我有一個二維熊貓資料框,它的索引值為“1, 2, 'NaN', 'NaN', 'NaN', 'NaN'” 和資料 [10, 20, 30, 40, 50 , 60 ]。現在我想構建一個維度為 (3,2) 的 numpy 陣列。在陣列第一維的第一個條目中,應分配資料幀的前兩個值。在第一個維度的第二個條目中,應分配資料幀的第三個和第四個值,依此類推。
所以實際上新陣列應該是這樣的
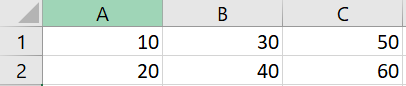
我使用以下代碼進行了嘗試,但沒有奏效,因為我收到了“KeyError: 0”
import pandas as pd
import numpy as np
d = {'col1': [1, 2, 'NaN', 'NaN', 'NaN', 'NaN'], 'col2': [10, 20, 30, 40, 50 , 60]}
df1 = pd.DataFrame(data=d)
df1 = df1.set_index('col1')
firstDimensionOfTheArray = 3
secondDimensionOfTheArray = 2
array = np.zeros((firstDimensionOfTheArray, secondDimensionOfTheArray))
for i in range (0, firstDimensionOfTheArray):
for j in range (0, secondDimensionOfTheArray):
array [i, j] = df1 ['col2'] [i * secondDimensionOfTheArray j]
你有什么想法,怎么做?
uj5u.com熱心網友回復:
要構建 numpy 陣列,請使用to_numpy和reshape:
df1['col2'].to_numpy().reshape((2,3), order='F')
輸出:
array([[10, 30, 50],
[20, 40, 60]])
現在,要創建一個新的資料框,請將上面的內容包裝在一個 DataFrame 建構式中:
import string
pd.DataFrame(df1['col2'].to_numpy().reshape((2,3), order='F'),
# the two lines below are only needed if you want
# the same indexes as in your image
index=list(df1.index[:2]),
columns=list(string.ascii_uppercase[:3])
)
輸出:
A B C
1 10 30 50
2 20 40 60
uj5u.com熱心網友回復:
使用SO answer,可以通過添加iloc以下內容來解決您撰寫的代碼的問題:
array[i, j] = df1['col2'].iloc[i * secondDimensionOfTheArray j]
或使用iat代替iloc. 該解決方案將為您的示例獲得結果:
[[10. 20.]
[30. 40.]
[50. 60.]]
然后您只需轉置即可獲得所需的結果array:
array = array.T
輸出:
[[10. 30. 50.]
[20. 40. 60.]]
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/366593.html
上一篇:提高雙回圈的時間效率