我有一個包含多個 ID 和多個變數的時間序列資料集,每個變數有 3 個時間序列條目——“基線”、“3 個月”、“6 個月”。資料框的結構是這樣的,df =
import pandas as pd
data = {'Patient ID': [11111, 11111, 11111, 11111, 22222, 22222, 22222, 22222, 33333, 33333, 33333, 33333, 44444, 44444, 44444, 44444, 55555, 55555, 55555, 55555],
'Lab Attribute': ['% Saturation- Iron', 'ALK PHOS', 'ALT(SGPT)', 'AST (SGOT)', '% Saturation- Iron', 'ALK PHOS', 'ALT(SGPT)', 'AST (SGOT)', '% Saturation- Iron', 'ALK PHOS', 'ALT(SGPT)', 'AST (SGOT)', '% Saturation- Iron', 'ALK PHOS', 'ALT(SGPT)', 'AST (SGOT)', '% Saturation- Iron', 'ALK PHOS', 'ALT(SGPT)', 'AST (SGOT)'],
'Baseline': [46.0, 94.0, 21.0, 18.0, 46.0, 94.0, 21.0, 18.0, 46.0, 94.0, 21.0, 18.0, 46.0, 94.0, 21.0, 18.0, 46.0, 94.0, 21.0, 18.0],
'3 Month': [23.0, 82.0, 13.0, 17.0, 23.0, 82.0, 13.0, 17.0, 23.0, 82.0, 13.0, 17.0, 23.0, 82.0, 13.0, 17.0, 23.0, 82.0, 13.0, 17.0],
'6 Month': [34.0, 65.0, 10.0, 14.0, 34.0, 65.0, 10.0, 14.0, 34.0, 65.0, 10.0, 14.0, 34.0, 65.0, 10.0, 14.0, 34.0, 65.0, 10.0, 14.0]}
df = pd.DataFrame(data)
Patient ID Lab Attribute Baseline 3 Month 6 Month
0 11111 % Saturation- Iron 46.0 23.0 34.0
1 11111 ALK PHOS 94.0 82.0 65.0
2 11111 ALT(SGPT) 21.0 13.0 10.0
3 11111 AST (SGOT) 18.0 17.0 14.0
4 22222 % Saturation- Iron 46.0 23.0 34.0
5 22222 ALK PHOS 94.0 82.0 65.0
6 22222 ALT(SGPT) 21.0 13.0 10.0
7 22222 AST (SGOT) 18.0 17.0 14.0
8 33333 % Saturation- Iron 46.0 23.0 34.0
9 33333 ALK PHOS 94.0 82.0 65.0
10 33333 ALT(SGPT) 21.0 13.0 10.0
11 33333 AST (SGOT) 18.0 17.0 14.0
12 44444 % Saturation- Iron 46.0 23.0 34.0
13 44444 ALK PHOS 94.0 82.0 65.0
14 44444 ALT(SGPT) 21.0 13.0 10.0
15 44444 AST (SGOT) 18.0 17.0 14.0
16 55555 % Saturation- Iron 46.0 23.0 34.0
17 55555 ALK PHOS 94.0 82.0 65.0
18 55555 ALT(SGPT) 21.0 13.0 10.0
19 55555 AST (SGOT) 18.0 17.0 14.0
我想要做的是按 ID 和實驗室屬性分組并創建每個“實驗室屬性”的圖 - % Saturation- Iron、ALK PHOS 等,其中將包括所有患者 ID 的時間序列。
因此,根據示例資料,將有 4 個圖 - % 飽和度 - 鐵、ALK PHOS 等,每個圖將包含 5 個軌跡(每個 ID 1 個)。
我嘗試根據本文使用 groupby -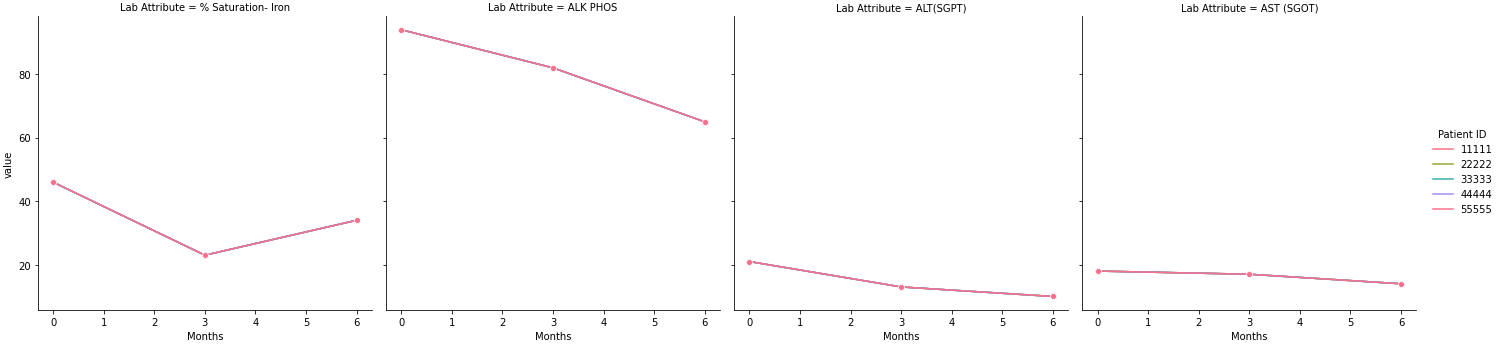
- 使用
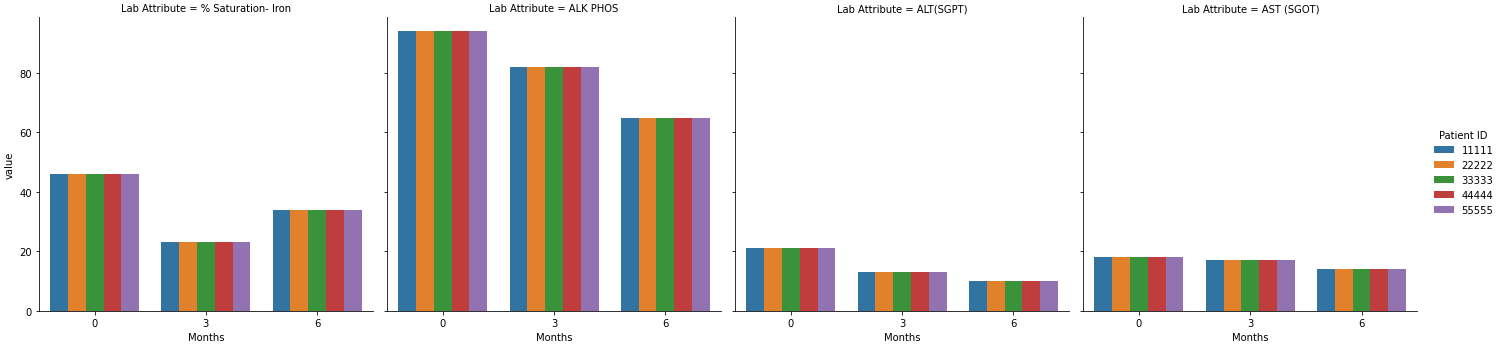
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/362635.html標籤:Python 熊猫 matplotlib 时间序列 海生