在這里,我嘗試使用 3 種方法添加 0 到 1e9 之間的所有數字:
- 普通順序執行(單執行緒)
- 創建多個行程以添加較小的部分(使用 fork)并在最后添加所有較小的部分,以及
- 創建多個執行緒以與第二種方法相同。
據我所知,執行緒創建速度很快,因此稱為輕量級行程。
但是在執行我的代碼時,我發現第二個方法(多行程)是最快的,其次是第一個方法(順序),然??后是第三個(多執行緒)。但我無法弄清楚為什么會這樣(可能是執行時間計算中的一些錯誤,或者我的系統中的某些內容有所不同,等等)。
這是我的代碼 C 代碼:
#include "stdlib.h"
#include "stdio.h"
#include "unistd.h"
#include "string.h"
#include "time.h"
#include "sys/wait.h"
#include "sys/types.h"
#include "sys/sysinfo.h"
#include "pthread.h"
#define min(a,b) (a < b ? a : b)
int n = 1e9 24; // 2, 4, 8 multiple
double show(clock_t s, clock_t e, int n, char *label){
double t = (double)(e - s)/(double)(CLOCKS_PER_SEC);
printf("=== N %d\tT %.6lf\tlabel\t%s === \n", n, t, label);
return t;
}
void init(){
clock_t start, end;
long long int sum = 0;
start = clock();
for(int i=0; i<n; i ) sum = i;
end = clock();
show(start, end, n, "Single thread");
printf("Sum %lld\n", sum);
}
long long eachPart(int a, int b){
long long s = 0;
for(int i=a; i<b; i ) s = i;
return s;
}
// multiple process with fork
void splitter(int a, int b, int fd[2], int n_cores){ // a,b are useless (ignore)
clock_t s, e;
s = clock();
int ncores = n_cores;
// printf("cores %d\n", ncores);
int each = (b - a)/ncores, cc = 0;
pid_t ff;
for(int i=0; i<n; i =each){
if((ff = fork()) == 0 ){
long long sum = eachPart(i, min(i each, n) );
// printf("%d->%d, %d - %d - %lld\n", i, i each, cc, getpid(), sum);
write(fd[1], &sum, sizeof(sum));
exit(0);
}
else if(ff > 0) cc ;
else printf("fork error\n");
}
int j = 0;
while(j < cc){
int res = wait(NULL);
// printf("finished r: %d\n", res);
j ;
}
long long ans = 0, temp;
while(cc--){
read(fd[0], &temp, sizeof(temp));
// printf("c : %d, t : %lld\n", cc, temp);
ans = temp;
}
e = clock();
show(s, e, n, "Multiple processess used");
printf("Sum %lld\tcores used %d\n", ans, ncores);
}
// multi threading used
typedef struct SS{
int s, e;
} SS;
int tfd[2];
void* subTask(void *p){
SS *t = (SS*)p;
long long *s = (long long*)malloc(sizeof(long long));
*s = 0;
for(int i=t->s; i<t->e; i ){
(*s) = (*s) i;
}
write(tfd[1], s, sizeof(long long));
return NULL;
}
void threadSplitter(int a, int b, int n_thread){ // a,b are useless (ignore)
clock_t sc, e;
sc = clock();
int nthread = n_thread;
pthread_t thread[nthread];
int each = n/nthread, cc = 0, s = 0;
for(int i=0; i<nthread; i ){
if(i == nthread - 1){
SS *t = (SS*)malloc(sizeof(SS));
t->s = s, t->e = n; // start and end point
if((pthread_create(&thread[i], NULL, &subTask, t))) printf("Thread failed\n");
s = n; // update start point
}
else {
SS *t = (SS*)malloc(sizeof(SS));
t->s = s, t->e = s each; // start and end point
if((pthread_create(&thread[i], NULL, &subTask, t))) printf("Thread failed\n");
s = each; // update start point
}
}
long long ans = 0, tmp;
// for(int i=0; i<nthread; i ){
// void *dd;
// pthread_join(thread[i], &dd);
// // printf("i : %d s : %lld\n", i, *((long long*)dd));
// ans = *((long long*)dd);
// }
int cnt = 0;
while(cnt < nthread){
read(tfd[0], &tmp, sizeof(tmp));
ans = tmp;
cnt = 1;
}
e = clock();
show(sc, e, n, "Multi Threading");
printf("Sum %lld\tThreads used %d\n", ans, nthread);
}
int main(int argc, char* argv[]){
init();
printf("argc : %d\n", argc);
// ncore - processes
int fds[2];
pipe(fds);
int cores = get_nprocs();
splitter(0, n, fds, cores);
for(int i=1; i<argc; i ){
cores = atoi(argv[i]);
splitter(0, n, fds, cores);
}
// nthread - calc
pipe(tfd);
threadSplitter(0, n, 16);
for(int i=1; i<argc; i ){
int threads = atoi(argv[i]);
threadSplitter(0, n, threads);
}
return 0;
}
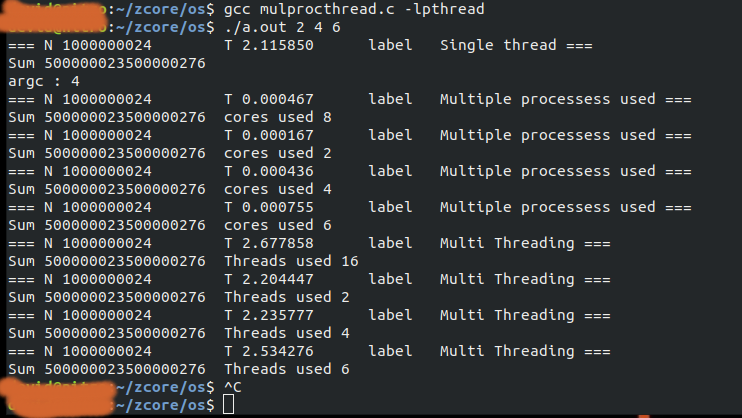
輸出結果:
=== N 1000000024 T 2.115850 label Single thread ===
Sum 500000023500000276
argc : 4
=== N 1000000024 T 0.000467 label Multiple processess used ===
Sum 500000023500000276 cores used 8
=== N 1000000024 T 0.000167 label Multiple processess used ===
Sum 500000023500000276 cores used 2
=== N 1000000024 T 0.000436 label Multiple processess used ===
Sum 500000023500000276 cores used 4
=== N 1000000024 T 0.000755 label Multiple processess used ===
Sum 500000023500000276 cores used 6
=== N 1000000024 T 2.677858 label Multi Threading ===
Sum 500000023500000276 Threads used 16
=== N 1000000024 T 2.204447 label Multi Threading ===
Sum 500000023500000276 Threads used 2
=== N 1000000024 T 2.235777 label Multi Threading ===
Sum 500000023500000276 Threads used 4
=== N 1000000024 T 2.534276 label Multi Threading ===
Sum 500000023500000276 Threads used 6
Also, I have used pipe to transport the results of sub tasks. In multi-threading I have also tried to use join thread and sequentially merge the results but the final result was similar around 2 sec execution time.
Output:
uj5u.com熱心網友回復:
TL;DR:您以錯誤的方式測量時間。使用clock_gettime(CLOCK_MONOTONIC, ...)代替clock()。
您正在使用 測量時間clock(),如手冊頁所述:
[...] 回傳程式使用的處理器時間的近似值。[...]回傳的值是 到目前為止使用的CPU時間 作為
clock_t
所使用的系統時鐘clock()衡量CPU時間,即呼叫行程在使用CPU時所花費的時間。行程使用的 CPU 時間是其所有執行緒使用的 CPU 時間的總和,但不是其子行程,因為它們是不同的行程。另請參閱:UNIX 中的掛鐘時間、用戶 CPU 時間和系統 CPU 時間具體是什么?
因此,在您的 3 個場景中會發生以下情況:
沒有并行性,順序代碼。運行該行程所花費的 CPU 時間幾乎是所有可以測量的,并且與實際花費的掛鐘時間非常相似。請注意,單執行緒程式的 CPU 時間始終低于或等于其掛鐘時間。
多個子行程。由于您正在創建子行程來代表主(父)行程執行實際作業,因此父行程將使用幾乎為零的 CPU 時間:它唯一需要做的就是一些系統呼叫來創建子行程,然后是一些系統呼叫等待他們退出。它的大部分時間都花在等待孩子的睡眠上,而不是在 CPU 上運行。子行程是在 CPU 上運行的行程,但您根本沒有測量它們的時間。因此,您最終的時間很短(1 毫秒)。你在這里基本上沒有測量任何東西。
多執行緒。由于您正在創建 N 個執行緒來完成作業,并且僅在主執行緒中占用 CPU 時間,因此您的行程的 CPU 時間將占執行緒的 CPU 時間總和。毫不奇怪,如果您進行完全相同的計算,每個執行緒花費的平均 CPU 時間為 T/NTHREADS,將它們相加將得到 T/NTHREADS * NTHREADS = T。實際上,您大致使用的是與第一個場景相同的 CPU 時間,只有一點點用于創建和管理執行緒的開銷。
所有這些都可以通過兩種方式解決:
- 在每個執行緒/行程中以正確的方式仔細考慮 CPU 時間,然后根據需要繼續對這些值求和或求平均值。
- 只需使用,或
clock_gettime之一測量掛鐘時間(即真實的人類時間)而不是 CPU 時間。有關更多資訊,請參閱手冊頁。CLOCK_REALTIMECLOCK_MONOTONICCLOCK_MONOTONIC_RAW
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/349086.html