現在我有一個像 '7M' 這樣的資料框作為一個字串,其中 M 是百萬,我想把它改成 7000000 這是從資料框看
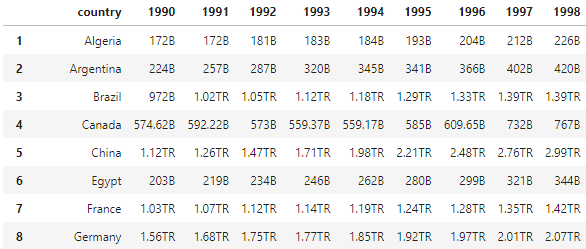
我試圖制作一個函式來將數字與字母分開并將字母更改為數字并且它起作用了
def num_repair(x):
if 'B' in x:
l = 10**9
x = x[:-1]
x = pd.to_numeric(x)
x = x * l
elif 'TR' in x:
l = 10**12
x =x[:-2]
x = pd.to_numeric(x)
x = x * l
elif 'M' in x:
l = 10**6
x = x[:-1]
x = pd.to_numeric(x)
x = x * l
return(x)
當我嘗試將它應用于資料框時,它沒有給我任何幫助?
uj5u.com熱心網友回復:
特爾;博士:
你要找的是 .applymap()
細節:
您的方法實際上寫得很好,可以按.apply()原樣用于pandas.Series物件,但我假設如果您遇到問題,那是因為您可能將它用于 a pandas.DataFrame, 針對多個列。在這種情況下,傳遞給的引數num_repair實際上是 type pandas.Series,這num_repair并不是真正要支持的。我只能假設,因為num_repair沒有給出使用的代碼。考慮添加它以確保問題的完整性。
如果是這樣,您可以按如下方式使用它:
df = pd.DataFrame([
['1M', '1B', '1TR'],
['22M', '22B', '22TR'],
], columns=[1990, 1991, 1992])
df.applymap(num_repair)
輸出:
1990 1991 1992
0 1000000 1000000000 1000000000000
1 22000000 22000000000 22000000000000
邊注
如果要將其應用于除國家B/地區以外的所有列,因為名稱可能包含TR// M- 您可以執行以下操作:
df = pd.DataFrame([
['countryM', '1M', '1B', '1TR'],
['countryB', '22M', '22B', '22TR'],
], columns=['country', 1990, 1991, 1992])
df.loc[:, df.columns.drop('country')] = df.loc[:, df.columns.drop('country')].applymap(num_repair)
df
輸出:
country 1990 1991 1992
0 countryM 1000000 1000000000 1000000000000
1 countryB 22000000 22000000000 22000000000000
uj5u.com熱心網友回復:
在我的玩具示例上作業正常:
>>> df = pd.DataFrame({'a': ['32M', '13B', '33TR']})
>>> df['a'].apply(num_repair)
0 32000000
1 13000000000
2 33000000000000
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/360301.html