我有以下資料框:
df = pd.DataFrame([['50030', '36 @ 3159 W/270, LWD[GR,RES,PWD] @ 4015', '3159'],
['50030', '36 @ 3159 W/270, LWD[GR,RES,PWD] @ 4015', '3994'],
['50030', '36 @ 3159 W/270, LWD[GR,RES,PWD] @ 4015', '5401'],
['50030', '26 @ 3994, LWD[GR,RES,PWD] @ 5430, 20 @ 5401', '3159'],
['50030', '26 @ 3994, LWD[GR,RES,PWD] @ 5430, 20 @ 5401', '3994'],
['50030', '26 @ 3994, LWD[GR,RES,PWD] @ 5430, 20 @ 5401', '5401']],
columns = ["WKEY", "Description", "DEPTH"])
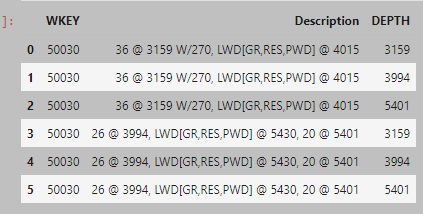
我想將 DEPTH 列中的值(它是一個字串值)與 Description 列中的字串僅在同一行中進行比較。一個名為“比較”的新列將根據它是否存在而具有是或否。
基于這篇文章: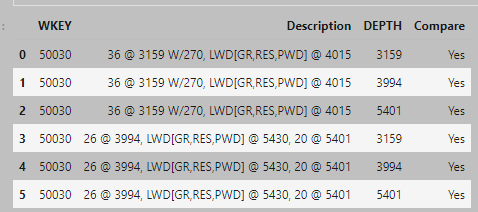
應該是是,不是,不是,不是,是,是。
最終計劃是洗掉在 DEPTH 列中沒有值的所有行,這些行也在同一行的 Description 列中的某處列出。
我覺得我離讓它作業只有一步之遙,所以任何方向都將不勝感激。
謝謝!
uj5u.com熱心網友回復:
在你的情況下
df['Compare'] = df.apply(lambda x: 'Yes' if x['DEPTH'] in x['Description'] else 'No',axis=1)
df
Out[133]:
WKEY Description DEPTH Compare
0 50030 36 @ 3159 W/270, LWD[GR,RES,PWD] @ 4015 3159 Yes
1 50030 36 @ 3159 W/270, LWD[GR,RES,PWD] @ 4015 3994 No
2 50030 36 @ 3159 W/270, LWD[GR,RES,PWD] @ 4015 5401 No
3 50030 26 @ 3994, LWD[GR,RES,PWD] @ 5430, 20 @ 5401 3159 No
4 50030 26 @ 3994, LWD[GR,RES,PWD] @ 5430, 20 @ 5401 3994 Yes
5 50030 26 @ 3994, LWD[GR,RES,PWD] @ 5430, 20 @ 5401 5401 Yes
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/360265.html
上一篇:創建從另一個派生的新資料框列