我有一個用于 ML 分類器的 CSV 資料集。它有 2 列,如下所示:

但是這個資料集非常臟,所以我決定用 Excel 打開它,洗掉“臟”字,并將它保存為一個新的 CSV 檔案并在它上面訓練我的 ML 分類器。
但是在我將它保存在 Excel 中之后(使用,分隔符并嘗試過, UTF-8),并且在嘗試pd.read_csv它時,它給了我這個錯誤:
Error tokenizing data. C error: Expected 3 fields in line 4, saw 5
然后我嘗試使用sep=';'with read_csv,它起作用了,但現在所有俄語字符都被替換為奇怪的符號:
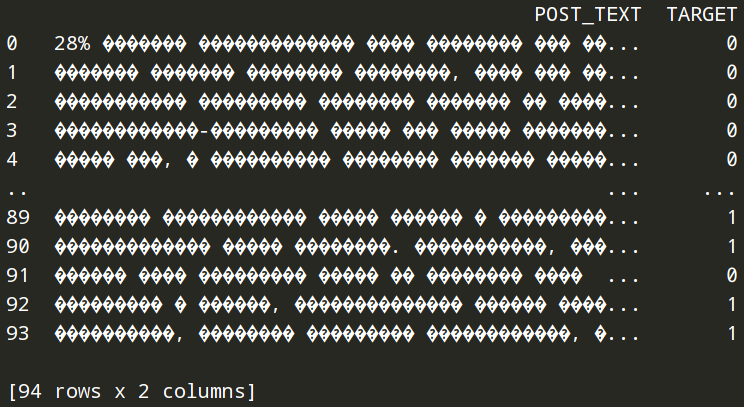
有人可以解釋一下如何修復俄語字符中的“問題”符號嗎?encoding='UTF-8'給出這個錯誤:
'utf-8' codec can't decode byte 0xe6 in position 22: invalid continuation byte
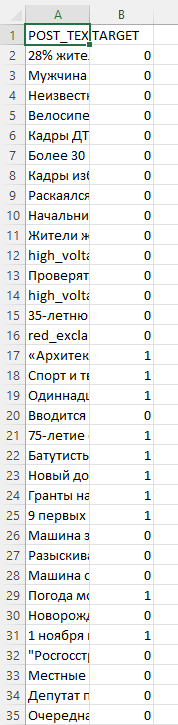
這是第一個檔案的樣子(未修改的 Excel.csv檔案):

當我打開第二個檔案(修改)時:
uj5u.com熱心網友回復:
嘗試使用ptcp154或kz1048編碼打開檔案。他們似乎作業。
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/362513.html