轉換成mock 和16S 之間的百分比后資料的類別都相同,如下所示:Timepoint - 整數,Taxa - 字符,n - 整數,百分比 - 數字。
我希望像模擬一樣在 16S 資料中對 x 軸進行分類和數字處理(對于兩個單獨的圖形),并整理重疊的線(例如,從美學角度來看,16S 的圖看起來像模擬資料)。
dput(S1_RA1[1:40,])
structure(list(Timepoint = c(-10L, -10L, -10L, -10L, -10L, -10L,
-10L, -10L, -10L, -3L, -3L, -3L, -3L, -3L, -3L, -3L, -3L, -3L,
-3L, -3L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L), Taxa = c(" Anaerococcus", " Bacteroides",
" Bifidobacterium", " Bilophila", " Collinsella", " Lachnoclostridium",
" Streptococcus", " Veillonella", "Enterobacter", " Acinetobacter",
" Anaerococcus", " Bacteroides", " Bifidobacterium", " Escherichia-Shigella",
" Flavobacterium", " Lachnoclostridium", " Parabacteroides",
" Peptoniphilus", " Veillonella", "Enterobacter", " Acinetobacter",
" Bacteroides", " Bifidobacterium", " Bilophila", " Collinsella",
" Desemzia", " Escherichia-Shigella", " Lachnoclostridium", " Parabacteroides",
" Streptococcus", " Veillonella", " Bacteroides", " Bifidobacterium",
" Bilophila", " Desemzia", " Escherichia-Shigella", " Lachnoclostridium",
" Parabacteroides", " Streptococcus", " Veillonella"), n = c(40L,
2188L, 665L, 84L, 55L, 131L, 153L, 11325L, 185L, 127L, 62L, 1123L,
172L, 63L, 2L, 118L, 100L, 9L, 23123L, 109L, 253L, 2658L, 348L,
163L, 204L, 27L, 163L, 245L, 290L, 41L, 17497L, 2325L, 50L, 197L,
13L, 255L, 152L, 478L, 92L, 19692L), percentage = c(0.00269796303790638,
0.147578578173479, 0.0448536355051936, 0.0056657223796034, 0.00370969917712127,
0.0088358289491434, 0.0103197086199919, 0.763860785107244, 0.012478079050317,
0.00507837492002559, 0.00247920665387076, 0.0449056301983365,
0.00687779910428663, 0.00251919385796545, 7.99744081893794e-05,
0.00471849008317338, 0.00399872040946897, 0.000359884836852207,
0.92462412028151, 0.00435860524632118, 0.0115583169628581, 0.121430855680936,
0.0158983964548403, 0.0074466627072959, 0.00931974964594088,
0.00123349627666865, 0.0074466627072959, 0.0111928365845859,
0.0132486637123669, 0.00187308693864498, 0.799351272328567, 0.0978823727529154,
0.00210499726350356, 0.00829368921820402, 0.000547299288510925,
0.0107354860438681, 0.00639919168105081, 0.020123773839094, 0.00387319496484655,
0.829032122258241)), row.names = c(NA, -40L), groups = structure(list(
Timepoint = c(-10L, -3L, 0L, 1L), .rows = structure(list(
1:9, 10:20, 21:31, 32:40), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), row.names = c(NA, -4L), class = c("tbl_df",
"tbl", "data.frame"), .drop = TRUE), class = c("grouped_df",
"tbl_df", "tbl", "data.frame"))
我嘗試了以下方法:
將 scale_x_discrete 設定為 scale_x_continuous
轉換 aes(x = as.factor(Timepoint)..
更改 scale_x_discrete 代碼中的限制/擴展引數
洗掉負時間點
Changing the Number column in the S1_RA2 file to match the number system in Table 1
My code for the 16S is as follows and is almost identical to the mock except for the colors:
library(ggplot2)
library(dplyr)
RA1 <- read.csv("RA1.csv", header=TRUE)
#Transform relative abundance from RA1.csv to percentages
S1_RA1 <- RA1 %>%
group_by(Timepoint, Taxa) %>%
summarise(n = sum(Relative.Abundance)) %>%
mutate (percentage = n / sum(n))
head(Shime1_RA2)
#Set color palette to be able to include 15 colors
nb.cols <- 16
getPalette <- colorRampPalette(brewer.pal(9, 'Set1'))(nb.cols)
#Revised code - The code below works courtesy of Gregor's comment
library(tidyr)
Shime1_RA2 <- Shime1_RA2 %>% ungroup %>%
complete(Timepoint, Taxa, fill = list(n = 0, percentage = 0))
ggplot(Shime1_RA2, aes(x = factor(Timepoint), y = percentage, fill = Taxa, group = Taxa))
geom_area(position = "fill", colour = "black", size = .5, alpha = .7)
scale_y_continuous(name="Relative Abundance", expand=c(0,0))
scale_x_discrete(name="Timepoint (d)", expand=c(0,0))
scale_fill_manual(values = getPalette)
theme(legend.position='bottom')
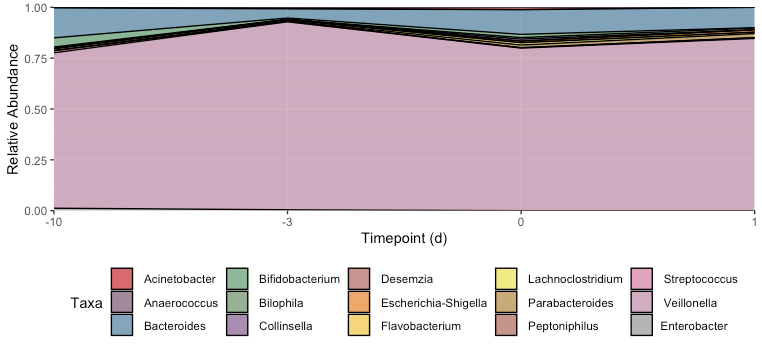
uj5u.com熱心網友回復:
我修復了三件事:
您希望對 x 尺度進行分類處理,因此我們需要
factor(Timepoint). (然后默認比例就可以了,所以我們洗掉你手動指定的limitsl)當我們使用離散的 x 軸比例尺時,我們必須明確指出
ggplot我們想要連接哪些點。我們通過添加group = Taxa美感來做到這一點。穿過其他多邊形中間的奇怪線條是因為您沒有在每個時間點對每個分類群進行觀察,因此當點連接時,它們可能會穿過中間時間點。用于
tidyr::complete用 0 填充缺失的觀察值。
library(tidyr)
S1_RA1 = S1_RA1 %>% ungroup %>%
complete(Timepoint, Taxa, fill = list(n = 0, percentage = 0))
ggplot(S1_RA1, aes(x = factor(Timepoint), y = percentage, fill = Taxa, group = Taxa))
geom_area(position = "fill", colour = "black", size = .5, alpha = .7)
scale_y_continuous(name="Relative Abundance", expand=c(0,0))
scale_x_discrete(
name="Timepoint (d)", expand=c(0,0)
)
scale_fill_manual(values = getPalette)
theme(legend.position='bottom')
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/348077.html