我想創建 44 個資料框列TAZ_1720,使每一列都shift(-1)屬于上一列。
我該怎么做而不是寫 44 次?
df['m1']=df['TAZ_1270'].shift(-1)
df['m2']=df['m1'].shift(-1)
df['m3']=df['m2'].shift(-1)
uj5u.com熱心網友回復:
使用DataFrame.assign帶有字典理解。
這是一個帶有 4 個班次的最小示例:
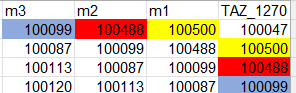
df = pd.DataFrame({'TAZ_1270': [100047, 100500, 100488, 100099]})
# TAZ_1270
# 0 100047
# 1 100500
# 2 100488
# 3 100099
df = df.assign(**{f'm{i}': df['TAZ_1270'].shift(-i) for i in range(1, 5)})
# TAZ_1270 m1 m2 m3 m4
# 0 100047 100500.0 100488.0 100099.0 NaN
# 1 100500 100488.0 100099.0 NaN NaN
# 2 100488 100099.0 NaN NaN NaN
# 3 100099 NaN NaN NaN NaN
回復:評論中的問題
為什么使用
**?
DataFrame.assign通常接受格式df.assign(col1=foo, col2=bar, ...)。當我們**在函式呼叫中使用dict 時,它會自動將 dict 的'col1': foo, 'col2': bar, ...對解包為col1=foo, col2=bar, ...引數。
為什么使用
f?
這是f-string語法(在 python 3.6 中引入)。f'm{i}'只是一個更簡潔的版本'm' str(i)。
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/360282.html